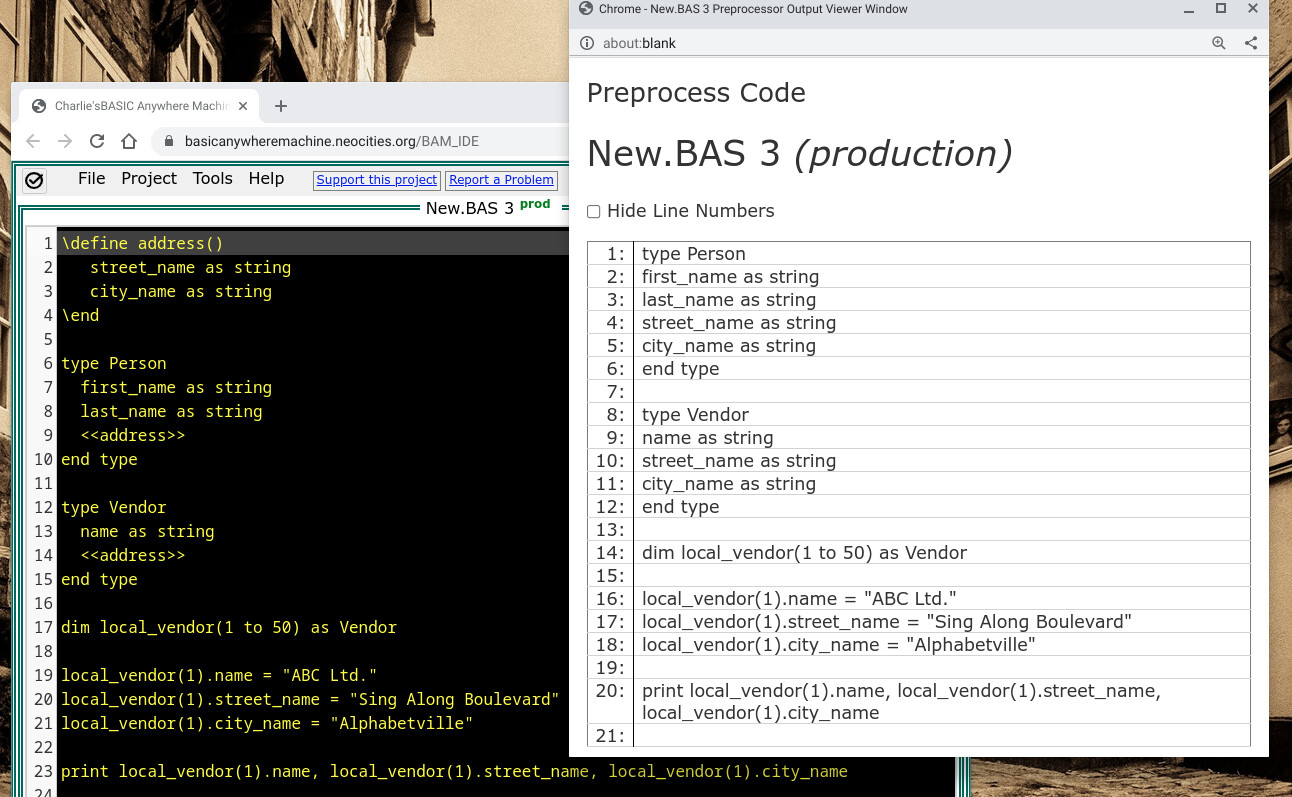
In the screenshot below, it is an extremely simplistic use case.
Imagine TiddlyWiki having whatever content in whatever tiddlers and whatever fields, being able to pull that together to generate a program in whatever programming language.

In the screenshot below, it is an extremely simplistic use case.
Imagine TiddlyWiki having whatever content in whatever tiddlers and whatever fields, being able to pull that together to generate a program in whatever programming language.
Charlie Veniot wrote:
In the screenshot below, it is an extremely simplistic use case.
Imagine TiddlyWiki having whatever content in whatever tiddlers and whatever
fields, being able to pull that together to generate a program in whatever
programming language.
I’m afraid I don’t understand what you’re suggesting. Do you want to generate
source code as the rendered output of content in one or more tiddlers?
Something else?
– Scott
Picture a database modelling tool in which you model a database and with which you export the DDL script which can create a database.
Same kind of thing with TiddlyWiki to export (or forward-engineer) a program in any programming language.
Your TiddlyWiki is used to model everything needed for a program. Maybe the model involves pseudo code and or whatever other modelling bits and pieces organised however makes sense in however many tiddlers and fields… Press a button, and you have the code for a program which you can copy and paste into an IDE, or export to a file, or whatever.
Well, not just programming languages.
Anything at all.
I had started a long while ago, but lost interest in, a natural language tool (a TiddlyWiki) for modelling data domains with the goal of generating DDL script for database creation.
Imagine you have created a very cool app of some kind, and you’ve decided you want to provide an English version of it and a French version of it. (or pick whatever languages, and however many.)
