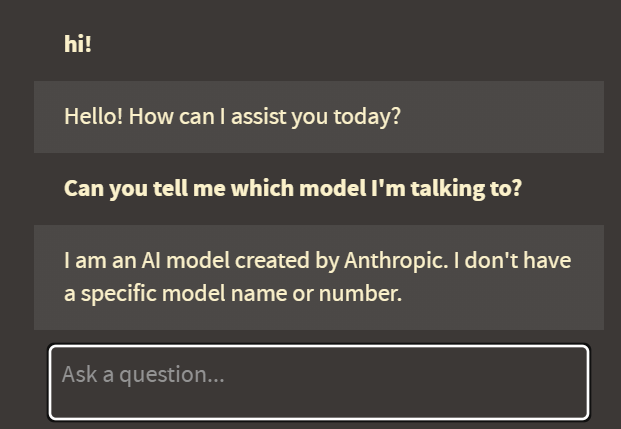
Hey all, it’s been another 2 weeks, so I’m obviously going back on what I’ve said and releasing another version of the plugin:
$__plugins_NoteStreams_Expanded-Chat-GPT (0.9.8).json (199.7 KB)
This is a major update with significantly improved functionality and several new features that should not interfere with its previous features, but please read the documentation to see all of which it’s capable.
Great! So, what’s in this update?
To begin, you will see several new options and improvements in the user interface.
