I’m a returning TW user after a decade long hiatus (and being a pretty active user form 2008 to 2010). In the end of 2020 and all 2021 I had the pleasure of reencountering with this tool and community. Thanks for keeping both vibrant and evolving.
I have been building TiddlyWikiPharo, a tool that models TW inside Pharo and Glamorous Toolkit (GT) computing environments. It provides a way to build, visualize and navigate tiddlers, so TW can be our “(web) publishing environment” and GT/Pharo can be our “(desktop) computing environment” in the Grafoscopio community.
Here, for example, you can see and screenshot of a TW used for our TTRPG group, as detailed in the conversation with @JanJohere:
TW and Pharo/GT share the fact of being live coding self-referential meta-systems, that can be changed live, while the system is running and inside the system itself: when you want to change TW, you launch it and use a uniform concept across all the system (the “tiddler”) to enrich/change it; when you want to change GT/Pharo you launch it and use the the uniform concept of “object” in the same way. I’m trying to bridge both experiences/environments. Part of such bridging is that graphics made on GT could be exported on Echarts. Both are malleable systems with rich customizing experiences and we, at the Grafoscopio community are building a critical code/data literacy curriculum that starts in TW and bridge it with GT and back. Our curriculum uses TW’s Projectify for project based learning and for what we have called apprentice notebooks. Facilitators and learners use the same infrastructure and tools (TW + Fossil SCM + GT), to build a peer to peer learning environment empowered by what I have called pocket infrastructures. By simplifying infrastructure we amplify/diversify participation in learning and civic endeavors.
I’m now on vacation (that’s why I had finally the time to connect back with the TW community and I hope to remain so), so code will be slow. But hopefully some projects this year will make the bridge more explicit. I’ll keep you posted.
We could arrange one. My spoken English is not pretty fluent, but I think that I can make myself clear. TiddlyWikiPharo is pretty basic right now, but we could explore it and extend it in the same session (fluency of the tools could compensate my lack of it in English ).
I could showcase how are our current workflows mixing both tools and maybe extend them a little bit.
First time I’ve heard of Pharo and I must say this looks very interesting indeed ! I understand that Pharo is a programming language but I have trouble to understand what can be done with it, do you know of some examples showcasing its uses ? I found this link : Pharo - success
Is that right to say that it is a development environment with its own language that can be used to create apps with the ability to be modified on the fly ?
Thanks for your interest in Pharo (as a member of the Pharo community I really appreciate it). Pharo comes from a long tradition and acknowledges Smalltalk as its “spiritual ancestor”. That being said they (Pharo and GT) don’t try to be compatible with Smalltalk, but share a vision of a continuous computing environment totally modifiable by the person who uses it (but the user/developer divide doesn’t make much sense over there). So your intuition is close to what Pharo is.
As a computer environment, more that a programming language, Pharo also blurs other distinctions, like the one between operative system, programming language, Integrated Development Environment, Application and Document. Today’s vision of computing is inherited from the Unix tradition, as it was the one that won the war for imagination and practices of computing in the seventies. But other (in my opinion) more compelling visions are still with us evolving in the margins: The Dynabook one, in the form of Pharo, GT, Cuis and several variants, and the Symbolic machines, in the form of Emacs, OrgMode and Lisp variants (Clojure, Racket and so on). Of course, today we live in a pretty diverse world without a single vision of computer (encouraged by Unix) with pretty strong frontiers and discontinuities between systems and those who can and can not modify them. That’s why systems like TW and Pharo/GT are so compelling (and bridging them so interesting), as they provide us an empowering unified toolkit for understanding, traversing and connecting the diversity.
You can found more about the Dynabook and those competing visions of informatics and computing in Tracing the Dynabook.
That’s cool. … I came across Glamorous Toolkit some time ago and had a look at the video on the landing page. … and all the tutorial videos I could find. … I downloaded the environment and did try to “code” along …
It seems GT is as “mindblowing” as TiddlyWiki in a slightly different way. In GT everything is an “object” in TW everything is a “tiddler” …
I didn’t want to run TW inside GT. I was more interested in analysing the source code structure and use GT as an “hackable” editor for TW code. …
The main problem for me was, that the whole GT UX philosophy is different to what I’m used to. And while I do have a relatively beefy PC the whole thing feels unresponsive.
Please try GT again. My experience was similar to yours regarding performance, but GT has made visible improvements on responsiveness. The philosophy of panels to deep into objects (based on Miller columns) can be pretty fluent once you get used to it. I used it, in a previous tool I build for data narratives and storytelling called Grafoscopio (liked previously). GT improves a lot on the user/developer experience (UX/DX) for data narratives (and while I would like an improvement UX/DX in outlining like Leo Editor or OrgMode, it provides a pretty moldable environment to build it).
