Hey all, I posted a while back in ChatGPT for TiddlyWiki to suggest some fixes and improvements - - I have continued to play around with expanding its capabilities and I’ve reached the point where it feels like posting a separate plugin would be appropriate and useful
$__plugins_NoteStreams_Expanded-Chat-GPT.json (46.2 KB)
Please note, this is my first time packaging and releasing a plugin - - I’ve likely missed steps and may not have done enough to acknowledge the original plugins creator (@Sttot) and/or quite a lot of other things, though I have tested this on a blank Wiki and it works. Most of my experience with Tiddlywiki and javascript more generally has come from kit-bashing other people’s projects. I have recently decided to begin repackaging some of the (many) customized versions of plugins that I use, but will need some time to untangle the hairs and perform testing.
Please let me know if there’s anything inappropriate about sharing this plugin or the format of this post and I will attempt to correct.
Also, I value @linonetwo for pointing out in the original ChatGPT post that the new version of TW has a chatbot plugin under development which also has the (exciting!) ability to use local models - - as far as I can tell, that version is currently (and maybe even only intended) to be a chat bot.
That is only one of the features of this plugin, however. An AI agent within Tiddlywiki has been a long time dream for me, and I find that a chatbot, while cool, does not do quite enough to justify itself.
Here are some of the important features of this plugin:
- Enhanced Memory: The agent can remember 5 previous messages by default, but this can be adjusted in the widget settings.
- Reference Tiddler: This version creates a reference tiddler to store content deemed important about the user, enhancing long-term memory and personalization.
- Default Model: Uses gpt-4o-mini by default, which can be changed in the widget however please note that this widget uses multiple API calls at its own discretion in order to complete a request, each one of these costing money
