Good morning. It is interesting to me that as I work with my wiki, although of late the file size has not changed, a lot else has, in terms of structuring the information. It seems strange to me that this is not quantified in any fashion. It would be nice to have an “anti-entropy” size in addition to file size. I wonder how that might be measured.
Hi @JenniferS that’s an interesting idea. I’d love to see those sort of metrics over my personal notes.
Not my area, but that won’t stop me speculating. I looked up how to measure entropy and the internet says it is done by “measuring the heat required to raise the temperature a given amount, using a reversible process”.
Which means that it hinges on the ability to measure the temperature of a wiki. In matter the temperature of a body is a measure of how much the atoms are jiggling around, which in turn perhaps might be approximated as a measure of how often atoms bang into each other.
Then, by analogy, the temperature of a wiki would be a measure of how many tiddlers touch each other, whether by a link, transclusion, usage of a macro etc.
So, to measure the entropy of a TiddlyWiki one would measure it’s temperature to start with, and then spend X minutes refactoring it furiously, and then re-measure the temperature.
Anyhow, I’d be interested in adding more metrics to control panel. We’re overdue to have word counting tool, for example.
2 Likes
I think Jenifer by entropy means: lack of order or predictability; gradual decline into disorder.
So, I believe by decreasing the chaos level . The more organized notes states the less chaos.
From Entropy Definition & Meaning - Merriam-Webster the third meaning can be used here.
By the way the analogy by @jeremyruston is nice. In thermodynamics an increase in system temperature would result in entropy increase. But here more connections may results in less randomness.
1 Like
One key point: I myself thought when I write a note it should be as complete as possible (in terms of tag, field, link, description, …). But human gets tired soon, dont want to put alot of time to organize, and if a process is lengthy he/she will give up or find another solution.
Human like any other things in this universe tries to stay at the lowest level of energy. This is the Gibbs law.
Based on above, later I learned to take notes in simple way (as lazy as possible), BUT then return to them, sit and organize them…
2 Likes
Maybe @JenniferS meant entropy in an information theoretical sense, as proposed by Shannon?
Have a nice day
Yaisog
2 Likes
Entropy is a big part of signal processing so it is something I have spent what is probably way too much time studying this stuff.
Entropy of text is simple enough. Measuring the entropy of tagging and other organization would take some thought.
Just doing the text of tiddlers could be interesting by itself, it would give some measure of novelty or redundancy in each tiddler. It is the same idea used by text prediction on phones, but going the other direction.
1 Like
Thank you for all these lovely responses!
I remember in my studies in Information Management we had a professor who stressed to us again and again that where we brought value to systems was in enhancing the relatedness of information. This was where the money was, he said, quite literally. So I quite like the heat index analogy. Perhaps I am also wondering about a heuristic for complexity.
It sometimes feels that I am attempting to create a fractal curve out of all the experiences of my life within my wiki. Like a system of roots, but in somewhat more dimensions.
1 Like
G’day,
- EDIT: Oops, I’m conflating the mess of intertwingled thoughts of measurements in my sponge. Here, I’ve described a measure of tiddler intertwingularity, which is interesting, I suppose, to measure the complexity of intertwining+interconnecting going on. Low intertwingularity maybe informative in one or many ways (like the lonely tiddlers out in the cold/dark, as per @tiddlyD in his post below); high intertwingularity maybe informative in another one or many ways (like elucidating new as-of-yet identified types of information).
Insta-thought: gPlanarity.
So entropy measured by the minimum number of intersections that can be possibly found by moving stuff around?
Oh my lanta, the algorithm for that would fascinate me, and I would love to see it in action shuffling them little tiddler orbs around (yeah, I geek out on this kind of stuff.)

2 Likes
Very interesting discussion and I too like the temperature analogy of @jeremyruston.
Information availability (What is Availability? - Definition from Techopedia) is often an issue with information gathering tools especially when they grow beyond a certain point. I guess we all experienced the “I know I wrote it down somewhere”.
The aspect that drives a wiki way beyond most classical note taking approaches is its basic concept of cross-referencing (aka graph vs tree).
The less a node (tiddler) is connected the more it stays out in the cold/dark. It can only be found when you’re actively searching for it (and remember the right bits and pieces to query for it)
So a very direct approach for a measurement would be the average number of backlinks per tiddler (or ratio between tiddlers and in-wiki-links).
But given the power of tags the links would describe the entropy only partially.
1 Like
Information availability, intertwingularity, yes. Perhaps when these are high, so also is serendipity and synchronicity.