You’ve decided to store the source code in TiddlyWiki, and you are using that TiddlyWiki as your data store for all text presented by your app (labels, instructions, etc) in each of the languages of interest.
From TiddlyWiki and your one version of the source code, you can export a version of that source code for each of your languages of interest, the export taking care of doing just-in-time substitution of all placeholder text with the text related to the language of the export.
The Auto Biaxial Symmetry Graphing Personalizer takes a template BASIC program, adjusts it as per click-and-choose settings, and allows exporting a version of the program that matches the settings.
Charlie Veniot wrote:
Scott Sauyet wrote:
Charlie Veniot wrote:
In the screenshot below, it is an extremely simplistic use case.
Imagine TiddlyWiki having whatever content in whatever tiddlers and
whatever fields, being able to pull that together to generate a
program in whatever programming language.
I’m afraid I don’t understand what you’re suggesting. Do you want to
generate source code as the rendered output of content in one or more
tiddlers? Something else?
Picture a database modelling tool in which you model a database and
with which you export the DDL script which can create a database.
Same kind of thing with TiddlyWiki to export (or forward-engineer) a
program in any programming language.
Your TiddlyWiki is used to model everything needed for a program. Maybe
the model involves pseudo code and or whatever other modelling bits and
pieces organised however makes sense in however many tiddlers and
fields… Press a button, and you have the code for a program which you
can copy and paste into an IDE, or export to a file, or whatever.
I’ve almost never found such tools to be worth my time when trying to
write any general-purpose language. Even GUI builders end up a waste
of time as far as I’m concerned.
The only exception would be in LISP-style languages, but then the
higher-level language is the same language you code in; true macros
are extremely powerful!
to export (or forward-engineer) a program in any programming language.
If you mean that the same inputs would be able to generate a VB program,
a Haskell program, one in Prolog, another in Scheme, as well as ones
in Ruby, Squeak, Idris, Agda, Num, Julia, and Elixir, then I very
seriously doubt it, or your input will have to be so broad and so
variegated as to be meaningless.
So while I wish you luck in this, I personally don’t hold out much
hope for such an endeavor.
– Scott
Scott Sauyet wrote:
to export (or forward-engineer) a program in any programming language.
[ …]
a Haskell program, one in Prolog, another in Scheme, as well as one
in Ruby, Squeak, Idris, Agda, Num, Julia, and Elixir, then I very
seriously doubt it, […]
s/Num/Nim. Sorry
Charlie Veniot wrote:
Imagine you have created a very cool app of some kind, and you’ve
decided you want to provide an English version of it and a French
version of it. (or pick whatever languages, and however many.)You’ve decided to store the source code in TiddlyWiki, and you are using
that TiddlyWiki as your data store for all text presented by your app
(labels, instructions, etc) in each of the languages of interest.
Most general-purpose languages already have libraries for this; I don’t
see what TiddlyWiki would add, unless it can offer a nicer way to edit
your language configuration.
I don’t mean to throw cold water onto your idea, but my personal
experience does speak to this being a dead-end. I really do wish you
all the best with it, but I’ve been disappointed enough that I feel
no inclination at all to join in.
– Scott
That’s the kind of wish that leaves a foul odeur de je-ne-sais-quoi in my cornflakes.
Whatever I did to you to deserve that stick in my “what if” wheels of fun thinking, my apologies.
Transpilers come to mind. Compilers too.
If it is possible to transpile from one language to another successfully. If it is possible to compile from one language to another successfully.
It doesn’t matter what the source language is. Pseudocode, models, etc. They are just other languages. So transpile from anything to some language … why not?
Kind of funny, this came to mind: James May Explains What Happens If You Drive A Car In Germany Without A Licence | The Grand Tour - YouTube
The idea of creating a perfect model for something is very appealing. Having a wiki then be able to accept parameters that use the model to generate “source code” (or whatever) is both noble but idealistic, so here goes…
I created a wiki that creates SVG scribbles (outlines) that represent shorthand, a version called Teeline. I started by creating for the most common English words. This idea expanded to creating outlines for combinations of words and even phonetic components of words.Well, this idea morphed into creating outlines for ANY phonetic component, using the IPA (International Phonetic Alphabet - International Phonetic Alphabet - Wikipedia). The next step is to vocalize the outline. I am trying to match this (developing) Teeline wiki with the Pink Trombone meme you may be familiar with. See Offline vocalization evolution using Pink Trombone and NEAT on Vimeo.
Virtually every dictionary provides the IPA code to clearly nail down the pronunciation of all words. This, of course, is not limited to English. Once I I have a wiki that “translates” scribbles into vocalizations, this can just as easily vocalize in EVERY language, just by grabbing the IPA dictionary entries for any language.
This essentially becomes a universal translator for vocalized language, as well as a way to write in a format that myself and a few friends (those of you reading this) can learn to read.
So, Charlie, I am not giving up on the philosophic thinking…
JWHoneycutt
Although I was singularly focused on computer programming languages, your area of interest is just as interesting and, I think, comparatively exponentially challenging (fun!) .