That said, even though I have been extensively testing using both simple and complex prompts over the last several days, the most I’ve paid on any given day, using this as the default model, was $0.60 and even then I was prompting, modifying the code, and prompting again. - Contextual Awareness: The system prompt provides context for the agent, including its TiddlyWiki environment and its capabilities to reference and modify tiddlers.
- Extended Capabilities: The AI assistant can interact with TiddlyWiki in various ways, including:
- Retrieving tiddler titles and content
- Searching tiddlers by content, tags, or custom fields
- Adding, retrieving, and revising notes about the user
- Accessing conversation history
- Creating and modifying tiddlers
- Streams Plugin Compatibility: By default, this plugin is compatible with the Streams plugin. The agent will refer to the content within a tiddler’s stream-list field in addition to the content of the tiddler itself, providing a more comprehensive context.
- Specific Tiddler Reference: Users can reference a specific tiddler as context for the conversation by using the tiddlerTitle parameter in the widget.
- Access to the Current Time: As in, the agent can check the date and report info about tasks that may be overdue, for example, or list tiddlers that were created on a particular day. It can also be used to create timestamps which can be used in text, fields, tags, or titles.
I have not attempted to play with the new versions chatbot yet – though I am incredibly enthusiastic about the changes in the new version, I have not done any work with SQLite as of yet and have no idea if this version I’m releasing would be easily converted to utilize the SQLite database or not. I can report that I developed and tested on a MultiWikiServer instance, though, and it seems to do data retrieval well. That said, it is compatible with both the prerelease and the current version, at the very least.
Alright, now that acknowledgements are over, let’s look at some examples so we can talk about the great advantages that can be leveraged by using ML within a TW Environment.
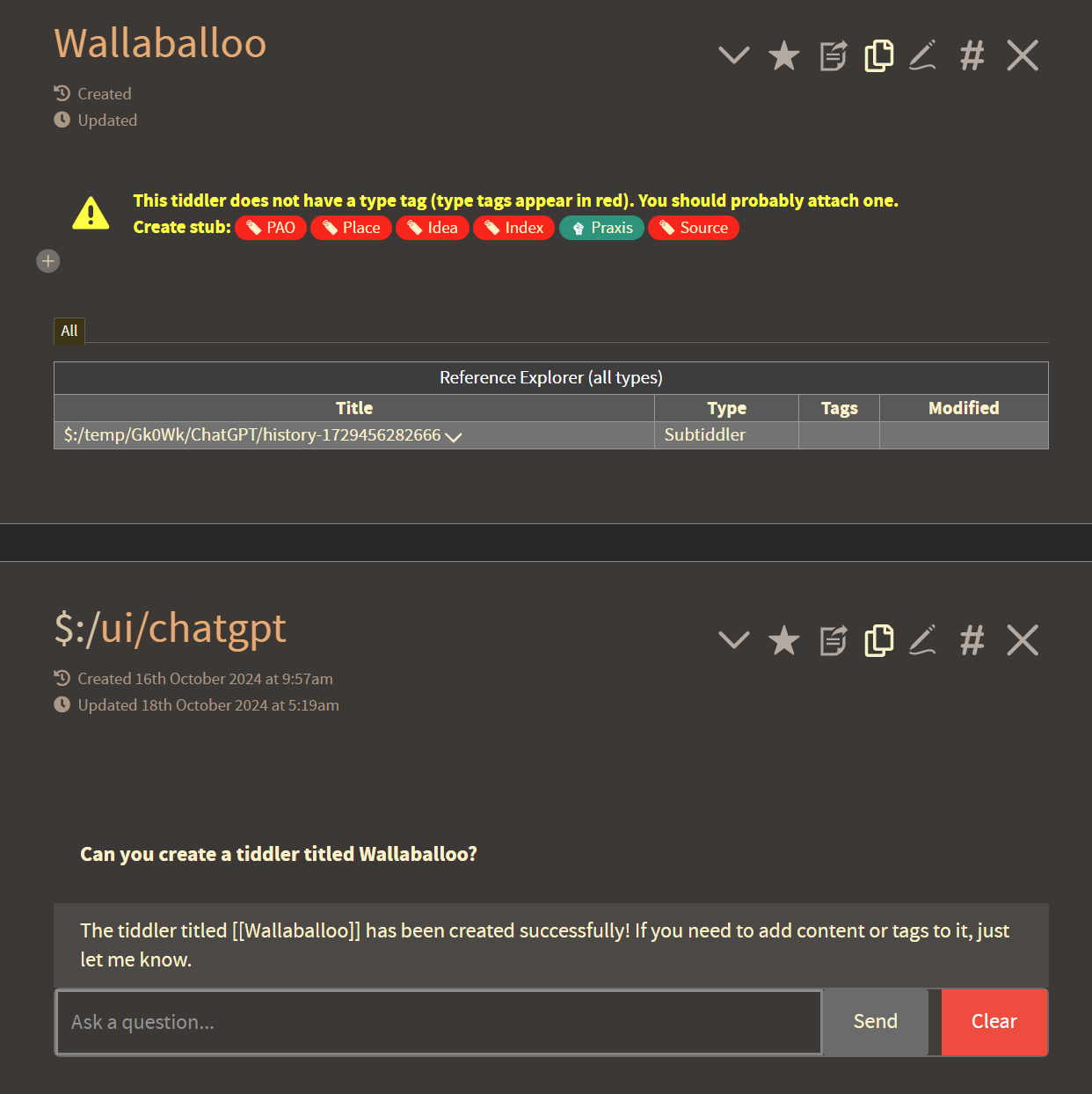
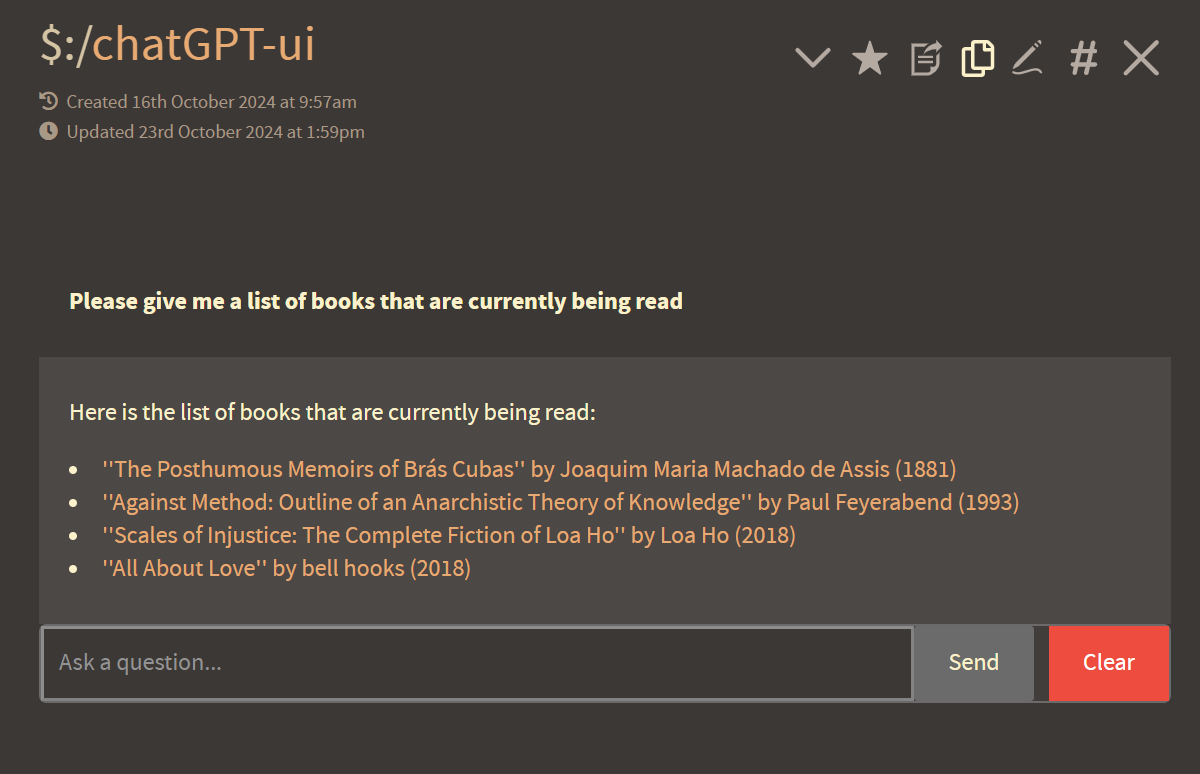
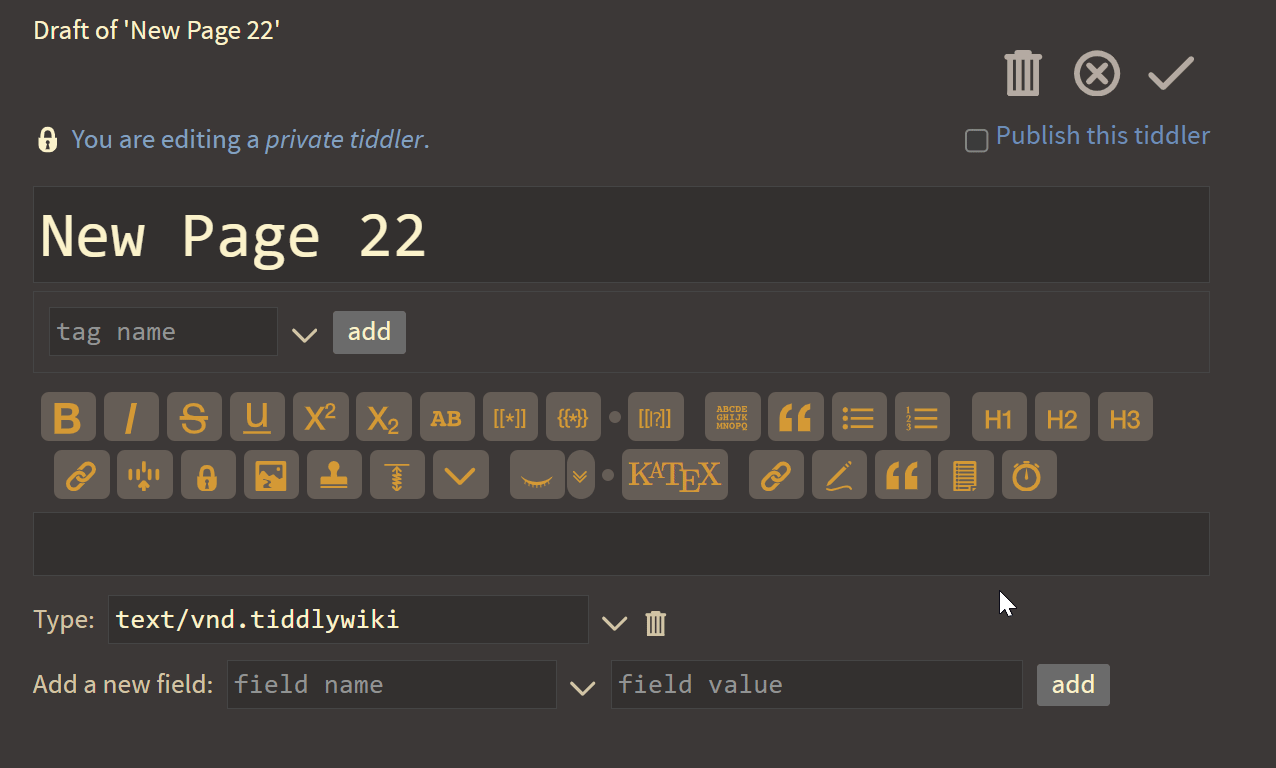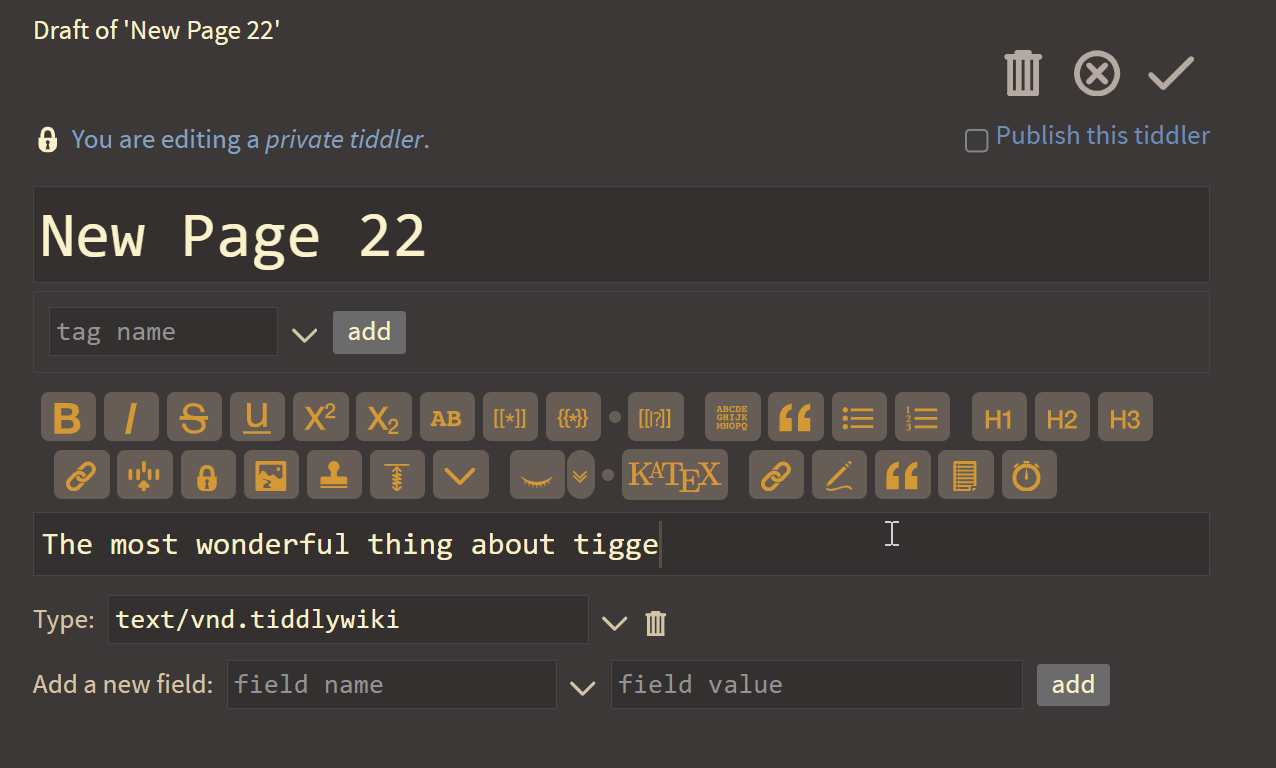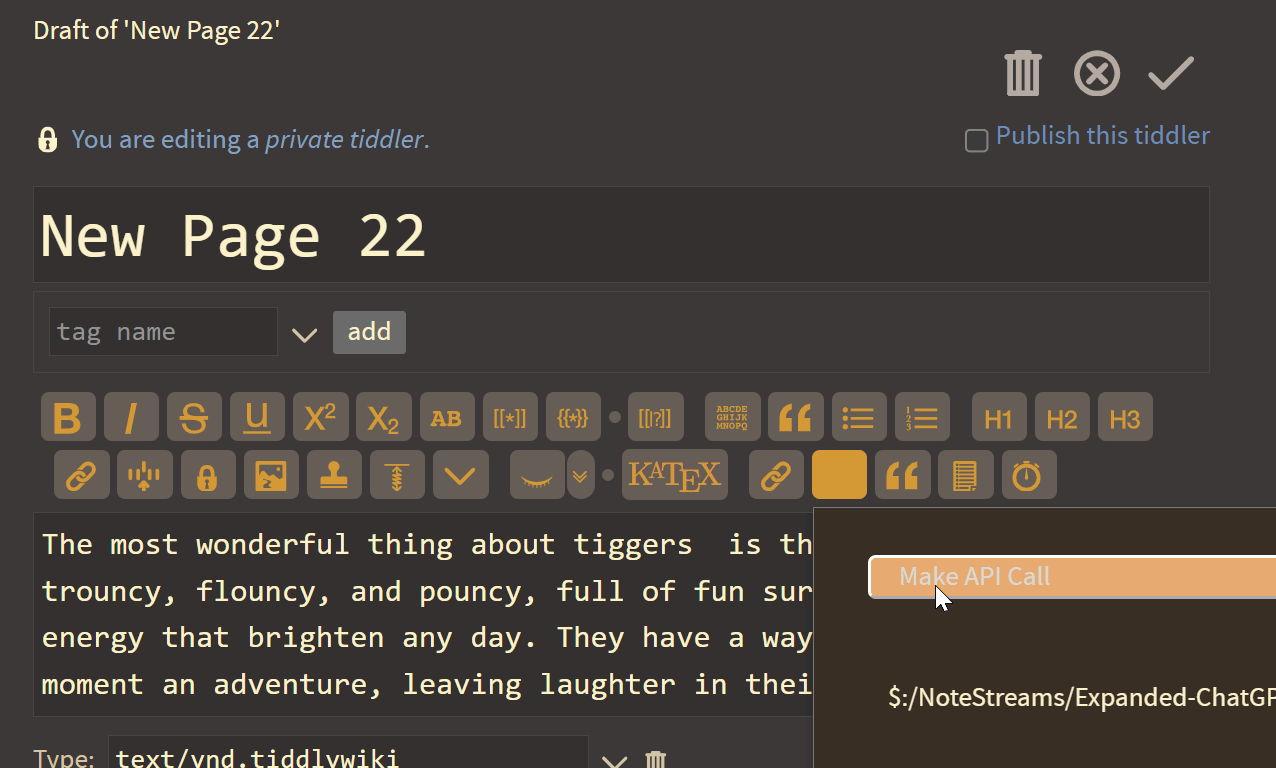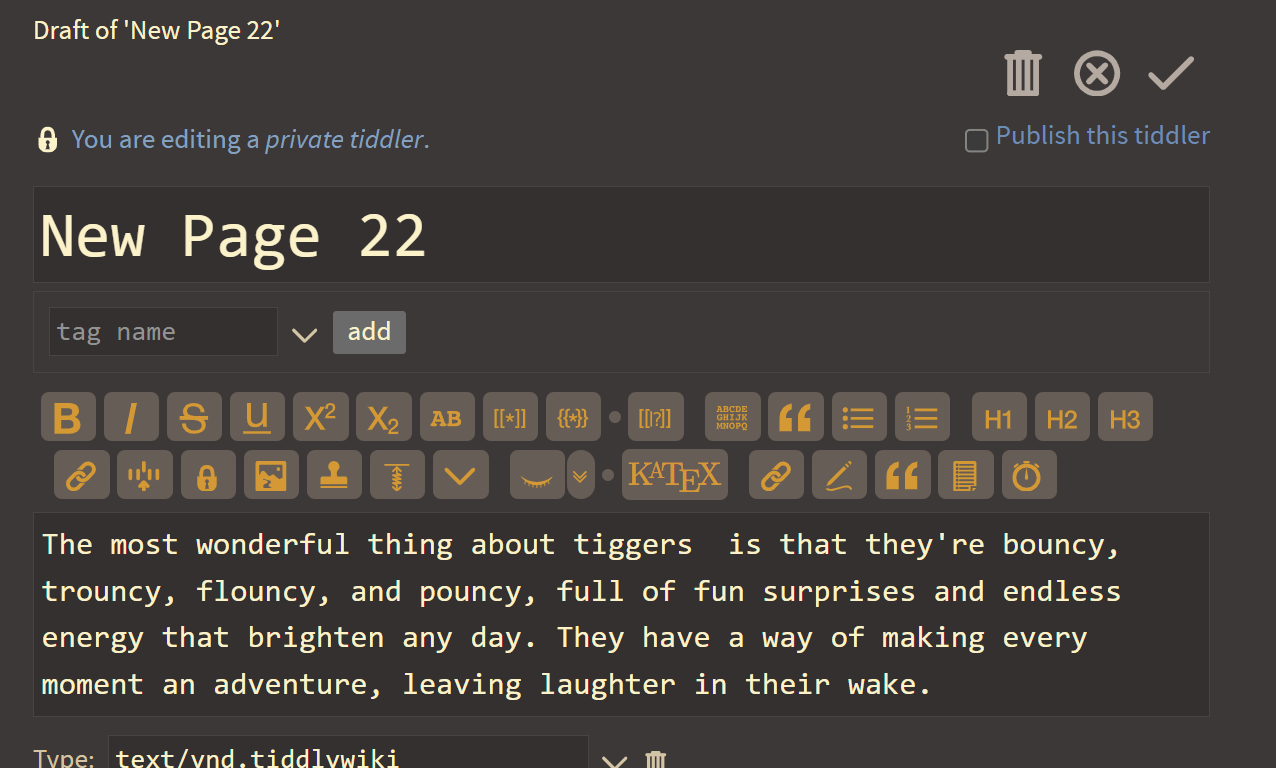
As you can see, this agent has been given the ability to create new tiddlers based on natural language prompts.
