These are the types for images I found
Github images
Acutual html mark up is given below
<a href="https://user-images.githubusercontent.com/67494083/183275174-ad3dfe37-cf0d-4eff-a7ff-cfa83145a4a0.jpg" rel="noopener noreferrer"><img style="max-width: 100%;" alt="Screenshot_20220807-095033_Chrome" src="https://user-images.githubusercontent.com/67494083/183275174-ad3dfe37-cf0d-4eff-a7ff-cfa83145a4a0.jpg"></a>`
But on wikitext conversion it appears like this. Image is seen, but an additional link appears below the images with an additional [[ is seen before the image.
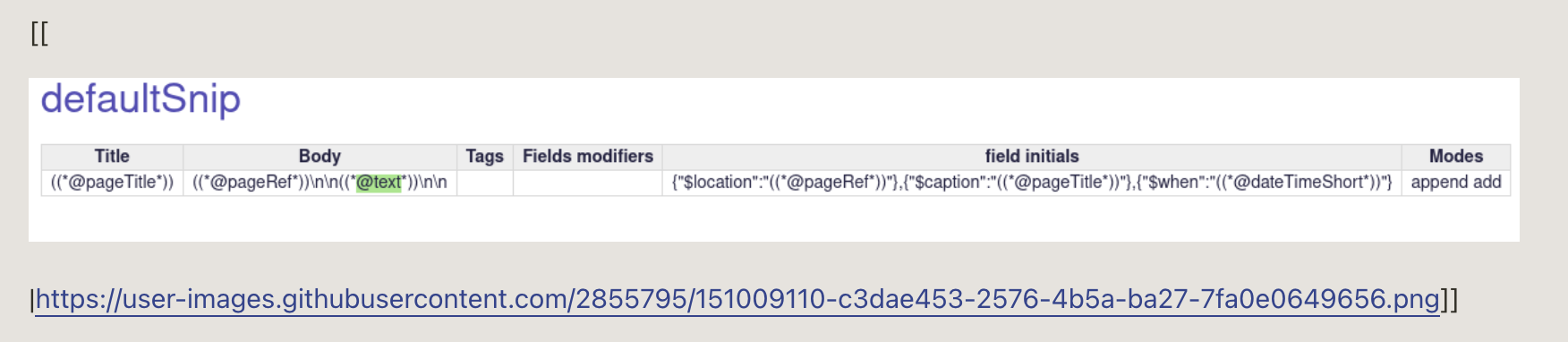
[[
[img[https://user-images.githubusercontent.com/67494083/183275174-ad3dfe37-cf0d-4eff-a7ff-cfa83145a4a0.jpg]]
|https://user-images.githubusercontent.com/67494083/183275174-ad3dfe37-cf0d-4eff-a7ff-cfa83145a4a0.jpg]]
Article from a rad website
Acutual html mark up is given below
<img loading="lazy" alt="Figure." title="" data-lg-src="/cms/10.1148/rg.2018170097/asset/images/large/rg.2018170097.fig1.jpeg" src="https://pubs.rsna.org/cms/10.1148/rg.2018170097/asset/images/medium/rg.2018170097.fig1.gif" class="figure__image"><figcaption><strong></strong><span class="figure__caption hlFld-FigureCaption"><p><span class="captionLabel">
But on wikitext conversion it appears like this and image appears broken.
[img[/cms/10.1148/rg.2018170097/asset/images/large/rg.2018170097.fig1.jpeg]]
If I manually add https://pubs.rsna.org before the /cms/10.1148/rg.2018170097/asset/images/large/rg.2018170097.fig1.jpeg the image becomes seen again.
Can a special rule be added for the above two behaviours in the macro ?
It must be something similar to these right.
/* ANCHORS */
pattern = new RegExp ("<a [^>]*?href=\"(.*?)\".*?>(.*?)</a>" ,"gi") ;
intext = intext.replace(pattern, "[[$2|$1]]") ;
/* SPANS */
pattern = new RegExp ("<span *.*?>(.*?)</span>","gi") ;
while(intext.search(pattern) > -1) {
intext = intext.replace(pattern,"$1") ;
}
/* IMAGES */
pattern = new RegExp ("<img.*?src=\"(.*?)\".*?>" ,"gi") ;
intext = intext.replace(pattern, "@@[img[$1]]@@") ;
Images from many other websites are clipped somewhat correctly.