Thank you, @CodaCoder – I’m happy to discuss, with the caveats that 1), this will not be a comprehensive discussion of the topic at this time and 2) I do not use my TW to handle especially sensitive information, i.e. information I wouldn’t be more than mildly embarrassed about (such as personal reflections). It should go without saying that if you handle national security secrets, for example, you shouldn’t include this plugin in your wiki.
Minor note on point 2, however, my understanding leads me to believe that one of the most exciting parts of MWS would be that sensitive data kept in one bag could be viewed in the context of a recipe that also includes a general bag full of less sensitive, and the bag containing the sensitive data could also be kept separate from the recipe which includes access from a non-local LLM
To your point, broadly:
When making an API call with OpenAI, inputs are no longer used for training unless one applies for that through a multi-step process. This is different than if one uses the ChatGPT interface in which one has to opt out of training data. There is definitely real concern for the gen-pop user who might be discussing sensitive work data with ChatGPT through the web-interface who may not have gone to the trouble of opting out - - it has been documented time and time again that LLMs are especially sensitive to “coercive behavior” designed to override their usual protocols. That said, I am not especially concerned in this context about data being passed through API calls being accessible via one of these methods of attack.
The particular behavior the article you link to in your post, (Invisible text that AI chatbots understand and humans can’t? Yep, it’s a thing. - Ars Technica) does make clear that OpenAI API calls do not include sensitive information within invisible text and therefore its users are not susceptible to the potential security threats related to that.
This, to my eye, is one of the most important reasons to opt for OpenAI (API calls specifically) at this time (though I do like Claude, for example, for certain tasks): Because they have “all-eyes-on-them” as the big name in ML tech (I don’t include Google because it is so diversified whereas OpenAI is “all-in”) they have an especially strong interest in finding strategies to avoid major security pitfalls such as the invisible text problem described. I have seen @linonetwo suggest Anthropic API calls - - at this time, I would not use Claude for contextual searches such as those enabled by this plugin.