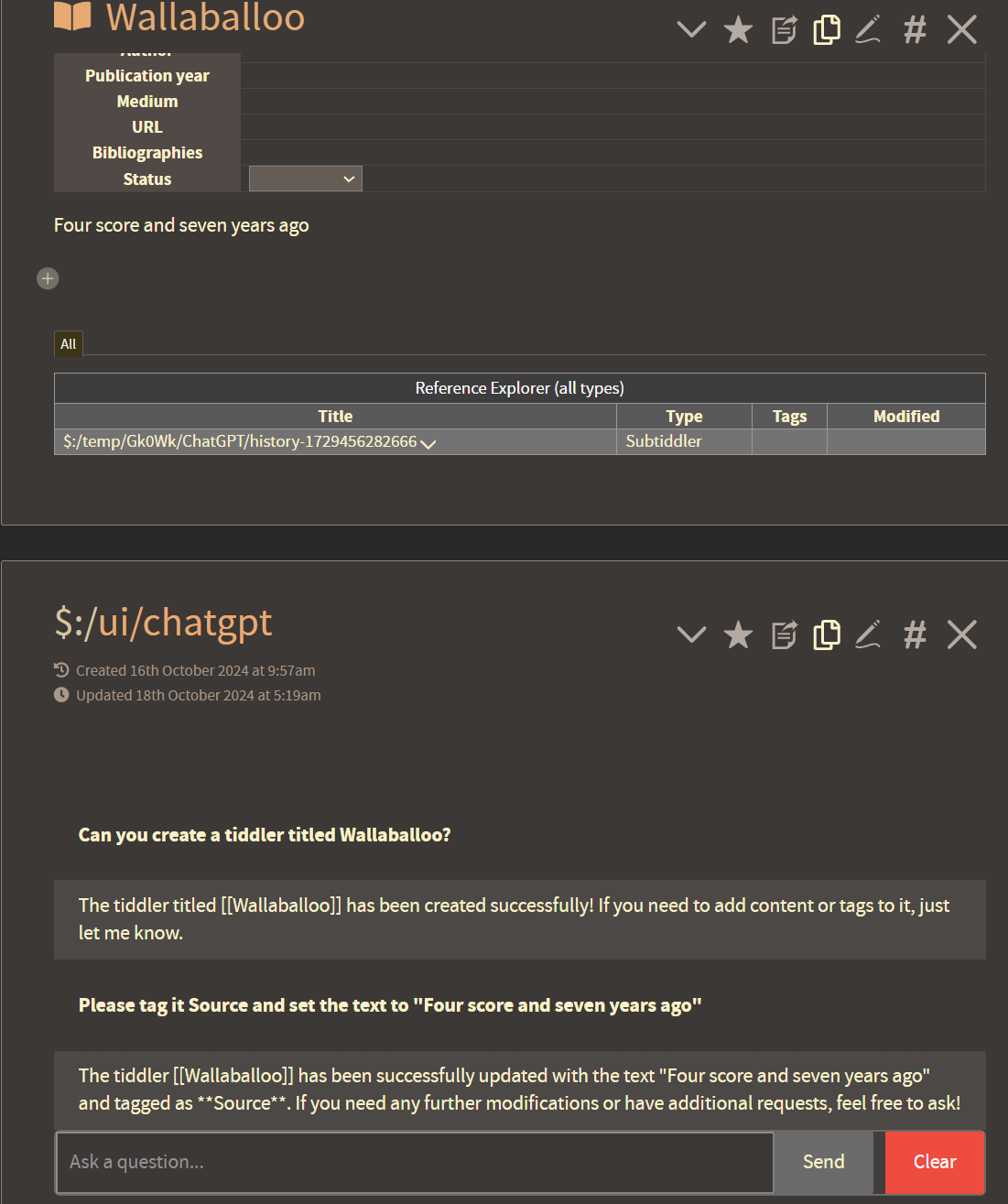
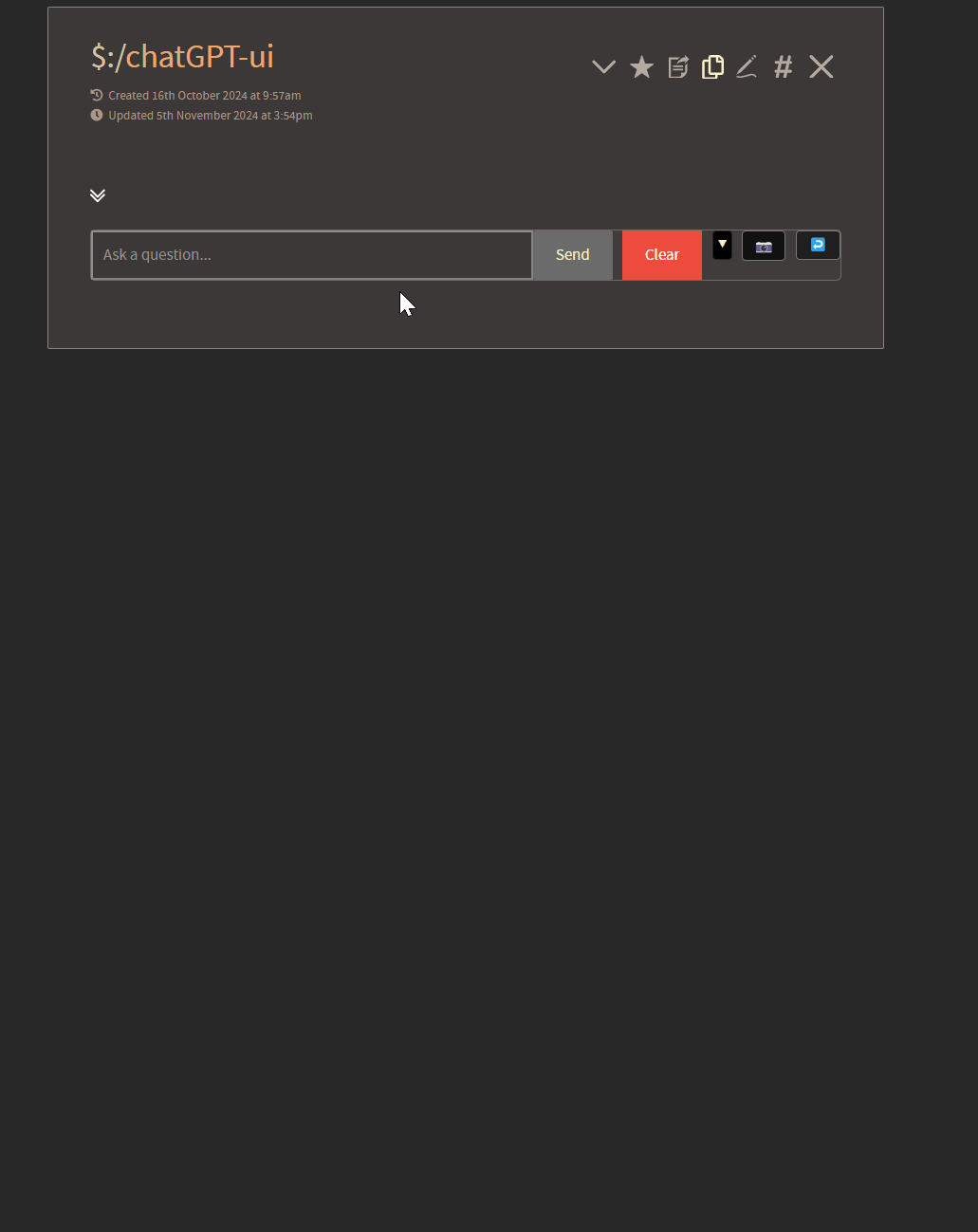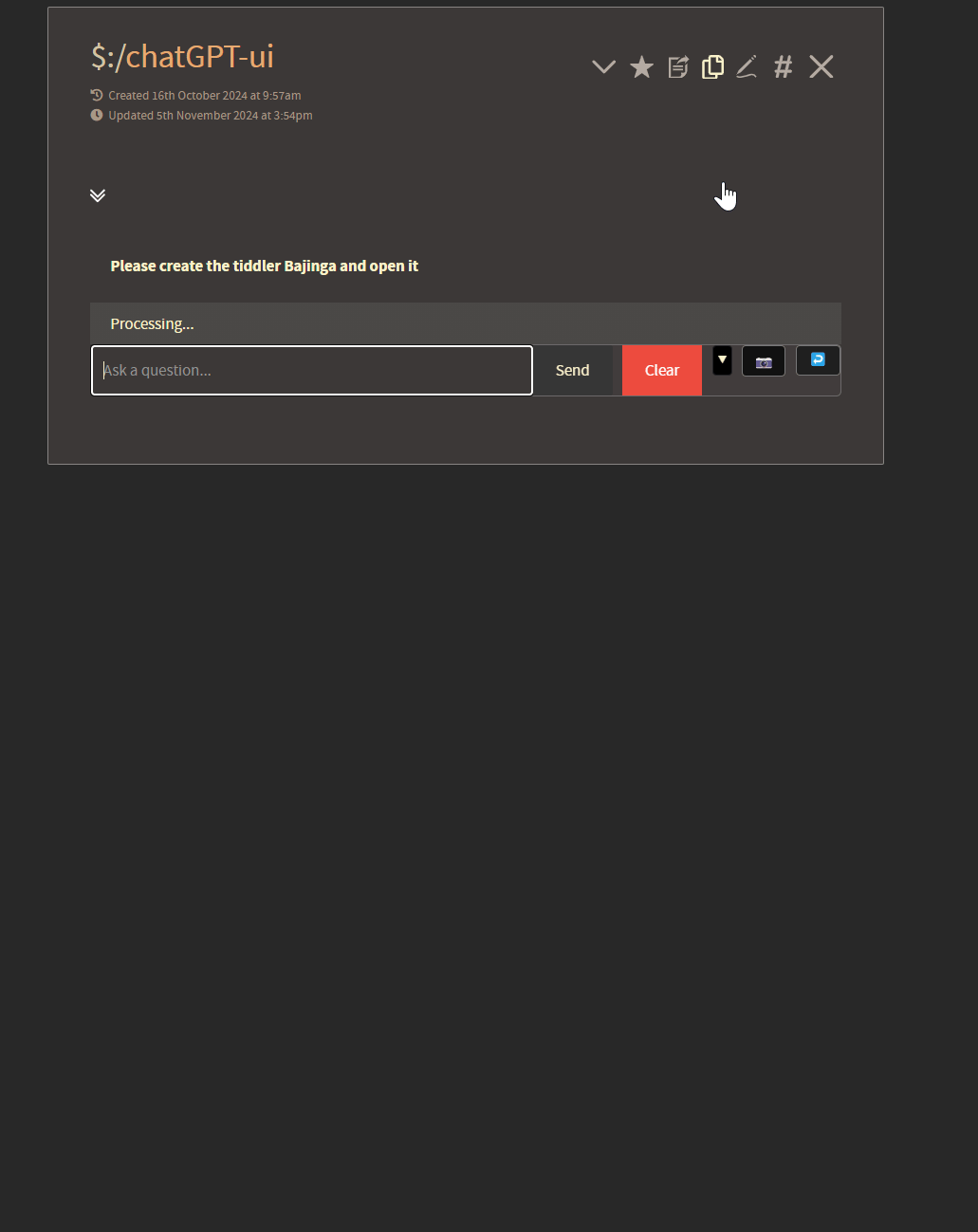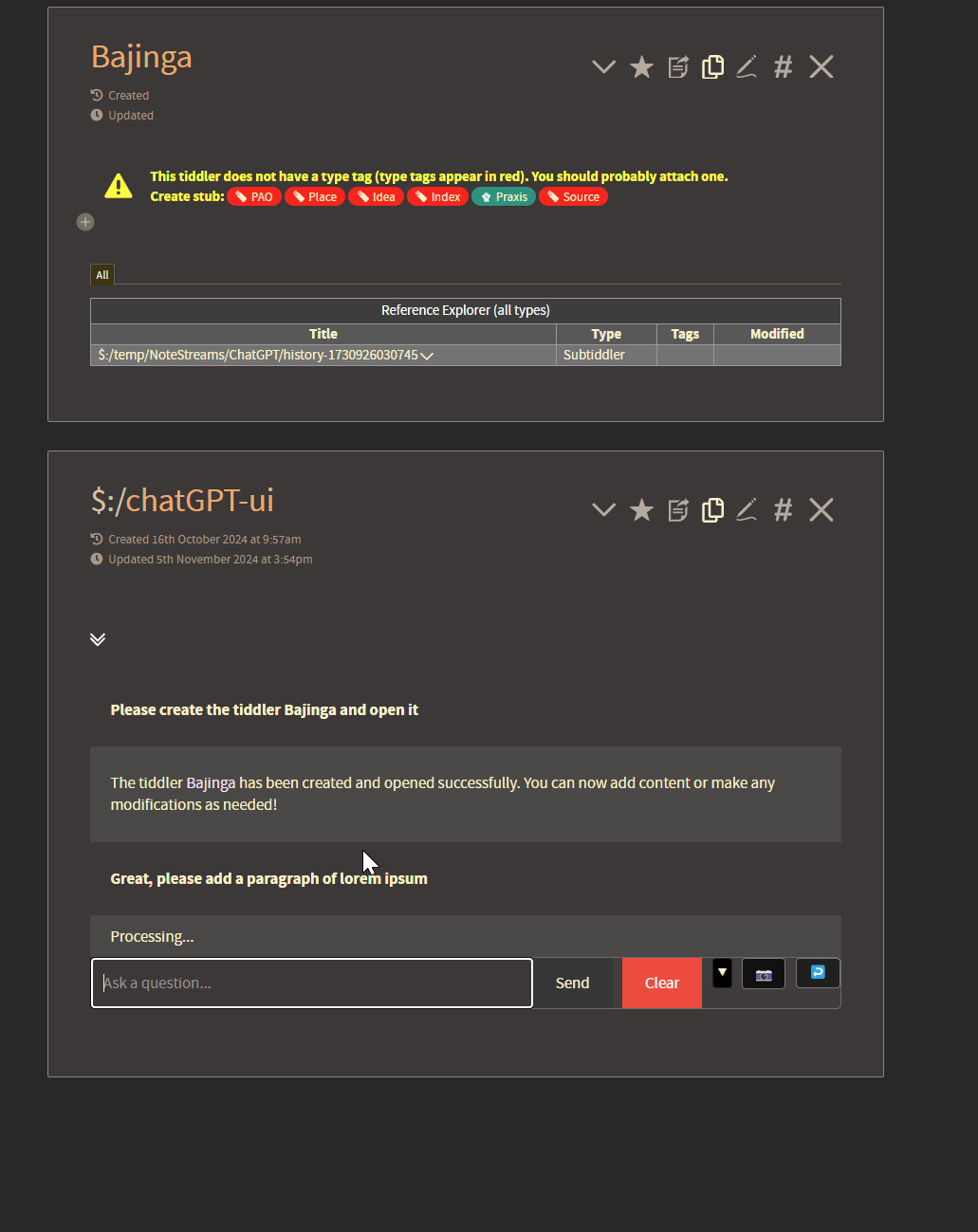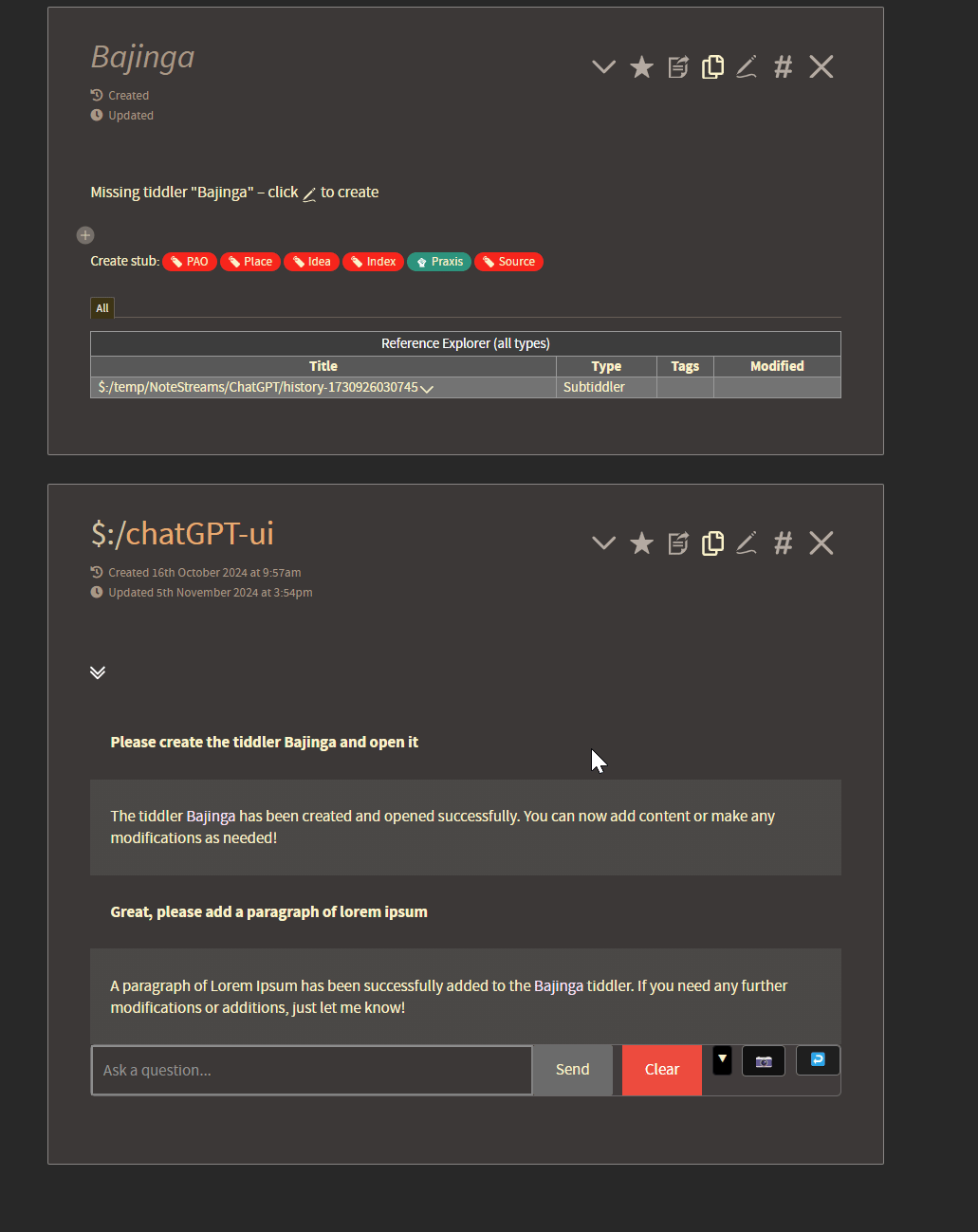
Here you can see a demonstration of 1) its conversational memory and 2) its ability to make changes to existing tiddlers based on the users natural language request.