First, you will notice the button container will now wrap underneath the text box when the screen size is reduced – this is especially noticeable on mobile or in the sidebar, but also works in the story river if you reduce the screen size.
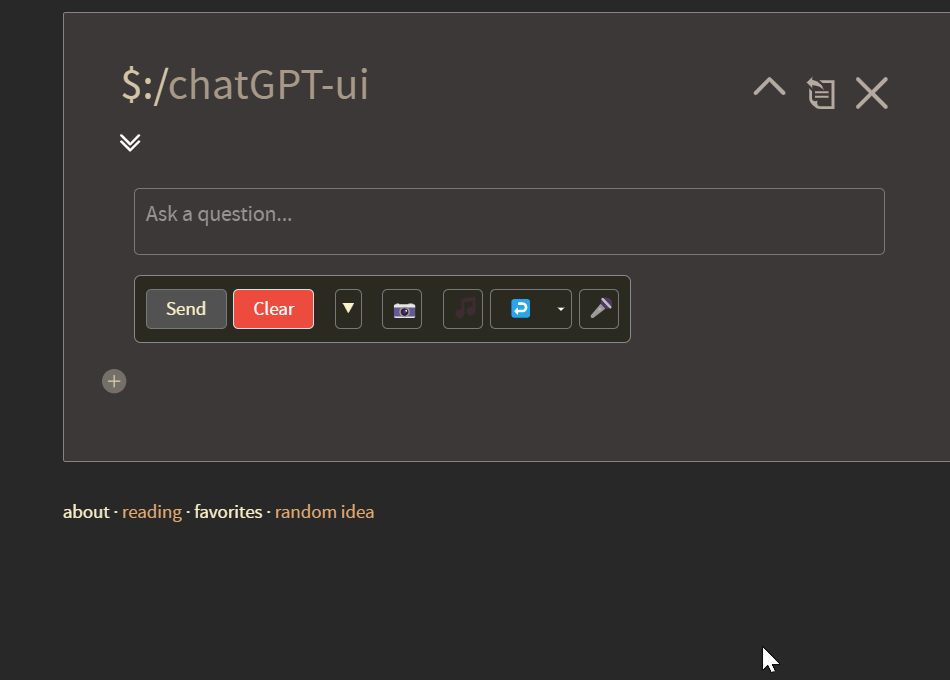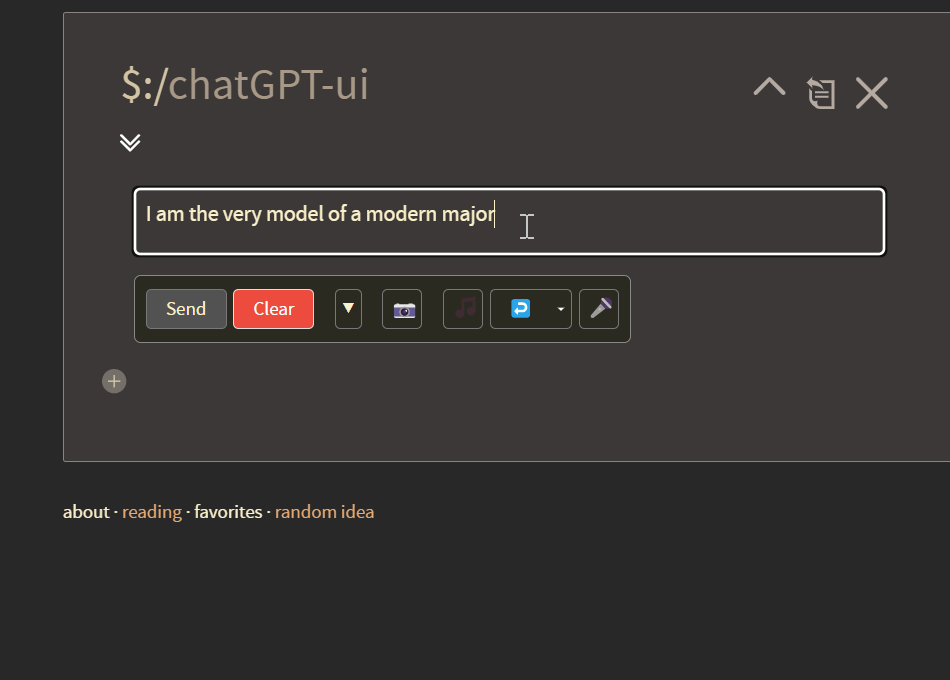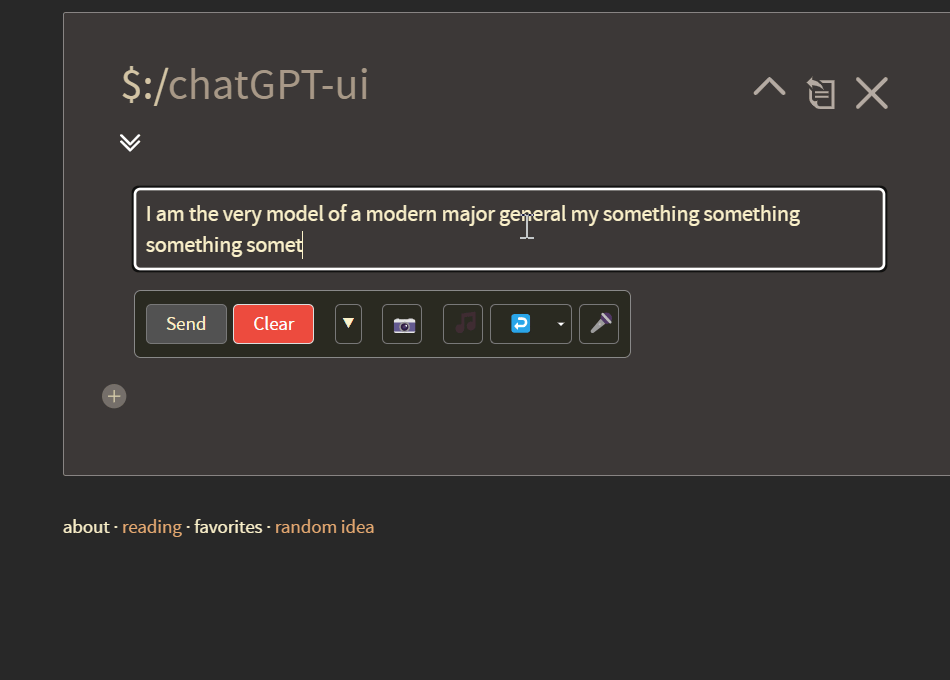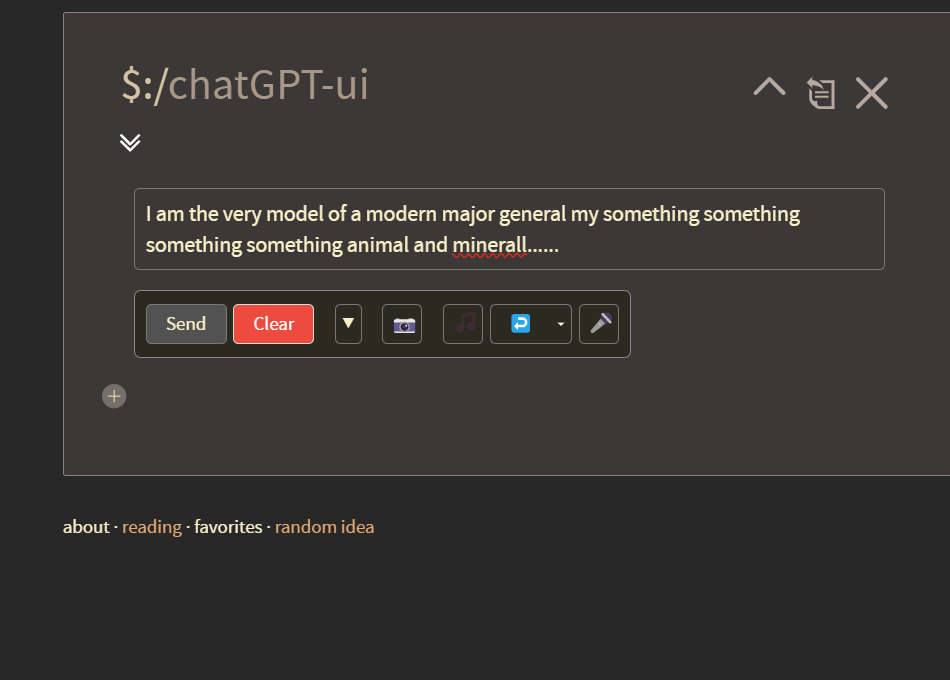
As you also can see, this update also implements a flexible text field, which will expand to the size of your user message.