Now:
There is a cache of information that is very relevant to this conversation but I have not mentioned yet - - pretty recently, OpenAI began caching common user prompts that are made through API calls. This cache is tied directly to your API key - - if someone had your API key, they could certainly access this cache through coercive prompting.
However, the larger point here is that, if you have structured your prompts well (in this case, you would want the system prompt, which is generally static, to precede the user prompt, which is usually dynamic) the agent will select to pull that information from the cache rather than handling it as original text to process (again, broad overview of the behavior). This means (generally) that, once someone has run the same prompt multiple times, they will avoid having to pay for processing the same system prompt multiple times, and they will only have to pay for the original content.
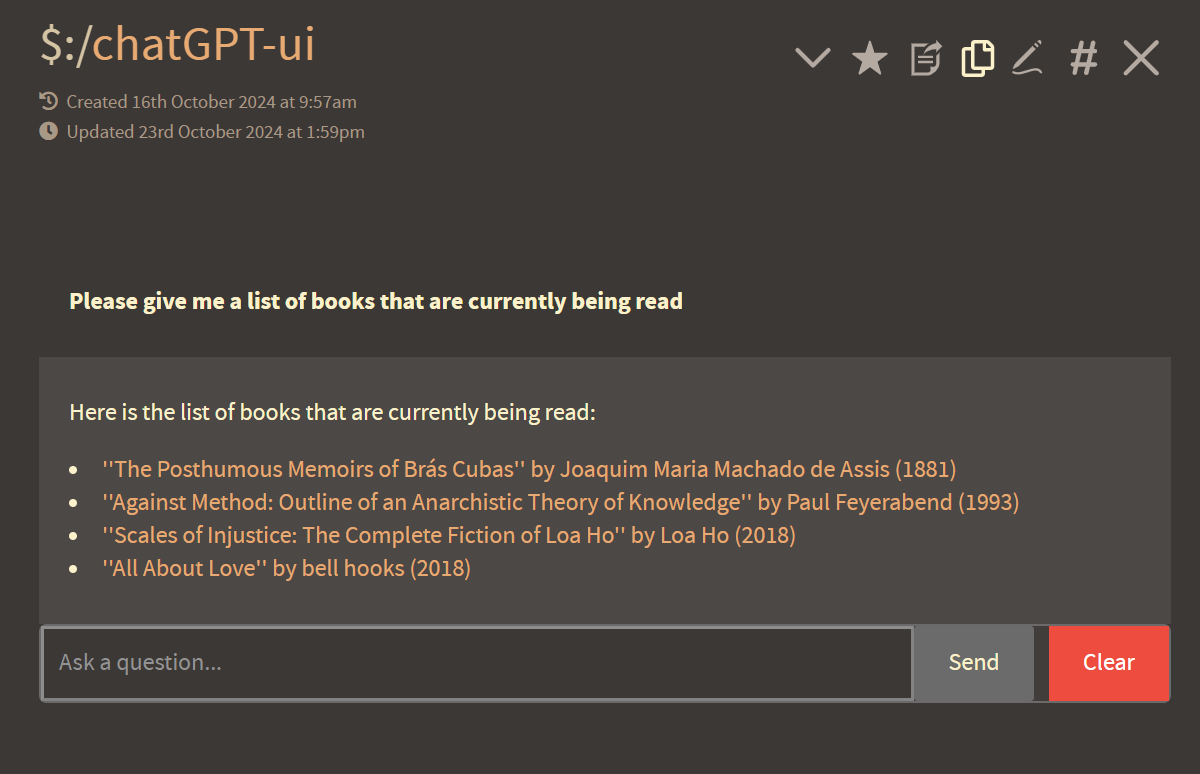
For example, I use a script that processes all of my reading notes from a plaintext format:
Exported from Boox
Into individual jsons which are formatted for Tiddlywiki and contain all the tags:
Individual JSON format created by running python script which reorganizes information via openAI api call to gpt-4o-mini
I have a pretty detailed (and extensive) prompt which I have developed over time to produce incredibly consistent results using even small models like gpt-4o-mini – The script I’ve developed passes this (static) system prompt through the API call first, and then extracts the characters from a .txt file in order to reprocess them.
Since I do this nearly every day to import notes into my wiki, the system prompt is cached (and tied to my unique API key) so the system recognizes that it can skip over that content – then I am only paying for the dynamic content which are my notes (usually this costs less than a cent a day even for multiple chapters across multiple books).
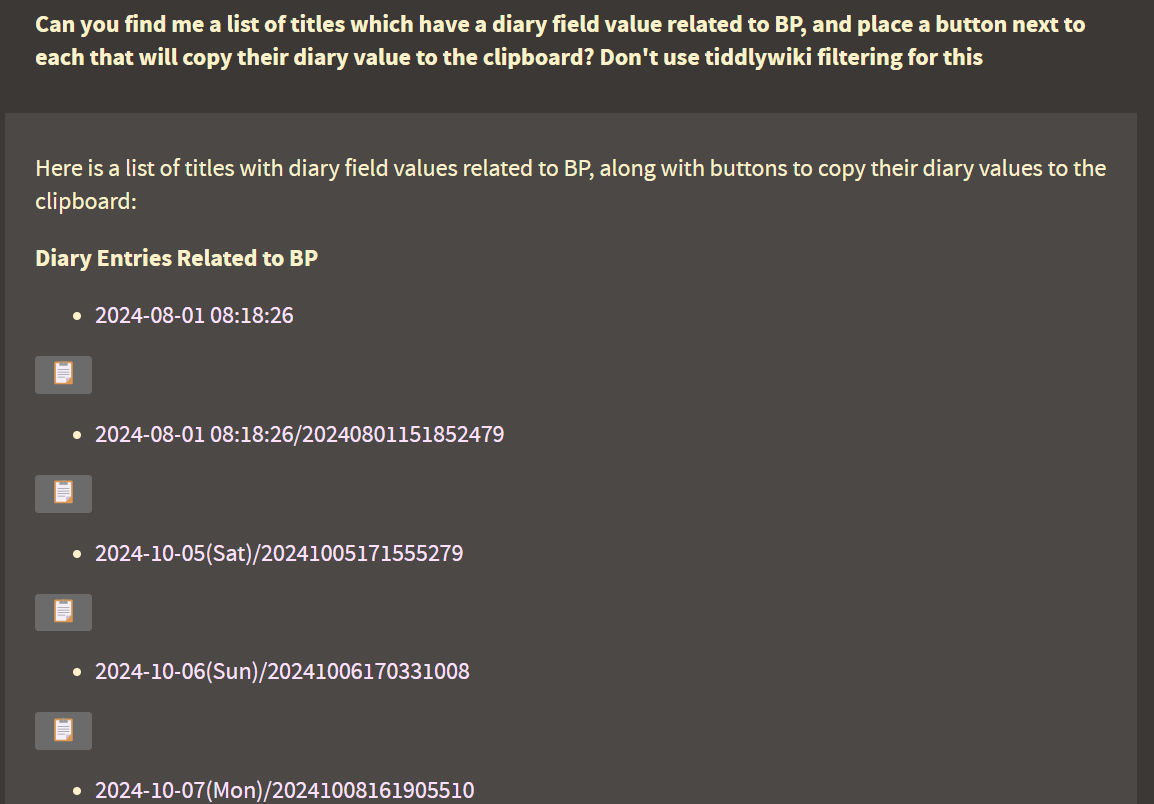
For our purposes here, it means that we can have a very extensive system prompt – say, one that explains how Tiddlywiki works, how the agent should respond to different situations, a full and detailed list of its capabilities, a set of fallback instructions for handling unique or unfamiliar situations, etc, without the cost becoming excessive in the long run, and, as long as you don’t share your API key could even include personal information.