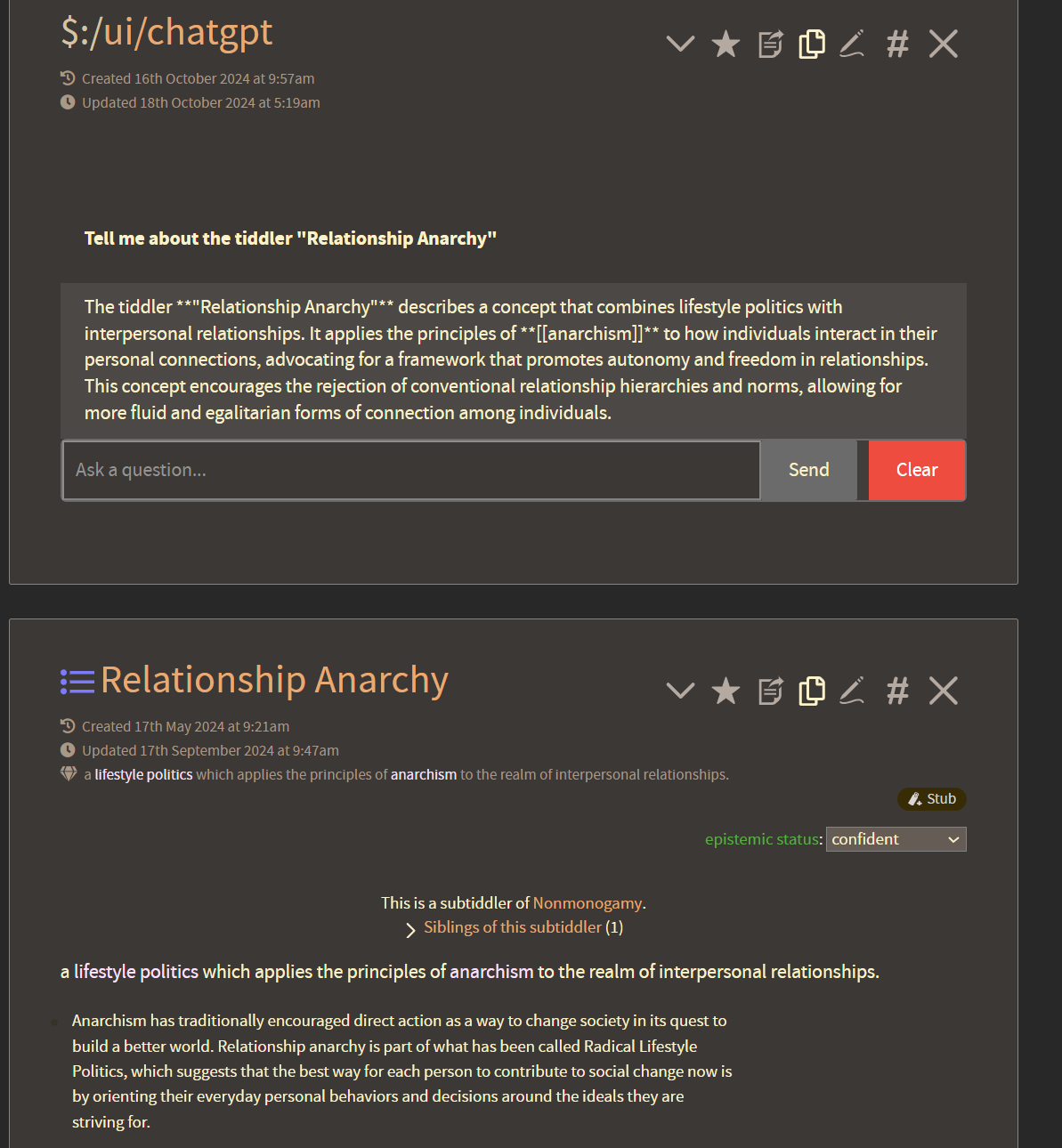
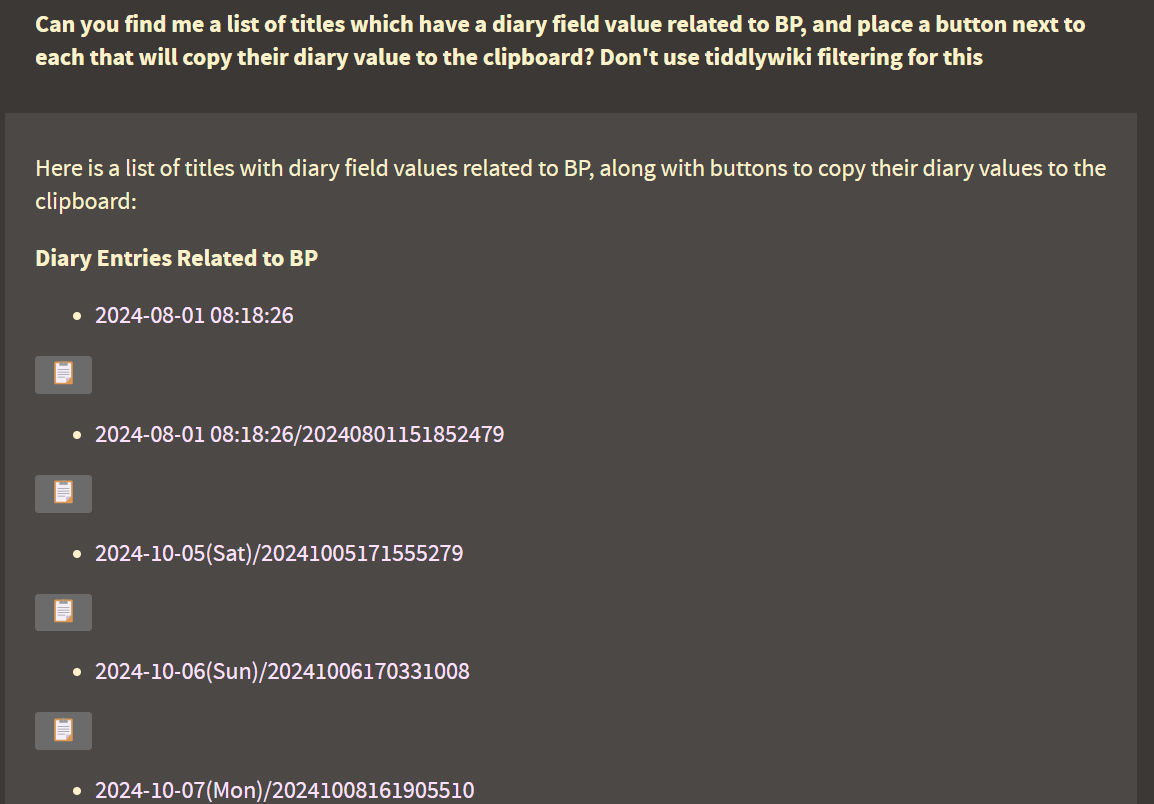
You can see that the agent is not only able to recognize specific tiddlers and call information from them, but will also consider content from that tiddler’s stream-list when answering a prompt, if it deems that appropriate. It can do this by searching for a matching title or for the content in any of the tiddlers aliases fields
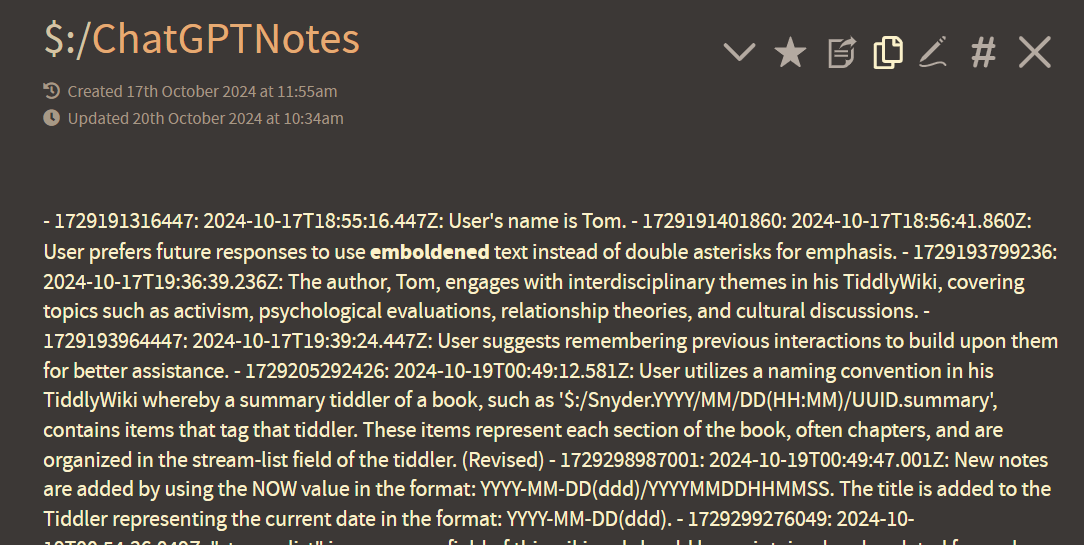
Here you can see that the agent self-selects information that it deems important and stores that in a reference tiddler, which it is able to use when it deems appropriate to responding to a user’s prompt. This allows one to “train” (deceptive choice of word in this context) the agent, by explaining important parts of one’s personal workflow. This is not specifically called out in the above example, but one can see that the agent does not simply add to this list, but can recognize if important information is already in the reference material, and (revise) the entry without modifying the rest of the content.
And I have also personally followed @jeremyruston 's example and used a small brain icon to “summon” the agent – this is not included in the plugin, but is simple enough to implement

It’s also possible to create a sidebar agent which directly references the storyTiddler – you can do this with
<$chat-gpt useCurrentTiddler="yes" />
{{$:/HistoryList!!current-tiddler}}
The above code is telling the widget to send the contents of the storyTiddler along with the prompts, and then it is transcluding the title below that for the users reference. This way, one might interact with their wiki without having to specify to which tiddler they are referring.
All of this together, I think, creates an incredibly helpful tool for interacting with one’s own content.