Shades of Indra’s Net.
“The metaphor of Indra’s Net originates from the Atharva Veda (one of the four Vedas), which likens the world to a net woven by the great deity Shakra or Indra. The net is said to be infinite, and to spread in all directions with no beginning or end. At each node of the net is a jewel, so arranged that every jewel reflects all the other jewels. No jewel exists by itself independently of the rest. Everything is related to everything else; nothing is isolated.”(The Vedic Metaphor of Indra’s Net).
Everything is a tiddler!!!
3 Likes
Here’s a concrete idea to quantify/measure the structure of the information:
A tags-to-tiddlers ratio. Or, more general, a mention-to-tiddlers ratio, i.e any mention of the tiddler in any field.
A “mention” is, AFAICT, the same thing as a connection. And a connection is perhaps the simplest form of a “structure”. (I just made that up but it feels reasonable). Perhaps a hierarchical relationship is another form of structure, and it is more complex since it encompasses both a “connection” and an order.
Questions/reflections:
Should [tag[Foo]] both give a point to Foo and to all tiddlers tagged Foo? (Probably.)
This also raises the question (or perhaps answers it) if the mentions should be counted in the code or in the rendered output. Or both.
Does context matter? Are some “mentions” more weighty than others? Are three serially connected items (i.e two connections) more or less structured than two items connected in a ring (again two connections) (…and perhaps with an unconnected item (so that the mentions-to-tiddlers ratio has the same denominator).
If “quantifying the structure of the information” can be interpreted as “quantifying the complexity of networks” then I’d think there are established methods.
2 Likes
According to Andy Matuschak, the primary metric for knowledge workers should be the number of “evergreen notes” written (per day).
(If you just keep restructuring your notes, you’re not gaining nearly as much value as by writing new stuff.)
I think he would agree that links are the next metric. Tags have lower value, since they are indirectly connecting loosely related notes.
So, count the number of written notes and the number of links. These should go up.
You can try to navigate his ideas on this here: notes.andymatuschak.org
2 Likes
Entropy in thermodynamics is not disorder (though a lot of text books talk about it in that way) but laziness. Everyyhing wants to get to it’s lowest energy level. Your cold cup of tea has maximum entropy because it is at the lowest energy level it can achieve. (the same temp as the air in your kitchen).
Deserts aren’t made of sandcastles because there are many more ways to be a hill than a crenellation, so it’s easier to be a hill.
3 Likes
Thanks for the story and the reference.
Regarding “intertwingularity”, TiddlyWikiPharo is a work in process that @ruidajo and I have been doing to bridge TiddlyWiki with Pharo (more info in the previous link) and it allows us to create custom visualizations of the connections between tiddlers and link/export/import them from/to data stories. Here an screenshot of one of them:
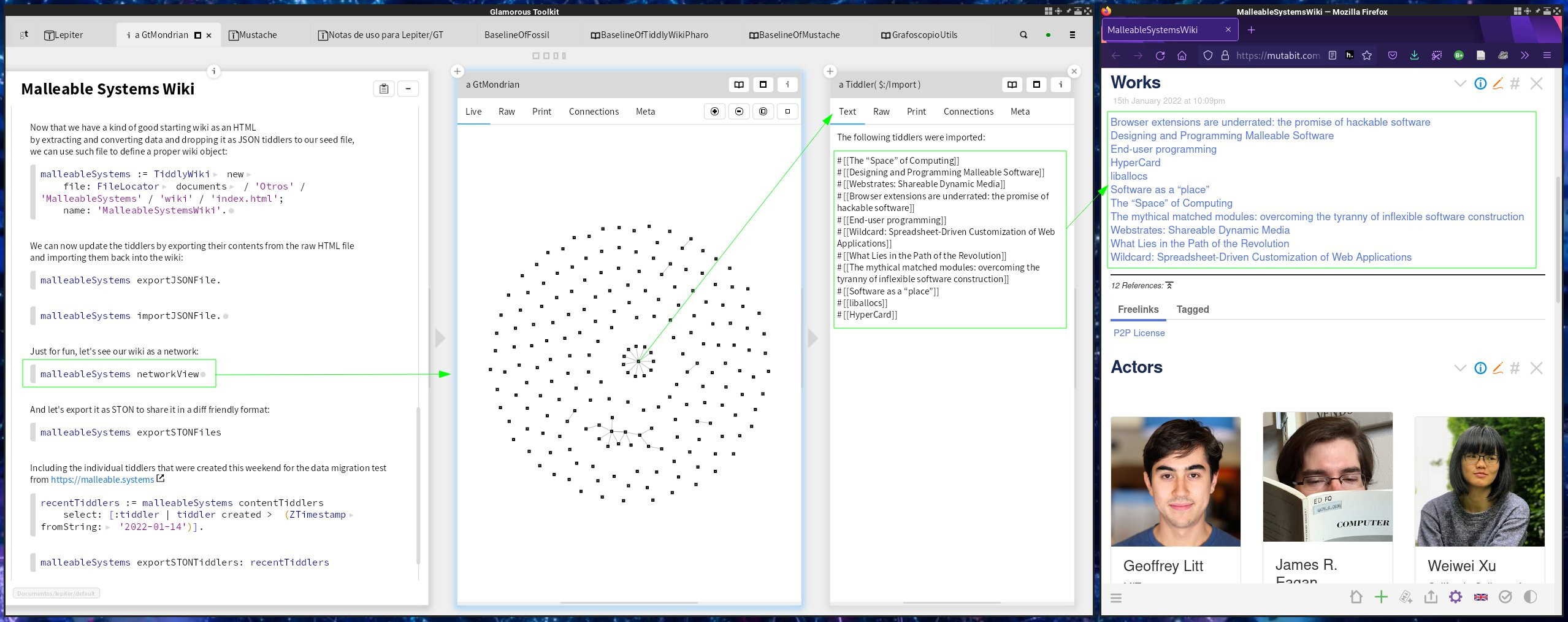