It is therefore important, when developing a strategy like this, to make sure that all static prompting precedes dynamic prompting




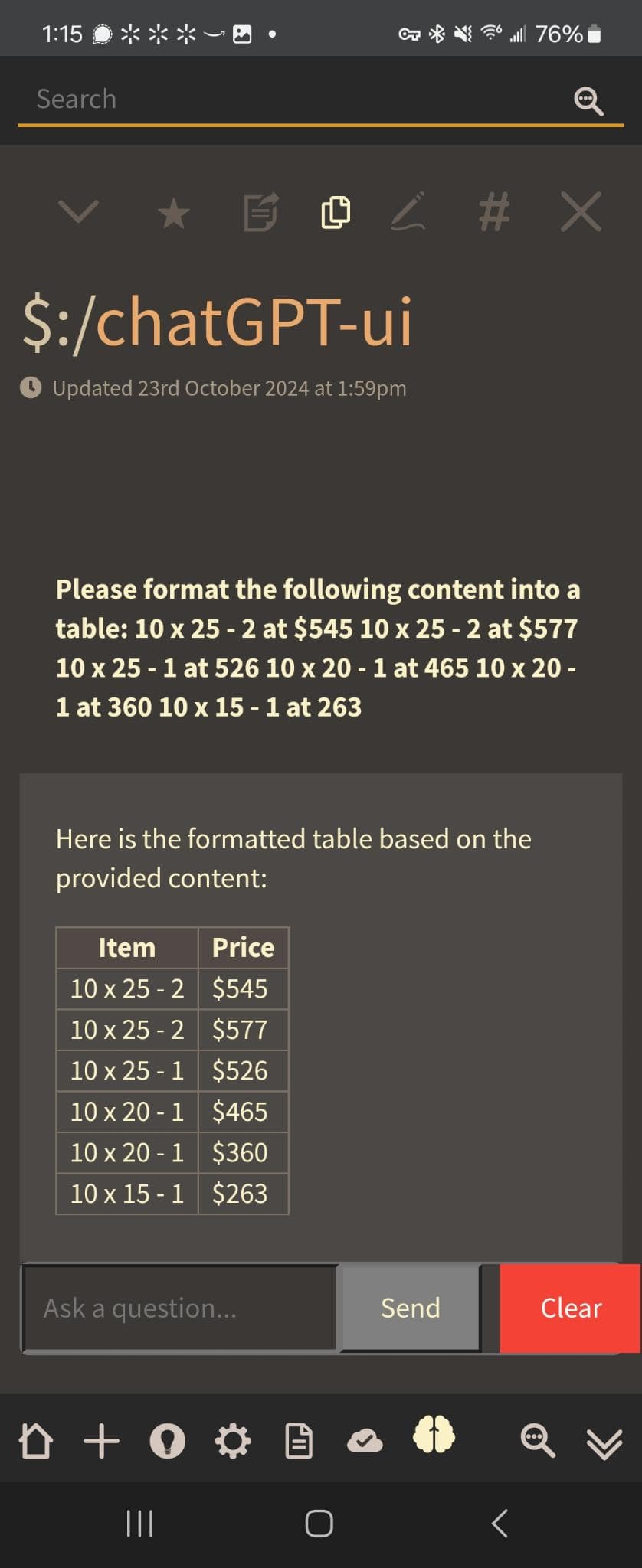



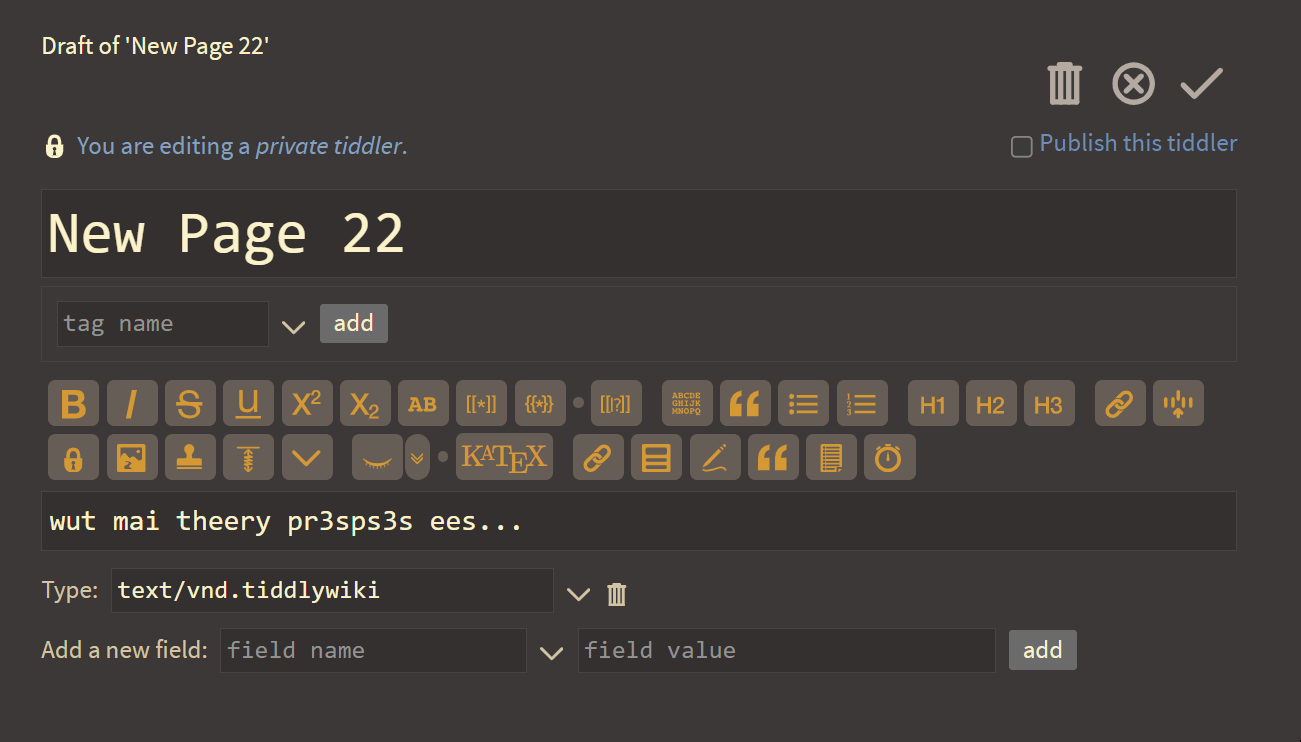