Some improvements I’m considering for the future:
- Wikify responses within the chatbox
- Give the agent the ability to open tiddlers in the story river
- Expanded control over tiddlers (i.e. the capability to delete tiddlers – with a user confirmation – from the interface) For obvious reasons, I have been unwilling to add this feature until I was sure the plugin was stable-ish.
- Expanded Reference capability that the agent might categorize its own reference material and to do so in a way that is more legible to the user (if one wants to review what it is the agent is using as reference)
- Multimodal capabilities (image recognition, voice to text/text to voice, etc.)



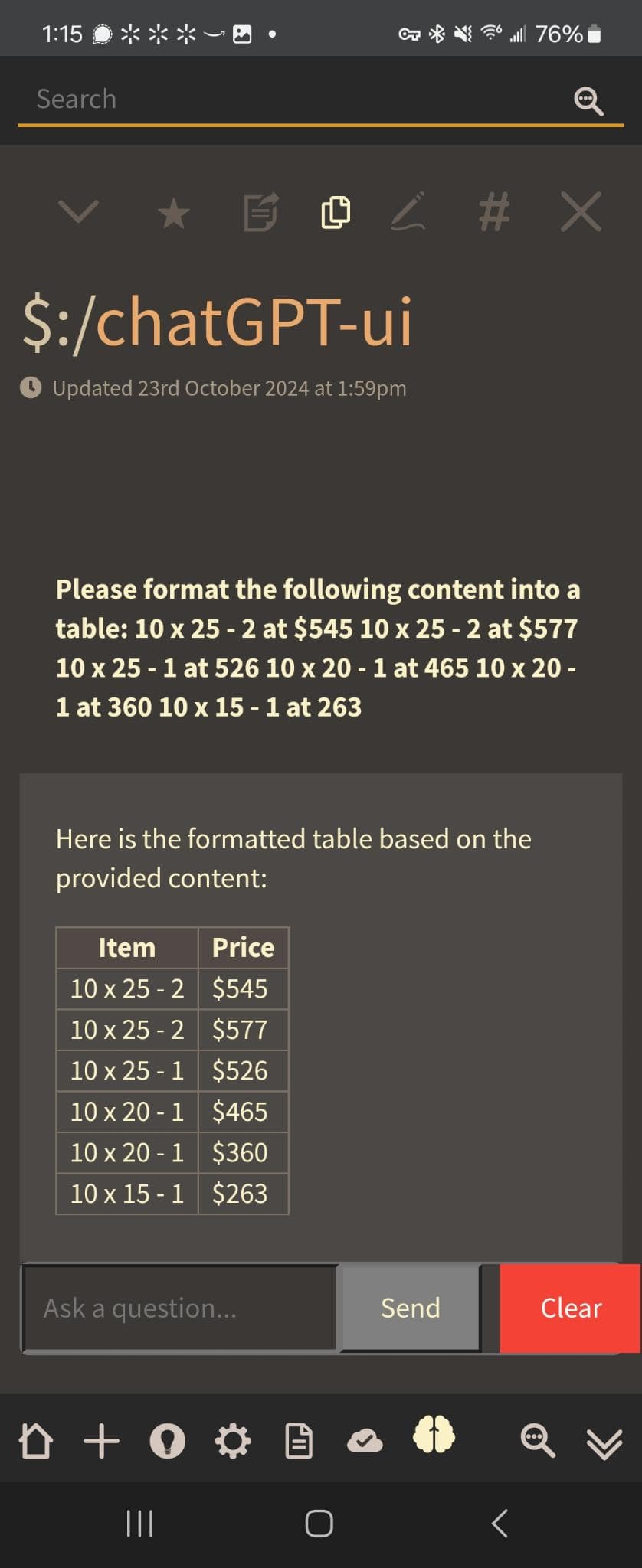



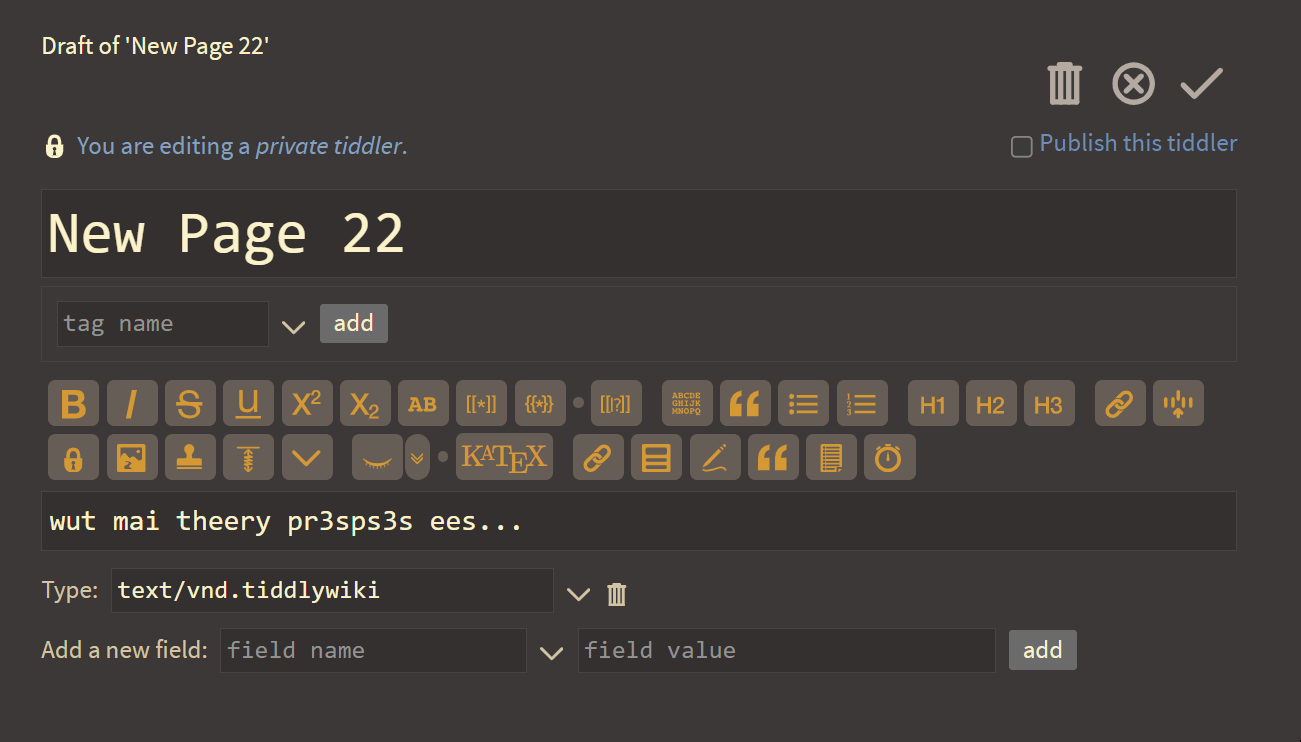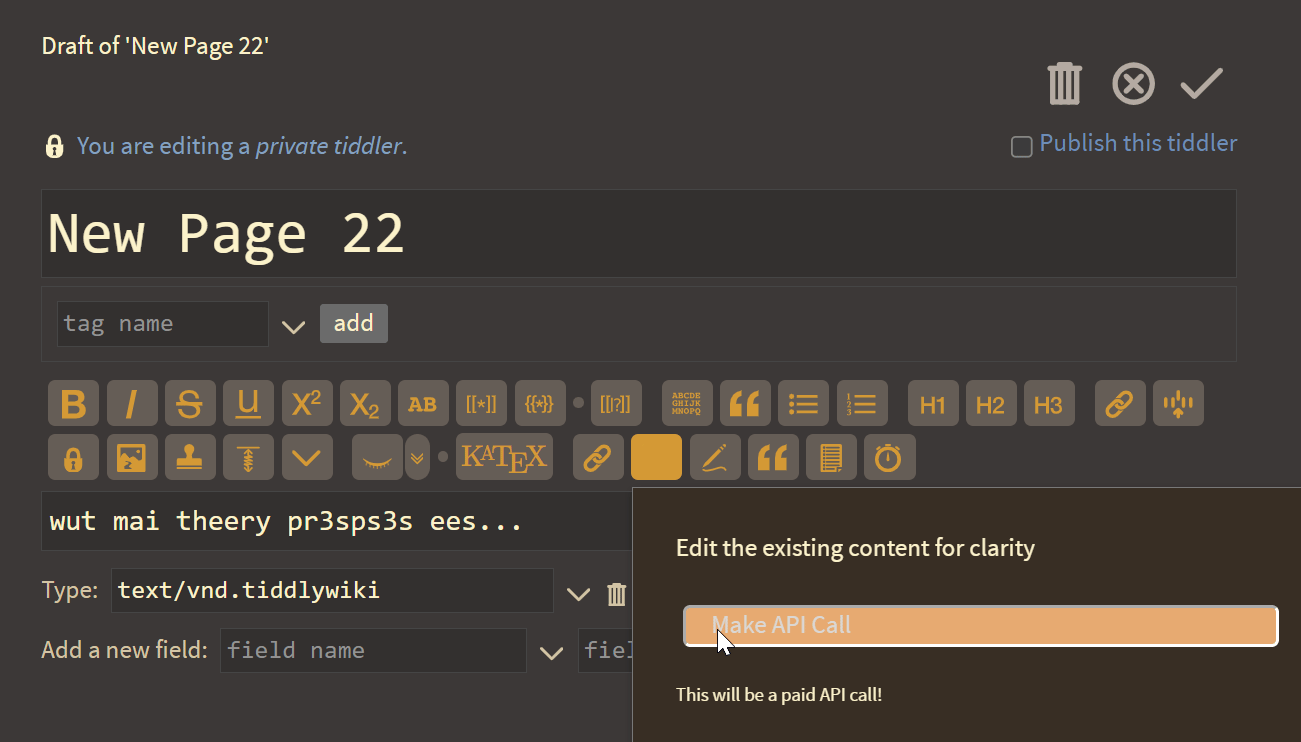