My interest in the GT ⇆ TW bridge is similar to yours. I want GT to allow me to visualize and edit tiddlers in a hackeable way. TiddlyWikiPharo has a Tiddler object and a TiddlyWiki object and populates them from the JSON exportation of the tiddlers from TW. Once inside GT, I’m able to visualize and manipulate them, despite not knowing JavaScript and TW internals and I export the Tiddlers back in JSON to be imported in TW.
At some point, I would like to have a more seamless integration via some Pharo TWServer (that would be inspired by this simple TW Ruby server). For the moment importation and exportation happens manually and persistence is done via Timimi. If I had some kind of plugin that saves the tiddlers.json file automatically when the HTML file is saved, that would improve the flow (but I imagine that I will need the server anyway).
Once my vacations are over, I could made a demo to introduce you, @JanJo and anyone interested in TiddlyWikiPharo and how and why I bridge this two moldable tools. Surely we can arrange the times and get some people in both communities attending (I’m at UTC-5).
The new store is right “above” the “old” <div id="storeArea", which should be empty.
There can be several <script class="tiddlywiki-tiddler-store" type="application/json"> elements/stores. So if you are sure you only add new tiddlers it should be simple to extend the tiddler store.
The only thing you need to do, is to escape < to < in every “value” string. Then you should be good to directly modify the tiddler store.
Thanks @Offray it’s always good to see what you’re doing (I appreciate your tweets too). Pharo is wonderful, one of the relatively few beacons of hope that software can explore new territory and doesn’t necessarily converge on a monoculture.
As you note, thrilling opportunities can emerge when two orthogonal ecosystems are joined together. Doing so effectively relies on people who are steeped in both of the philosophies and communities, which turns out to be relatively rare.
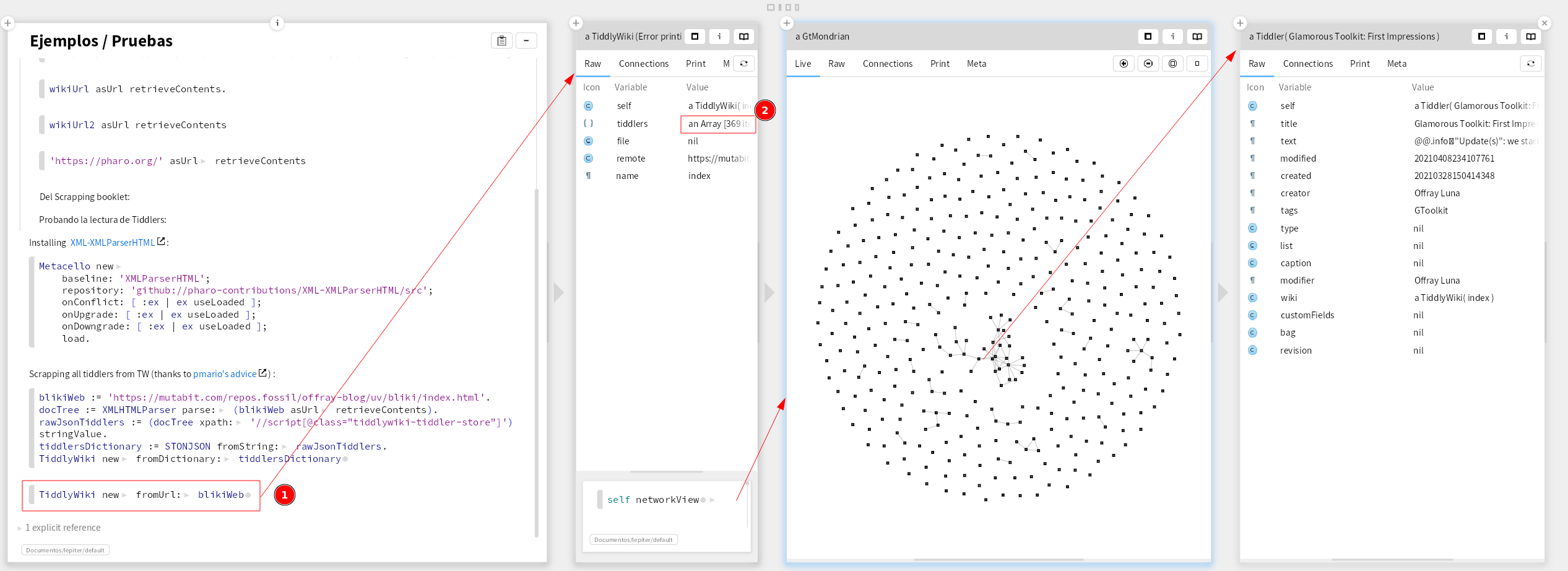
Wow! This is pretty cool! I can now in a short 4 lines script read the contents of any TW HML file and get its representation inside TiddlyWikiPharo (see screnshot below). Once I have this as part of the TWPharo DSL (Domain Specific Language) it would be even more fluent. Also this is the first time I can get a complete representation of the tiddlers, beyond what is exported by TW’s UI. Thanks!