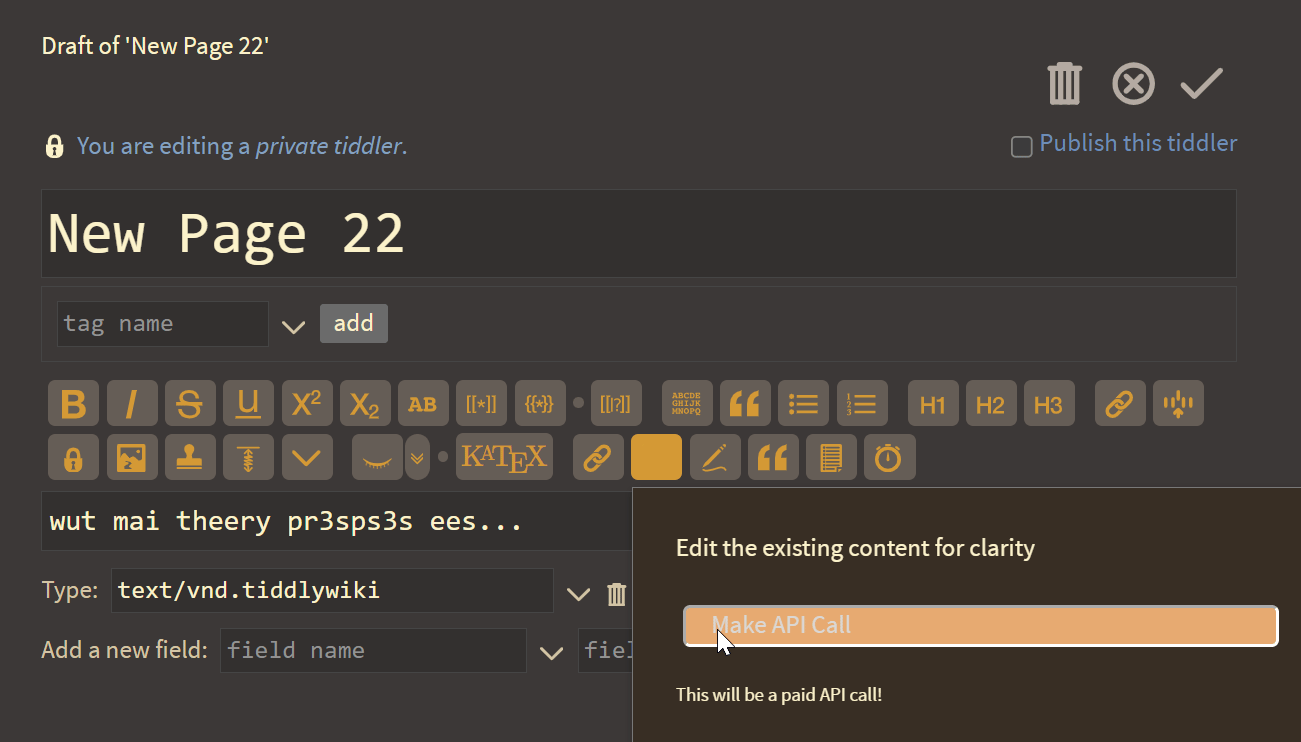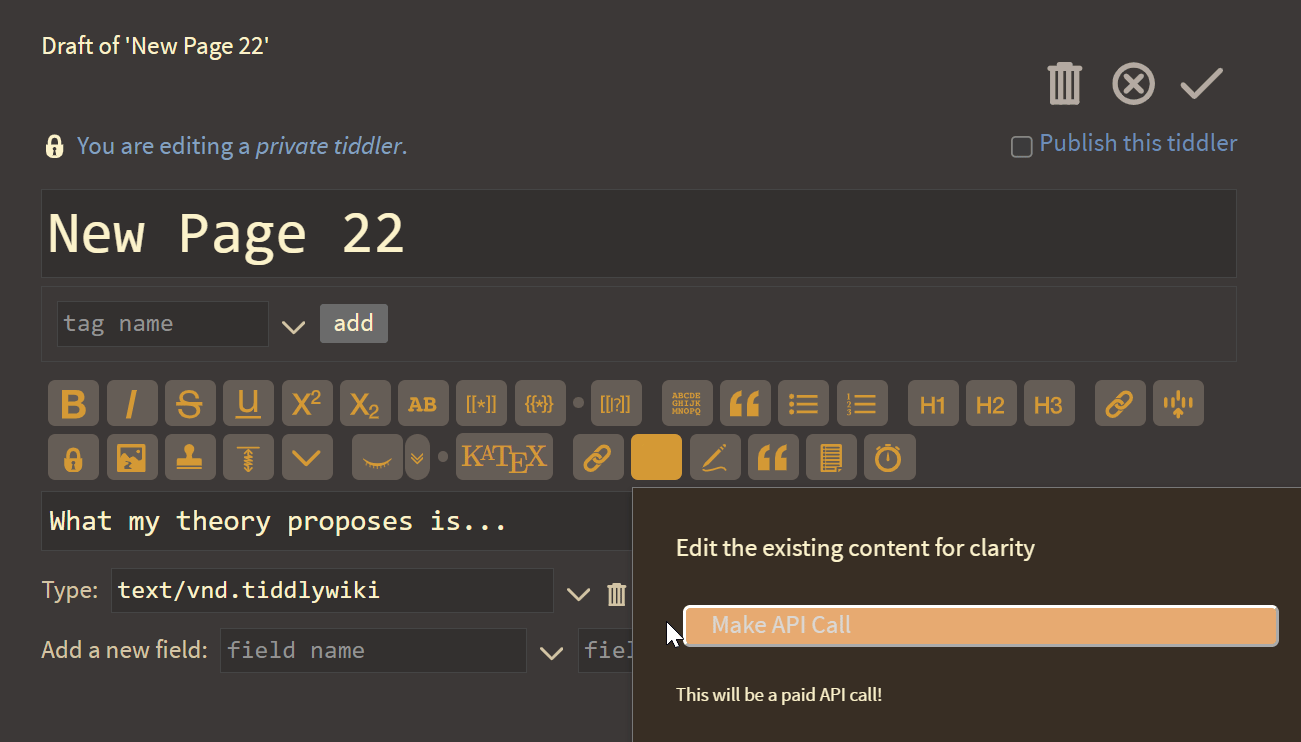