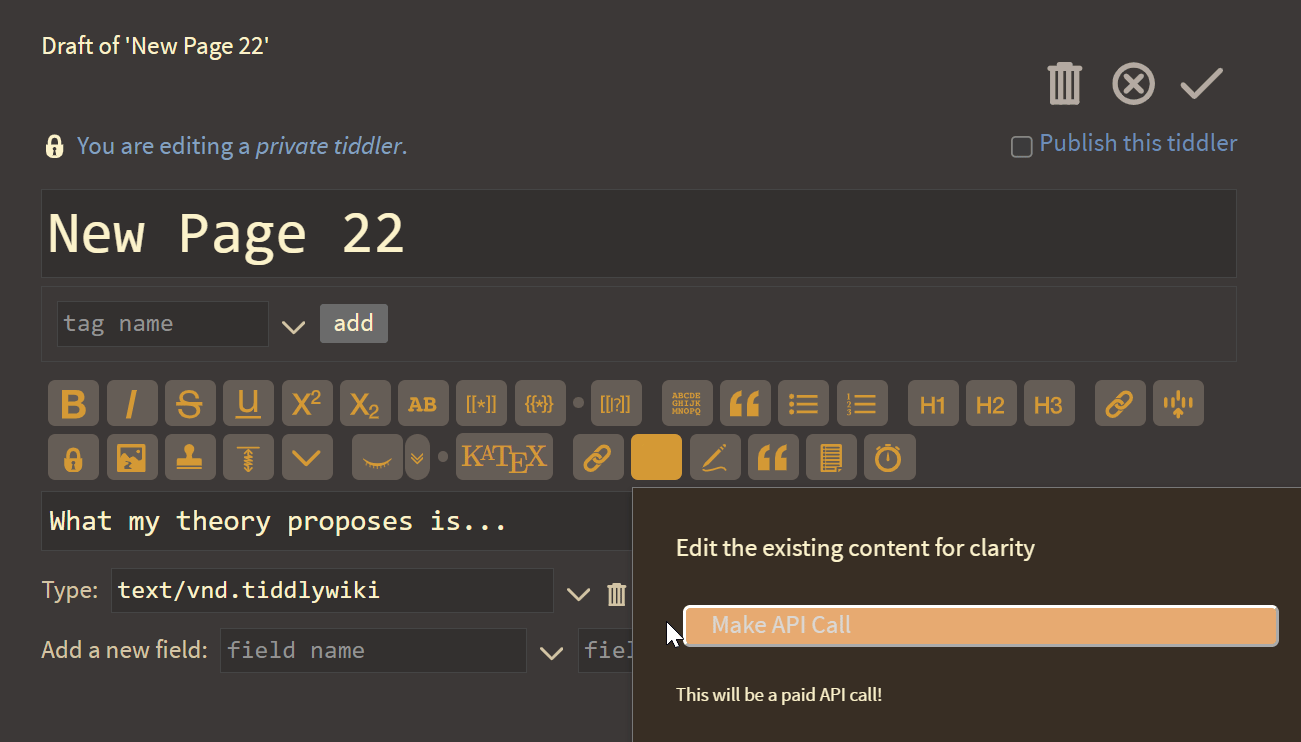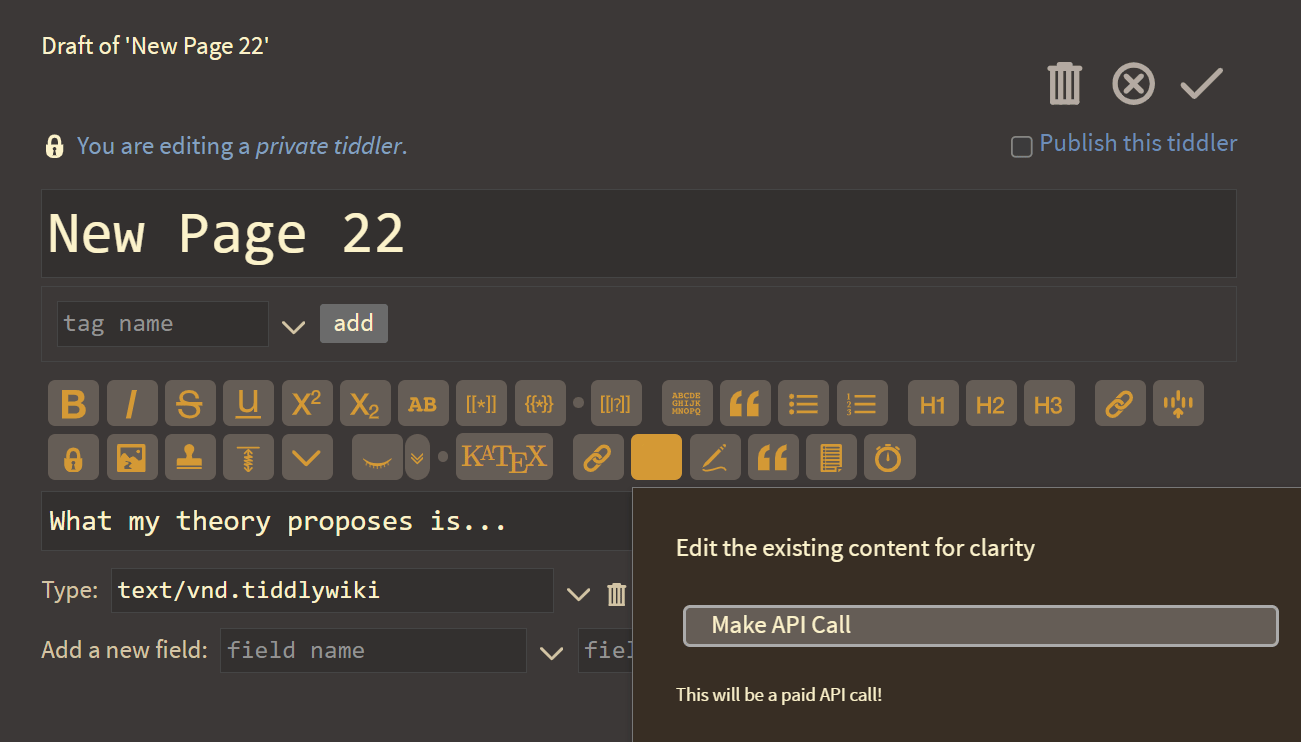
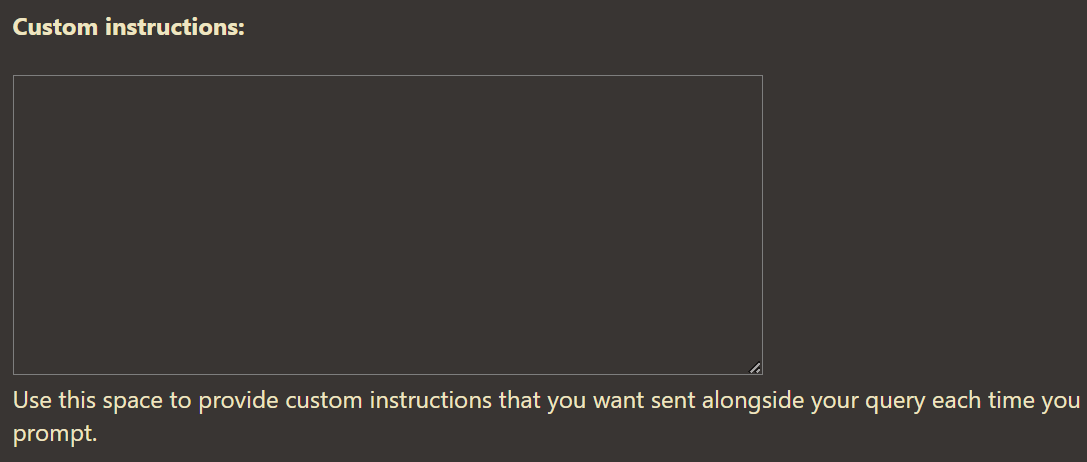
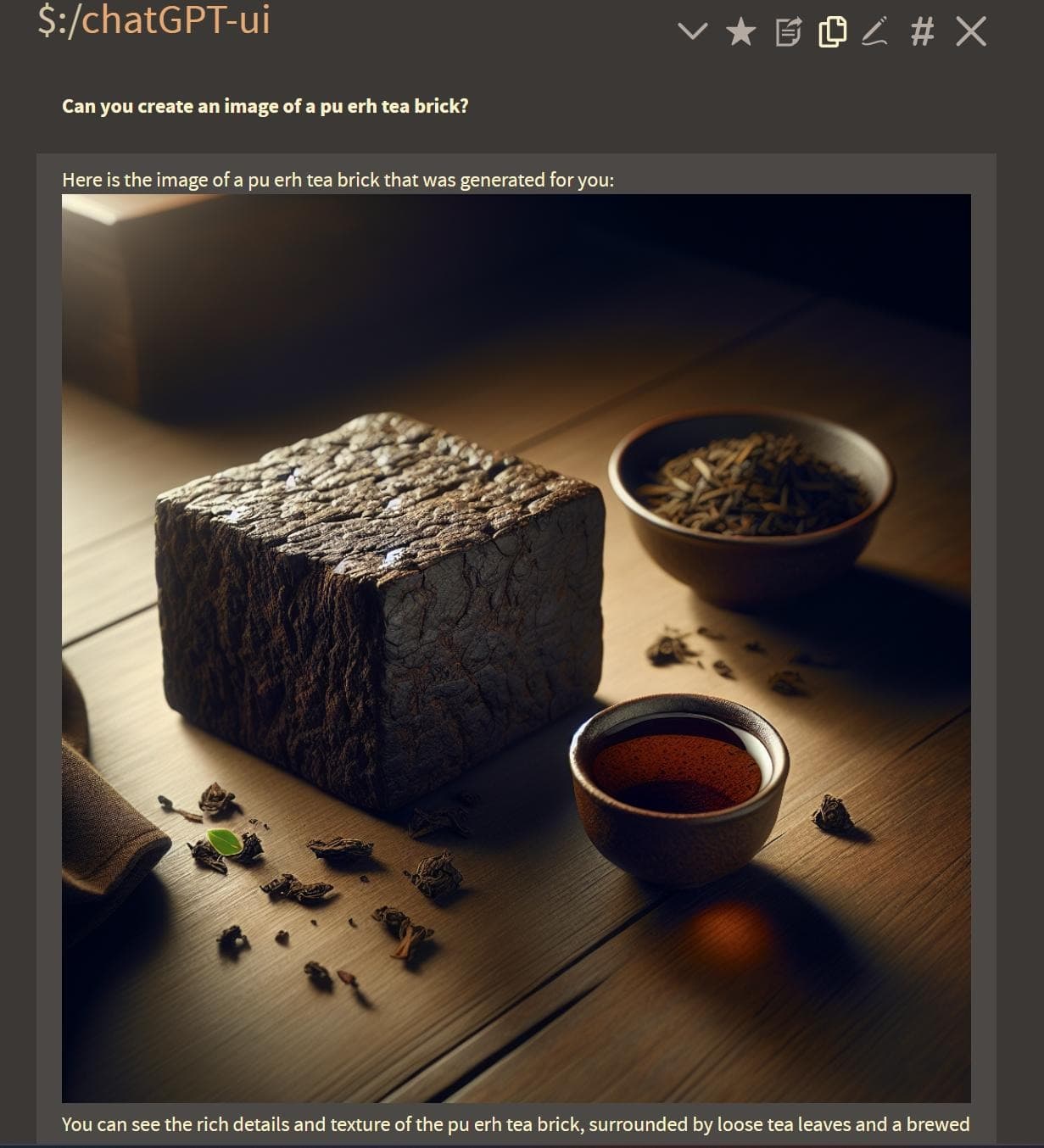

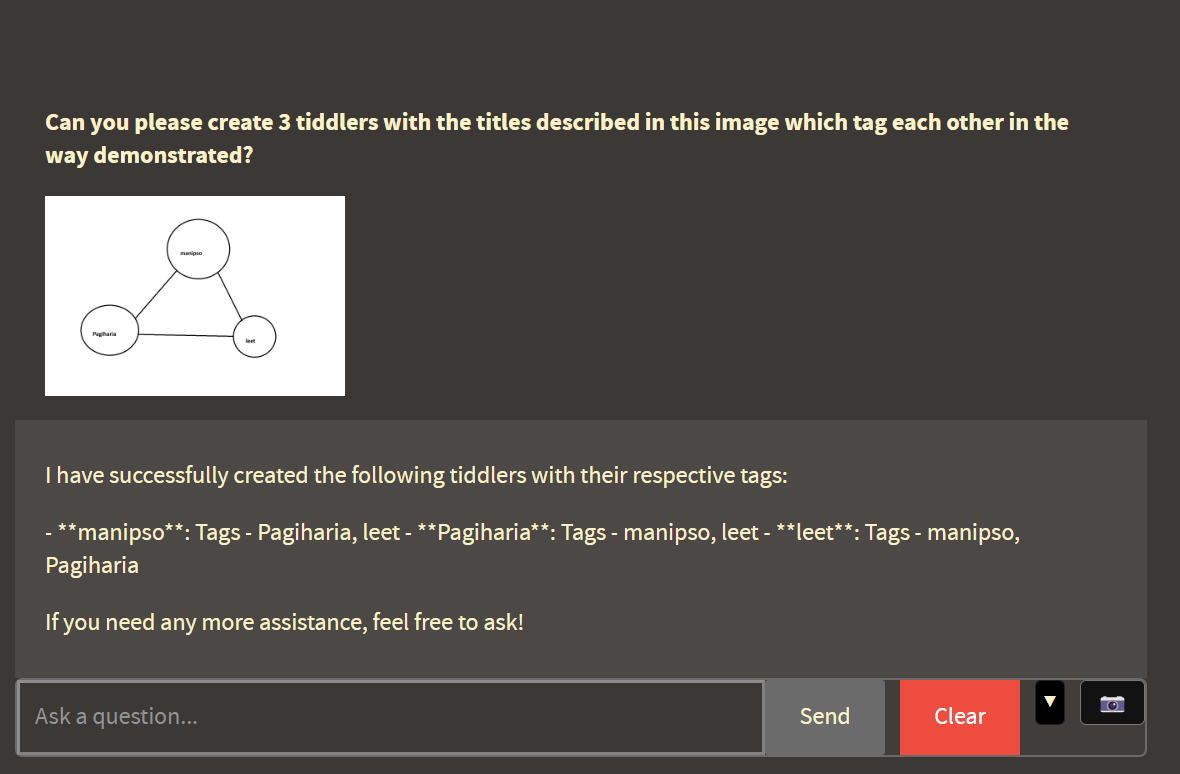
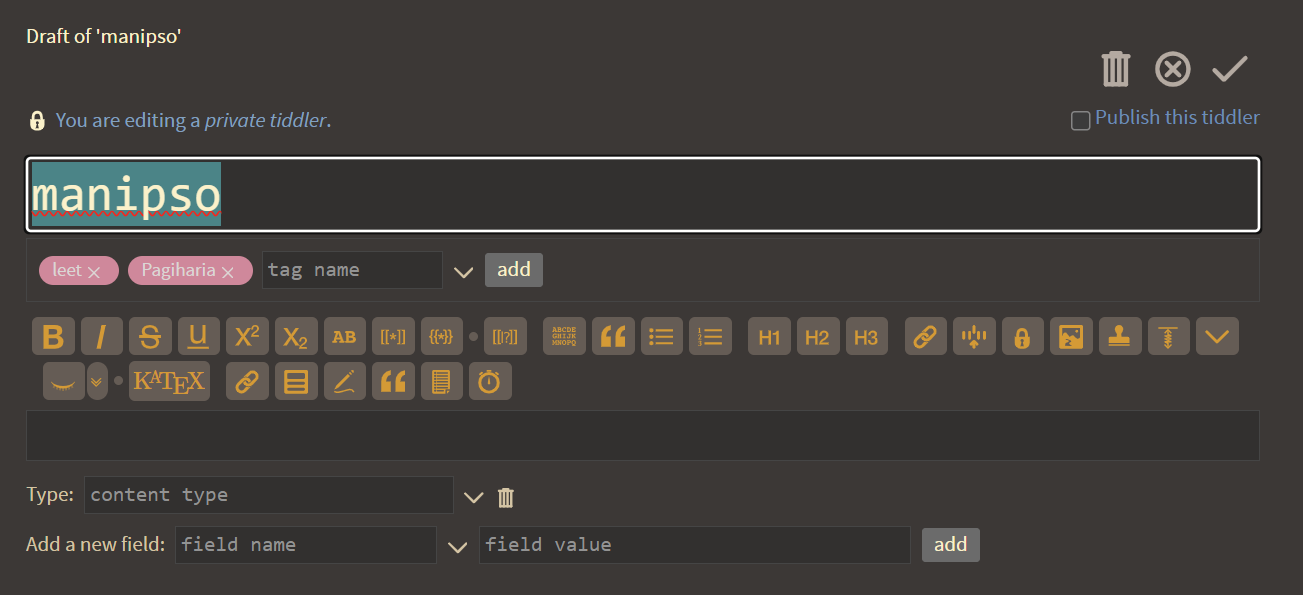

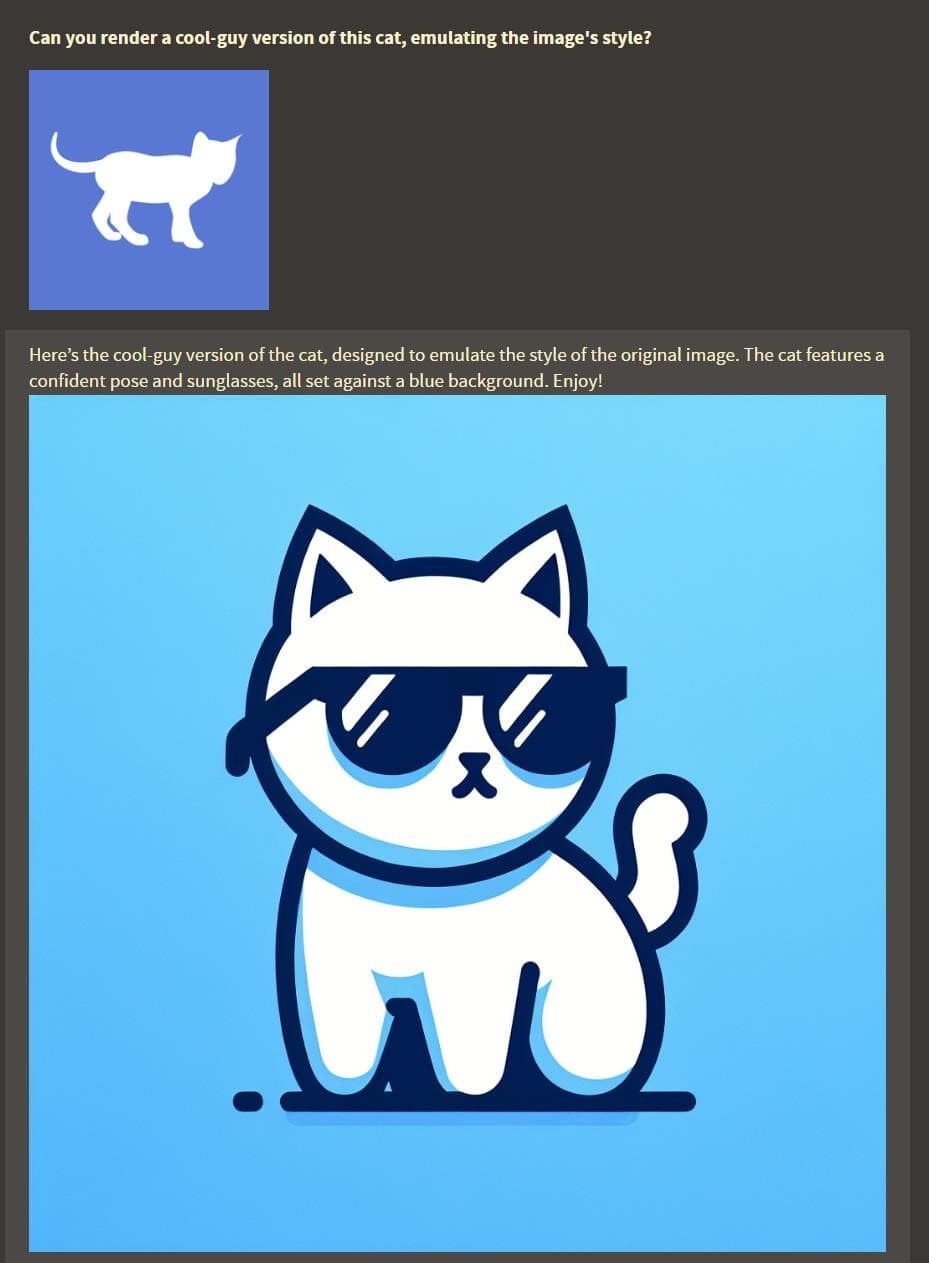
 And here I thought the best touch was pasting to upload
And here I thought the best touch was pasting to upload