
1. feature-name
“Universal plugin for tiddlywiki backup service” [concept, discussions]
2. feature-description
- My idea is just to integrate these existing plugins into a single plugin that I call “universal backup tiddlywiki” or “ubt” or “tiddlywiki.backup” or “tiddlywiki.services” or “tiddlywiki-connector” or “tiddlywiki.connection” or “tiddlywiki.odbc”
- It will be an abstraction layer that turns on/off the plugins responsible for synchronizing remote services description-plugin
- For this to be possible, it will be necessary to connect all types of existing backup and backup control services as GitHub, Google Drive, Microsoft Access, SQLite, Firebase…
2.1 concept
2.1.1 concept 1
Diagrams.net, Rclone, Mysql Connector, ODBC…
2.1.2 concept 2
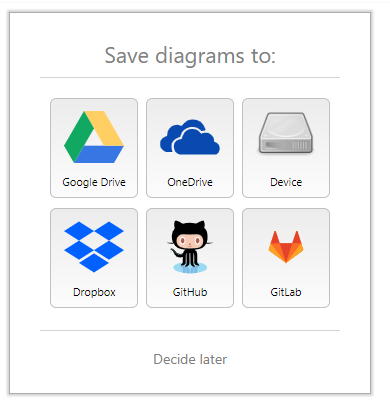
2.1.2.1 Image description
We can see in the image that we have different connections to different services to synchronize your data.
3. FAQ - Frequently Asked Questions
3.1 - Why this feature?
- Some software that has this feature https://app.diagrams.net/ , rclone etc. That is, there are already technological solutions that have this concept that I describe here
- This can make life easier for users and the community.
- My idea is to make tiddlywiki more commercially usable: my ideas are these: universal backup plugin, tiddlywiki redesign,
- This ensures reliability, integrity, interobility, stability of tiddlywiki
- It’s something that’s already been asked a lot in old and newer Tiddlywiki threads.
3.2 - What will be the license of this plugin?
MIT
3.3 - How will this plugin be implemented?
- So… this is just an interface, an abstract layer - my idea is that below this layer I use the plugins for what I need. In other words, I don’t know if the plugins they use are from third parties
- It will be written in javascript programming language (current version of ecmascript 2019 language)
- Perform tests on each access permission to third-party plugins in a unitary way
3.4 - Is safe?
- Yes and no… because… all services being used are from third-party plugins, however, if there is interest from developers, this may be “official”
- yes… because… license is MIT (open-source).
3.5 - This has already been implemented, done?
I’m thinking about this personal concept, I still don’t have any development ideas - but I’m creating the concept, documentation for it
3.6 - Is the plugin paid?
It’s not paid, just community support.
3.7 - Features?
- Multi sync: Google Drive, firebase , Dropbox, GitHub Server, WebDAV, Saving on Sharepoint Online\Onedrive
- Multi control version: git, file-backups, json
- Automatic Backup
3.9 - todo to… do or task description\status
- Create data abstraction layer ‘done’
- Create plugin ‘do’
- Create documentation plugin doing
- Discuss plugin concept/idea for tiddlywiki community doing
- Check negative or positive feedback received about the implementation of the tiddlywiki universal backup plugin
- Perform tests on each access permission to third-party plugins in a unitary way
4 - Requirements?
- Create plugin to manage access to third-party plugins
- Check access to third-party plugins
- Check third-party plugin permissions
- Alerts the user to access certain information that is required by the third-party plugin, such as username, email or password if this access permission is required.
- Check if the implemented plugin complies with the necessary technical specification
- The plugin will be written in the client-side javascript programming language and should only work in the latest browser.
- Perform tests on each access permission to third-party plugins in a unitary way
5. Deadline
I don’t have time to develop, so there’s no deadline. The deadline here is sporadic, that is, when I have time, I will implement it little by little.
6. References?
- https://groups.google.com/g/tiddlywikidev/c/2WN2b6uCxJ8
- https://github.com/neumark/tw5-firebase
- https://neumark.github.io/tw5-firebase/
- https://tiddlywiki.com/static/The%20First%20Rule%20of%20Using%20TiddlyWiki.html
- https://groups.google.com/g/tiddlywiki/c/oG2L7OXhUoI
- https://groups.google.com/g/tiddlywikidev/c/CntXt-pih8g
- https://github.com/ibnishak/Timimi
- How do you backup your wiki and keep it safe?
- https://github.com/Jermolene/TiddlyWiki5/issues/2759
- https://groups.google.com/g/tiddlywiki/c/Zo3NJR-aJZ8
- https://www.reddit.com/r/TiddlyWiki5/comments/ouxt0v/fewer_backup_files/
- https://github.com/twcloud/dropbox
- TiddlyWiki5 in the Sky using Dropbox
- twcloud · GitHub
- https://tiddlywiki.com/static/Saving%20on%20iPad%2FiPhone.html
- https://tiddlywiki.com/static/Saving%20via%20WebDAV.html
- Use WebDAV for saving a single file wiki
- https://tiddlywiki.com/static/TiddlyWiki5%20Versioning.html
- https://tiddlywiki.com/static/PluginMechanism.html
- https://www.reddit.com/r/TiddlyWiki5/comments/jrc9o9/best_way_to_version_controlbackup/
- https://tiddlywiki.com/static/PluginMechanism.html