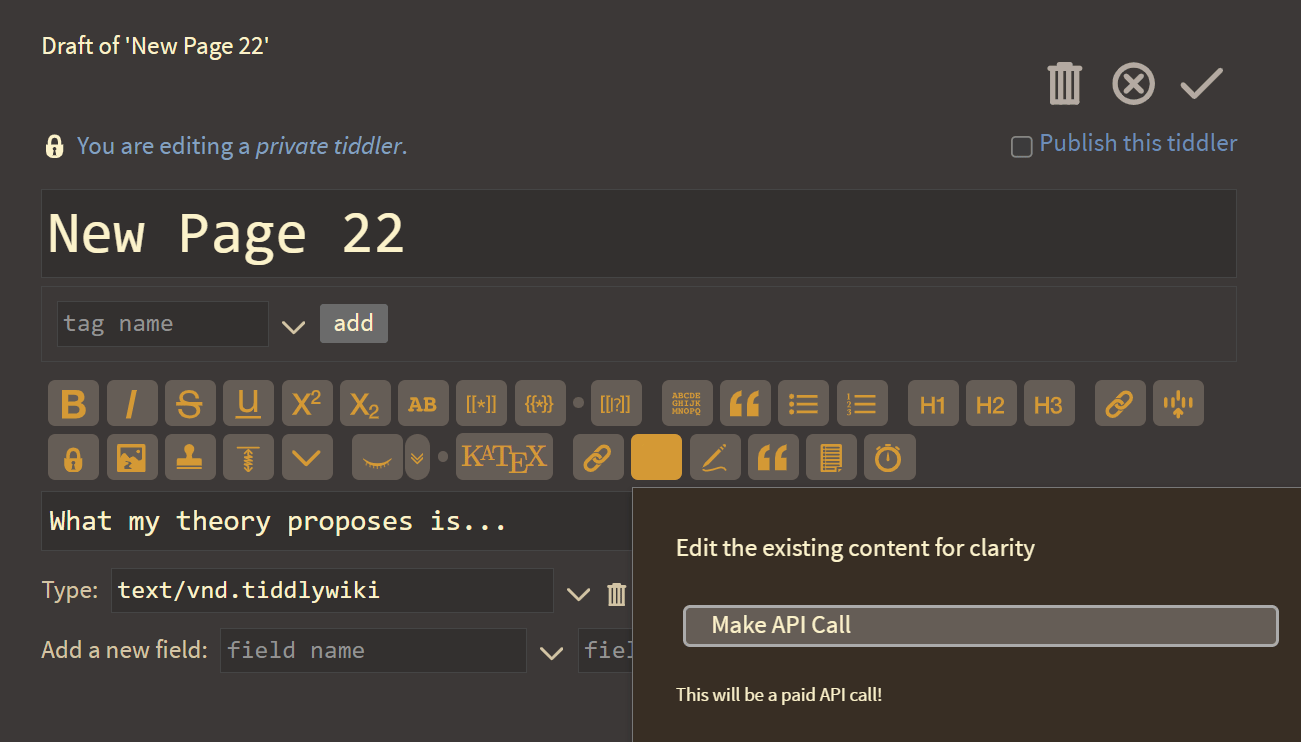
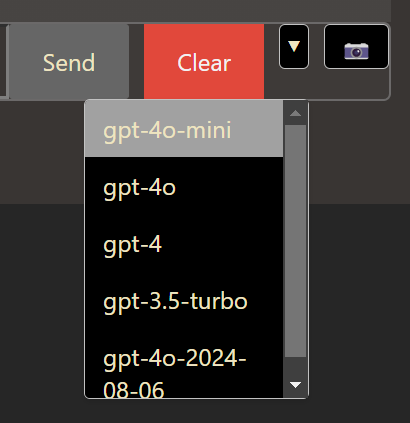
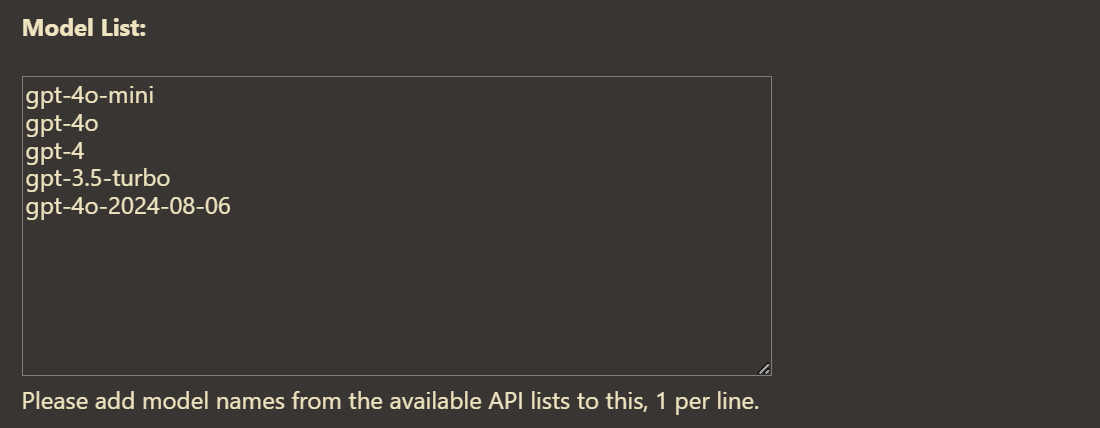