I also notice that, running something like document.getElementsByClassName('tiddlywiki-tiddler-store') in the JavaScript browser console, gave me a starting point to get the same content and I wonder if there is some widget/plugin that allows to export the tiddlers-store as tiddlers.json file in the same folder where the html file is located (or in a configurable location) and if that doesn’t exist, how can I build it. This would allow a similar functionality to TiddlyHost where you can use https://mywiki.tiddlyhost.com/tiddlers.json to get and updated json representation of the wikis tiddlers and I could avoid scrapping the whole HTML file.
In any case, having acces to the JSON files opens a lot of hackeability and interoperability to TW from several programming environments/languages beyond JavaScript (as this 4 lines showcases) and I hope to see more advances like the ones in 5.2.x
I think @pmario mentioned there could be more than one store, so take care to walk the entire collection.
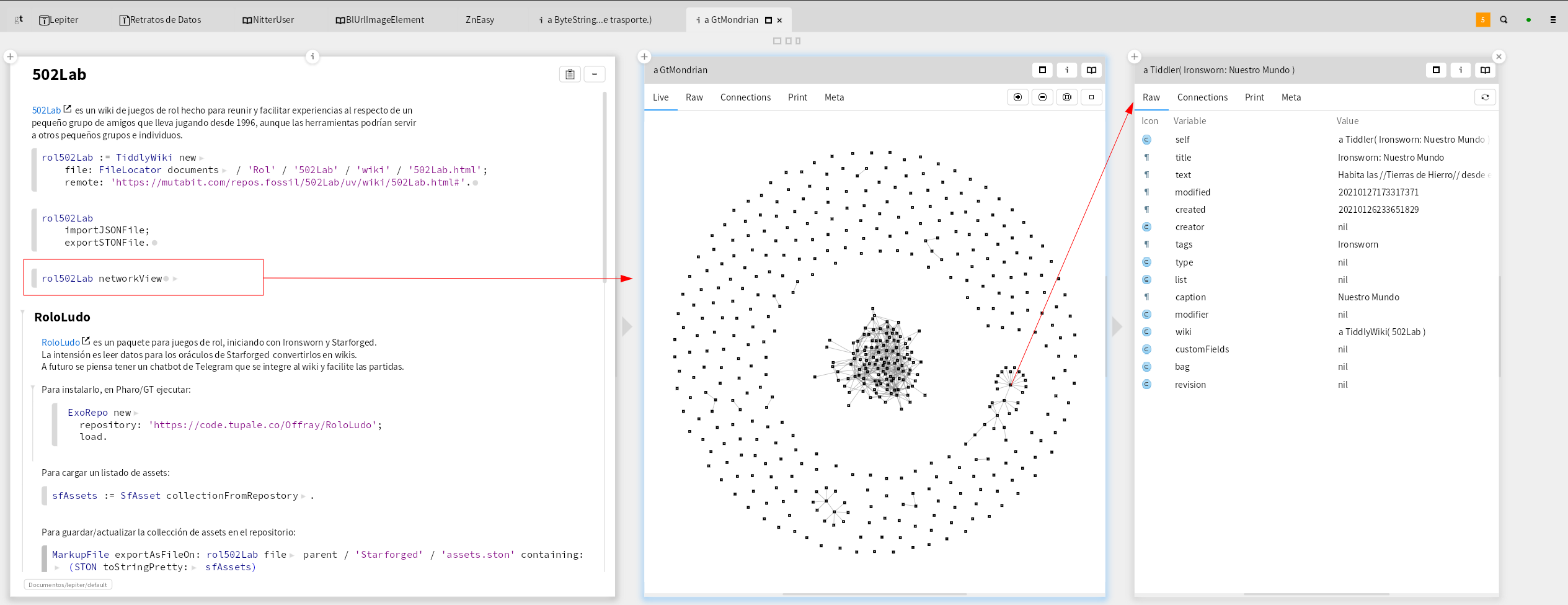
It seems that the complete collection is properly collected. In fact, this is the most complete picture I have had so far for my bliki, now with a one liner, TiddlyWiki new fromUrl: blikiUrl, (1) in the picture below providing 369 Tiddlers (2), including system tiddlers – one liners become usual in Pharo/GT as you collect the common behavior in the DSL.