And, of course, you’ll notice several new buttons:
-
Microphone button: Begins voice recording in browser which automatically stops and transcribes when you stop speaking (This uses openAI’s Whisper system, which will charge your openAI account)
-
Musical Notes: Allows the user to upload an audio file which will be transcribed as above
Additionally, you will see that the undo button now has a dropdown next to it:
Building off the previous update, this update expands the undo functionality so the user can either undo individual actions, or undo entire queries
Here you see a multistep query which can be undone in one step rather than clicking the undo button multiple times.
I believe that this is a superior solution to giving the agent undo capabilities, giving the user the opportunity to resolve a mistaken response manually rather than engaging in continued dialogue.
The number of incorrect actions the agent might take is greatly reduced by an extensively improved transaction-based validation system, which checks the intended action against the results, rolls back unintentional changes, and retries. As a side effect, this should greatly reduce the possibility of the agent reporting actions being done which have not succeeded.
If you are going to be performing more complex, multi-step operations with ambiguous steps, I highly recommend toggling on one of the newest options, adversarial agent, with the following invocation:
<$chat-gpt adversarial="yes"/>
The adversarial agent acts as a gatekeeper at the very first step when the agent tries to perform an action – a small model (gpt-4o-mini in this case) compares the first agent’s proposed action array against the user’s original query, and returns (to the 1st agent) a boolean (allowing or disallowing an action) as well as an explanation of why it has done so and suggestions for how it should proceed.
Not only does this act to prevent unnecessary or incorrect actions from taking place, it also helps to keep the 1st agent on track, when performing several actions. For example, the adversary might say “I’ll allow this, but remember you still need to do these other things in order to fulfill the request.”

This exchange between the two agents as observed in the browser console
Behind the scenes, there are quite a lot of changes:
- each of the major groups of function types have been split off into separate modules and classes, and each has been improved in its own way.
-
Connection pooling has been implemented, which vastly improves response speeds from the server
-
Caching service temporarily stores the results of recent searches, vastly improving information retrieval by the agent.
- Managing interactions between all these different modules is the service coordinator, a module which is invoked when the agent tries to perform an operation that involves both actions and validation.
Finally, (I think), this update introduces Text-to-Speech capabilities for the agent, which can be enabled with <$chat-gpt tts="yes"/>
In this mode, the button container will be expanded to include a dropdown to allow the user to select a voice. When a response is posted by the agent, it will be accompanied by a voice response (an openAI service that will be charged to the user’s account).
This is a significant update and I wouldn’t be surprised if there would be fixes to make – please report and I will do so promptly  I’m extremely happy to answer any questions and engage in discussions about how this plugin can be incorporated into ones workflow, as well as features for the future and problems one might encounter.
I’m extremely happy to answer any questions and engage in discussions about how this plugin can be incorporated into ones workflow, as well as features for the future and problems one might encounter.
As I’ve made most of the significant updates and the system is working fairly well, this is essentially a Verison 1.0.0
Going forward, the areas I will be looking at will be incorporating anthropic and oLlama models as options… and I will likely post more about my specific thoughts about that at a later point… but, that said, semantically, the “Expanded ChatGPT Interface” plugin name will have to change, making this possibly the “last” major update.
Cheers!

 )
)