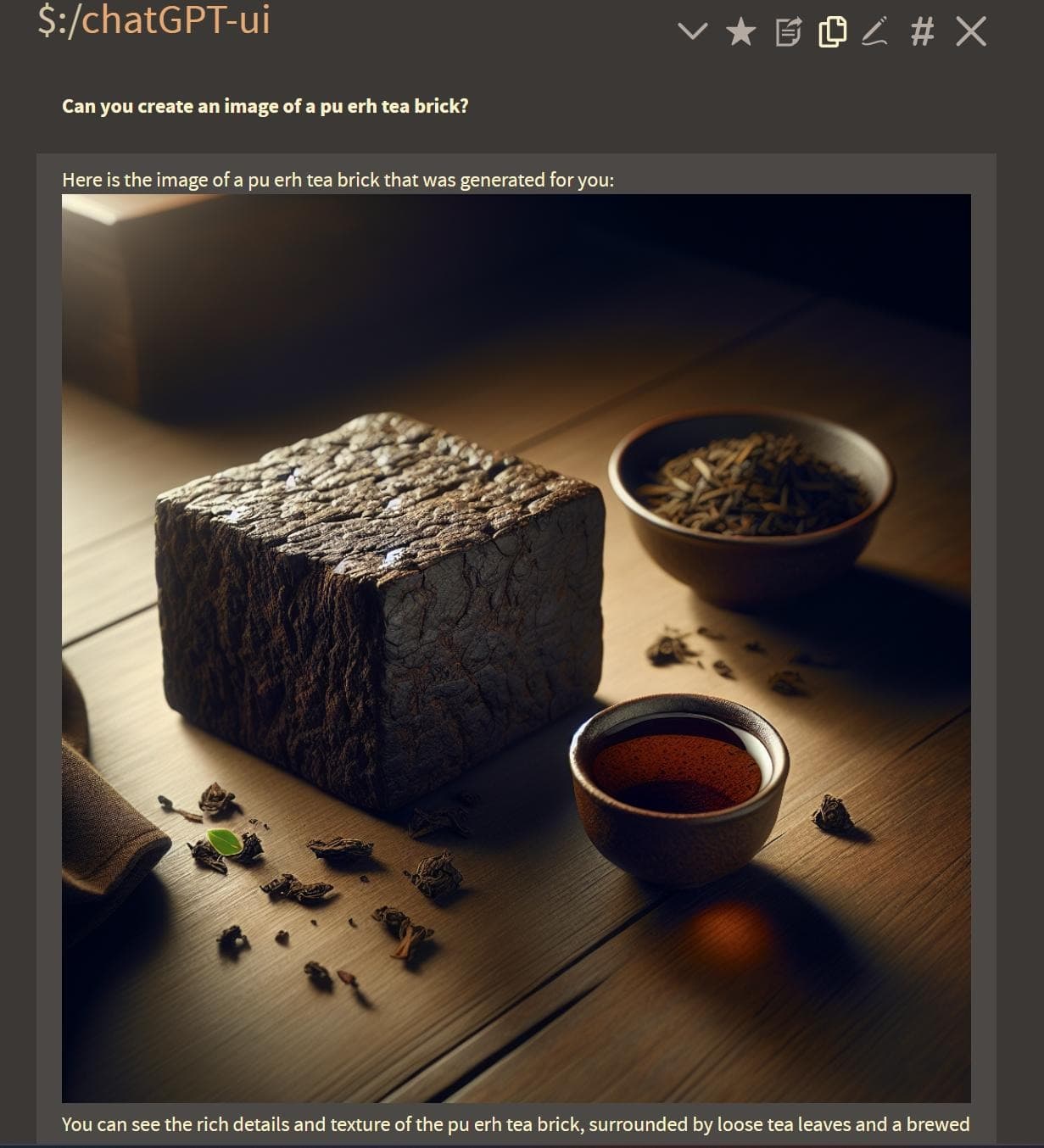

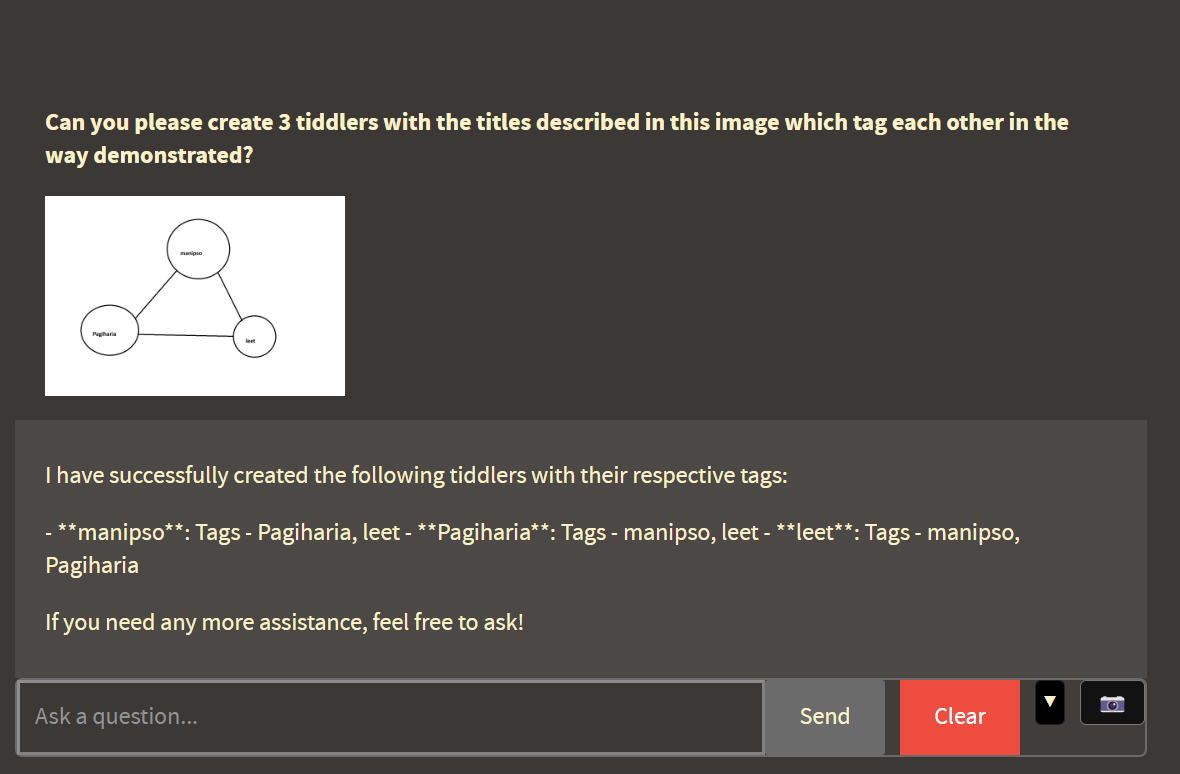


 And here I thought the best touch was pasting to upload
And here I thought the best touch was pasting to upload