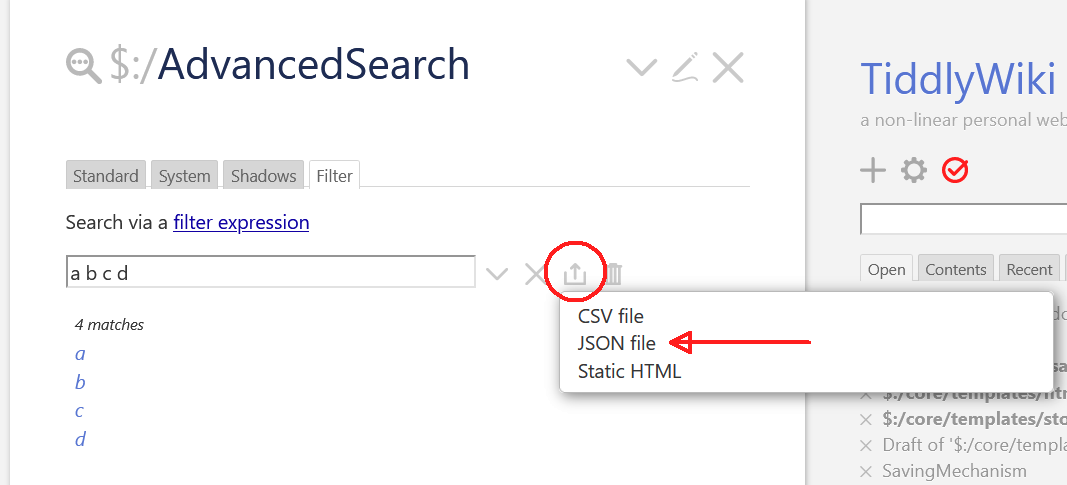
TW already has an export as JSON button in eg: The AdvancedSearch : Filter tab. In my image it would download 4 tiddlers into a tiddlers.json file to the browser download directory. …
Browser addOns can be used to lift this restriction. .. BUT anyway:
A similar mechanism could be used to export all “user created tiddlers” into an eg: 2022-01-11-T14-56-42-user-store.json file.
“user created tiddlers” could be defined by a filter stored in a $:/config/xyz tiddler.
The export mechanism usually is triggered by user interaction with a button, because creating a new json-store with every tiddler save would create an infinite number of files. Which imo doesn’t make much sense.
I personally would create a plugin that hooks into the tiddler-save function and checks if a tiddler named eg: commit-message has been changed. → changing that tiddler would then trigger the whole JSON saving mechanism… IMO this would give me much better control. So I could be sure that the JSON actually contains content I want to keep.
hihi, … You are thinking about an “automatic” bundle saver … I like it.
The commit- or milestone-message idea came from my “file-backups” browser addOn. I want to be able to make “out of order” backups … But that may probably be discussed in a different thread.
Thanks. I use the manual mechanism you depicted to export my tiddlers.json file on several wikis. But having to run it for wikis in different folders becomes tiresome. I think I will use my HTML Pharo scrapper for now. It takes a little bit of time, as it’s reading the complete file, despite being interested in only the JSON store, but saves manual work.
I like the way Timimi Hanoi’s Tower backup works with several rotating backups that give the user enough room to recover from mistakes (as I have done myself) without using a lot of extra space. Something similar for the tiddlers.json file would keep backups manageable. For more detailed backups and “time travel” across backups I combine TiddlyWiki with Fossil and STON, which gives me a pretty small, self contained and diff friendly approach (more details below).
This second part for automatizing JSON exportation seems pretty interesting. I don’t know JavaScript to build it myself, but hopefully your ideas and this conversation will inspire someone to build it and/or to make and advances in that front.
As said, having the possibility to access the JSON tiddlers serialization opens a lot of possibilities. For example, I export the tiddlers, from Pharo, as a STON file (Smalltalk’s JSON inspired serializing format), and commit the HTML and tiddlers.json as unversioned files to Fossil and the STON file as a versioned one. This provide us in the Grafoscopio community a pretty slim and interactive workflow with a small footprint: just 3 mb for the Fossil binary, including a web server for wiki publishing and admin tasks, near to 4 mb for the html wiki itself and a hundred of kb for the JSON and STON representations. This kind of mixture of small extensible infrastructures gives me the “best of all worlds” ™:
“End user” Extensible Single Page Application (xSPA) thanks to TW.
Web publishing and distributed storage thanks to Fossil.
Interoperability with external tools and environments, like Pharo, thanks to JSON.
Live coding programming beyond the browser thanks to Pharo/GT.
Diff friendly serialization with support for semantic breaks (which helps me a lot with writing, instead of line breaks with each paragraphs).
All this is possible thanks to the bridge that JSON allows. So yes, hopefully someone will improve on such JSON exportation to make the process more fluent. Meanwhile, I will share advances on the workflow I’m building with the new store mechanism.
But from time to time I would like to have an additional “milestone - backup” with some extra info what’s going on. .. So the tiddler-watching mechanism came into mind. …
There could be a simple “save milestone” button, which asks for a commit-message. But I thought it would be nice to trigger different export bundles watching multiple “commit-tiddlers” and trigger the save automatically. …
 ).
).