In my university days, I was always very focused on computer science, engineering (math, physics, stats), and business admin courses, I always wished I had the time for anything linguistics.
(Hmmm, I thought I responded to this. Disappeared in the ether, I guess!)
Charlie Veniot wrote:
Scott Sauyet wrote:
So while I wish you luck in this, I personally don’t hold out much
hope for such an endeavor.
That’s the kind of wish that leaves a foul odeur de je-ne-sais-quoi in my
cornflakes.
But I do mean it. I really wish you the best. I’ll be on the sidelines
cheering you along, celebrating your victories, mourning your failures. But
I’ve been heart-broken enough in trying this that I will never hold out high
hopes.
Whatever I did to you to deserve that stick in my “what if” wheels of fun
thinking, my apologies.
I think you’re likely to run into the same sort of insurmountable obstacles
that I have. But if you’re determined to stick to this course, all I can
do is cross my fingers and hope you see something I never did. I don’t
expect it; but if you manage it, I will gladly eat (some vegetarian
alternative to!) crow.
I mostly answered because I did want you to know that there are others
who’ve held similar hopes, even if mine have mostly faded. I never tried
this with TiddlyWiki. I don’t see that making a difference, but this tool
continually surprises me.
If it is possible to transpile from one language to another successfully.
If it is possible to compile from one language to another successfully.It doesn’t matter what the source language is. Pseudocode, models, etc.
They are just other languages. So transpile from anything to some language
… why not?
It is completely possible to store a model in TW that you could use to
generate code in some small set of languagues. As you say, that is what
compilers do, and basic compilers are relatively simple. (Optimizing
compilers can get arbitrarily complex.) What I don’t think is likely
is being able to create a high-level model system that will let you
quickly spin up new languages that will convert such models to source
code for that language.
Think of the differences between the models underlying COBOL and Prolog.
A single model that spans both idea-spaces would already be tricky
enough. Now add in Forth. Then Agda. I think very quickly you end up
with a model that either has no cohesion or is so abstract that the code
generators are impossible to get right.
I understand that Turing completeness means that a very large class of
languages – probably all we care about – can solve the same problems.
But that does not mean that converting between them or from some high-
level model is a tractable problem.
If you do try to pursue this, I would make one suggestion: don’t try
to solve one language up front and move on to the next. Instead try
at least three languages, ones with very different models. If you
can do this for some very limited domains (say “Hello, World”,
factorial, and basic arithmetic), then I think you might be onto
something useful. Then try expanding alternately in two directions:
adding some new feature you want your model to support, and adding
a new language, with a model as different from the existing ones
as you can. (Saying you can generate Java and C# isn’t saying much,
but saying you can generate Java and Prolog is much more impressive.)
Best of luck (and yes, I really mean that!)
– Scott
Hey, I wasn’t announcing a project to do that kind of thing.
It is just a shiny object, yet another interesting thought grabbing at my attention, and I was only hoping to find like-minded individuals who would like to talk about it, maybe suggest some related resources/happenings etc.
I’ve got way too many interesting things on the go to take on this kind of TiddlyWIki project.
This sounds to me like a form of literate programming, a style created by Donald Knuth. The only form I am aware of that achieved some popularity is Jupyter notebooks, but I don’t know whether Jupyter lives up to Knuth’s ideas.
pull that together to generate a program in whatever programming language.
In literate programming this would be called “tangling”. Taking the document you wrote and extracting a code file (or many) in a particular language (or languages).
The Emacs editor has this in org-mode with org-babel. It supports putting multiple programming languages in the same document, and interacting between them. A block of Python code can take its input from a block of shell code. I am not sure if it is unique in supporting multiple languages compared to other literate programming tools. If you follow your idea further, perhaps this could be a source of inspiration.
It doesn’t matter what the source language is. Pseudocode, models, etc. They are just other languages. So transpile from anything to some language
However your idea is definitely unique, as literate programming is focused on prose and not models, as far as I am aware. Org Babel sort of has this as it has its own data structures. It can represent lists, tables, etc. and knows how to get them from and feed them to a variety of programming languages. Org Babel becomes a glue that holds many languages together, so that you can express each idea in the language best suited to it, and present your ideas in an order best suited to being understood by the reader.
TiddlyWiki or a similar tool could take this further due to being a generic database.
In TiddlyWiki I find myself wishing for Emacs, and in Emacs I find myself wishing for TiddlyWiki. And I struggle to find time for learning more about related areas like TiddlyWikiPharo (and the tools it is built on like Pharo and Glamorous Toolkit), Lisp Machines, the Acme text editor (Video: A Tour of the Acme Editor), Plan9, Oberon.
I hope you or others find some of these links and ideas interesting and inspiring.
So much good stuff to read, so few hours in a day and way too short intermissions during the hockey games on tv tonight.
Thank-you !
Maybe a little bit out there, but all of this has me thinking about “Blockly” : Blockly | Google Developers
This is a neat example of programming in a non-technical way and having that generate code in any number of programming language.
(aside: A model doesn’t necessarily need to be graphical in nature. It can be a text model.)