I felt this serendipitous connection of tiddlers back in 2008-2010 when I was using TW a lot and now is coming back, after almost 10 years hiatus, with a renewed sense of possibility, as I’m able to program TW from Pharo/Nim and create custom visualizations and data narratives to showcase “intertwingularity”. At the local community expand/connect socio-technical systems via “interstitial programming” by addressing what happens between them.
This forum is part of such serendipity, pointing and connecting people, practices and knowledge. Thanks again.
4 Likes
I have a somewhat different perspective than some here, a few notes;
- I think entropy is higher the less relationships that exist between the parts
- Increased order can be establish by following this path, Data > Information > Knowledge
Start with an empty tiddlywiki
- As we gather data or information and put it in our wiki it gains complexity but not necessarily order.
- When we enter content, it is wise not to loose information that is available to us in the source.
- You could import data that has a higher entropy, or more disorder than where it is found (by not indicating its source, context and relationships to other data).
- maintaining context information is also helpful
However once we have data and information in our tiddlywiki we may be able;
- Rediscover information in our data (typically relationships)
- Discover information in our data though the discovery of relationships we were not aware of
- Add information as we use and review the content in light of our own knowledge and understanding.
Plan language itself contains a lot of information thus prompting my interest here Wordsmithing stop words, verbs past and present tense - #2 by TW_Tones
If you add more data without actively retaining and discovering information to organise and structure the data you make your wiki more complex without increasing order.
If you organise and structure your data you increase the order within your wiki.
- It is best when structuring content to do so by the addition of structured layers, not the replacement of existing structures or you loose information. See content views.
- It may be possible to reduce the complexity of a wiki by removing redundant information so long as you do not remove information, sometimes even the fact that it was redundant.
Content Views;
TiddlyWiki allows us to prepare multiple views of the same data without removing any data from the wiki, thus where there is an advantage to do so we can simplify our view without removing information. For example where applicable remove redundancy or duplicate information as it appears on N dimension’s whilst leaving it in place when viewing it in N+1 or N-1 dimension’s. This is “making it simple” not “keep it simple”.
- When alternative views lead to new information eg relationships, you may capture this in the objects in a way other views can also “see” these new relationships, and possibly expose more information in the data. Keep in mind “why store something if you can derive it?” although sometime storing information makes it easier to use that information in other contexts.
Relationships can be represented in many different ways; Here are few to inspire someone trying to increase the order in their data. Remember to add them to the wiki and don’t replace existing ones.
- Missing information can be as important as the information present - missing tiddlers.
- Any structure can be represented in tiddlywiki including;
- Series - ordered or unordered
- Lists or sets
- Adhoc networks
- Spontaneous networks
- Hierarchical networks
- Singleton, One-to-one, one to many, many to many
- Data normalisation, “related to the key, the whole key and nothing but the key”
- Tables of N dimension’s
- list and set relationships, comparisons etc…
- Arrays and array manipulation
Some key features of tiddlywiki that help in this endeavour
- Backlinks, tagging, lists, listed, tiddler type (shadow, system, tiddler, missing)
- Global or filtered search Search
- Filters
- Namespace(s) eg system
$:/ - Freelinks plugin
- Highlight plugin for supported code
- I wonder if we could build a highlight for words as here Wordsmithing stop words, verbs past and present tense - #2 by TW_Tones
- Lists, list fields, nested lists, map and reduce
- Common and ad hoc fields with or without a value
- Rename and Relinking via relink plugin
In closing I have come to believe a key architectural feature of tiddlywiki is;
Tiddlers have a unique key, or title, which we see at eye level. Whilst we must keep it unique;
- it is easy to add suffixes and prefixes including increments or store additional content in a data tiddlers with different or duplicate keys, the title then becomes the table/dataset name, and the keys can be duplicates of tiddler titles.
- it is easy such as with tags to organise tiddlers into larger sets.
1 Like
I will also add the following guidance;
- If external data sources are able to change and you plan to update your wiki with this updated data, at a point in the future, design this possibility into your wiki. At the worst you may need to do a little house keeping, at best your wiki is tolerant of change.
- One form of tendency towards entropy is the aging of information, or a lack of maintenance.
- It is possible to build redundant information into your wiki, such as tiddlers could contain a parent field and a child list field, and each child their own. If you needed to move/delete a child (because it is incorrect) make sure to also update the parents child list as well, or a least detect when their is a variance. ie maintain referential integrity.
- Just in time tools and code. Make use of the plugins and packages of JSON tiddlers to save common functionality, to import as needed and use when needed. To include features you do not need (yet, if at all) increases complexity (and wiki size) whilst not necessarily increasing order.
- You can group tools and code into bundles if you expect these to all be used in a particular application.
- There is more that can be written about avoiding overwriting core and how to, if you must.
- The best advice is to ask for improved hackability of the core. eg subTitle tag SystemTag: $:/tags/ViewTemplate/Subtitle
Please contribute more or criticise my contributions here, if you know what I am talking about.
1 Like
From a practical perspective with a research based wiki which exceeds my ability to hold stuff in organic memory my measure would be…
Given an idea, spot light on an area of interest or a question arising from reading one tiddler, how effective is the graph (network sense of the word) of tiddlers at alerting me to other tiddlers I added a few years ago that, given the opportunity to read them afresh I would regard as interesting or helpful in my current like of inquiry. It’s not about quantity it’s about quality for me although wild cards thrown into the mix can someones beneficially shift the spotlight of interest - that’s why I have a random button in my custom side bar - to stop habitual retreading of over worn neighbour hoods of the graph.
I regard tagging and linking as a skill acquired over time and probably specific to a person, area of research and so on, it’s also organic, I am constantly relocating links, creating “hub” tiddlers and generally restructuring as the knowledge base evolves.
I would love to see representations of the structure - tried TiddlyGraph but the sheer quantity of Tiddlers overloaded it both visually and performance wise. I guess that’s the problem with large graphs, you kind of want to wave a magic wand and ‘see’ it all at once but most solutions don’t scale well so you end up only seeing small parts ‘zooming in’ or you collect metrics which quantify but don’t really show the structure.
Time for VR and an immersive swim around a 3D representation of the graph? If you were a car designer and your Tiddlywiki was concerned with various research and engineering snippets you might even wish to bend the graph to mould around a 3D representation of the car - not actually as zany as you might think - I used to write industrial level 3D CADCAM software professionally - large systems embed a DB including cost of materials, part information, production info, engineering info onto the graph that holds the topology and geometry for the model of the car. Perhaps a digression - perhaps not depends how you think about graphs and your preferred way of relating to the graph and seeing connections and relationships.
3 Likes
I have custom buttons to order tiddlers not only in terms of most linked to ( count back links ) and number of star ratings (rating plugin) but also buttons to show the tiddlers that are linked to least, have least stars and so on - also untagged tiddlers.
I don’t think it’s the ideal solution and I find it requires a bit more enthusiasm to do a random trawl of ‘neglected’ tiddlers but that’s my fault and perhaps human nature.
2 Likes
Yes, it is the human condition we need to come to terms with, rational or not.
The approach I have described with TiddlyWikiPharo allow us to see the tiddlers in a graphical way, outside of TiddlyWiki with a custom query language, provided by Pharo.
TiddlyWiki is more the fluent web front end of the personal knowledge management and Pharo is more the backend for visualization, querying and programming (without JavaScript). So far it has been a good combination without any 3D/VR externalities.
2 Likes