
I’m exploring using Tiddlywiki as a reading (and maybe tagging) environment for my chatGPT conversation archive. OpenAI will export my chat library, giving me a few json files. Has anyone written a parser for this collection of files? Thanks! //steve.
I have a wiki with the markdown plugin. I create tiddler s with the title of my first question and using chat GPTs copy button paste the replies in the body text because the output is in markdown. The format is nice this way.
I may include follow up questions and answer in the same tiddler.
I also have a mechanisium to drop titles from an index table of contents on each tiddler to organise them however search and other methods help explore the information later.
1 Like
Interesting idea @stevesuny, that would be useful indeed. I took a very quick crack at it, largely just adapting the code from the chat.html file provided in the archive: Saq's Sandbox — Experimental doodads
To install, drag and drop the plugin header:
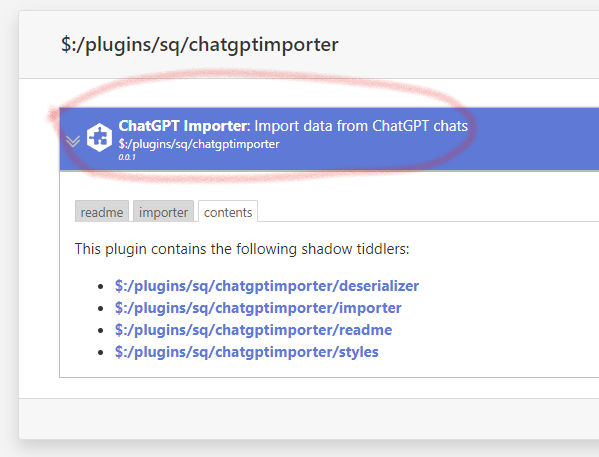
In my extremely limited testing it works reasonably well.
2 Likes
Saq, this is great (and quick!).
I tried it at https://chatgpt-conversations.tiddlyhost.com/ using both a renamed conversations.chatgpt and the generated conversations.json, using a downloaded empty.html from tiddlywiki.com
The chatgpt file imported into tiddlers; i got 172 tiddlers until the import was stalled by something. I also imported a new 1-conversation export that yielded the same results: tiddlers loaded with conversation titles with three fields each, and not what I guess might be called the child fields of the parent conversation. I’ve attached the 1-conversation conversations.json file to this message for anyone interested.
As far as I can find, there are no easy tools around to facilitate ingesting and reviewing (tagging, etc) chatGPT conversations, with the exception of a tool for notion.
Any further help would be much appreciated, and robustly tested!
Thanks,
//steve.conversations.json (20.6 KB)
Hi Steve, it seems like the default import behaviour is being used without the deserializer that I wrote.
Please try these steps at https://chatgpt-conversations.tiddlyhost.com/
- Open the tiddler $:/plugins/sq/chatgptimporter
- In the above tiddler, switch to the tab “importer”
- Drag and drop the conversations.json on the red box in that tab to trigger the import.
Screenshot:
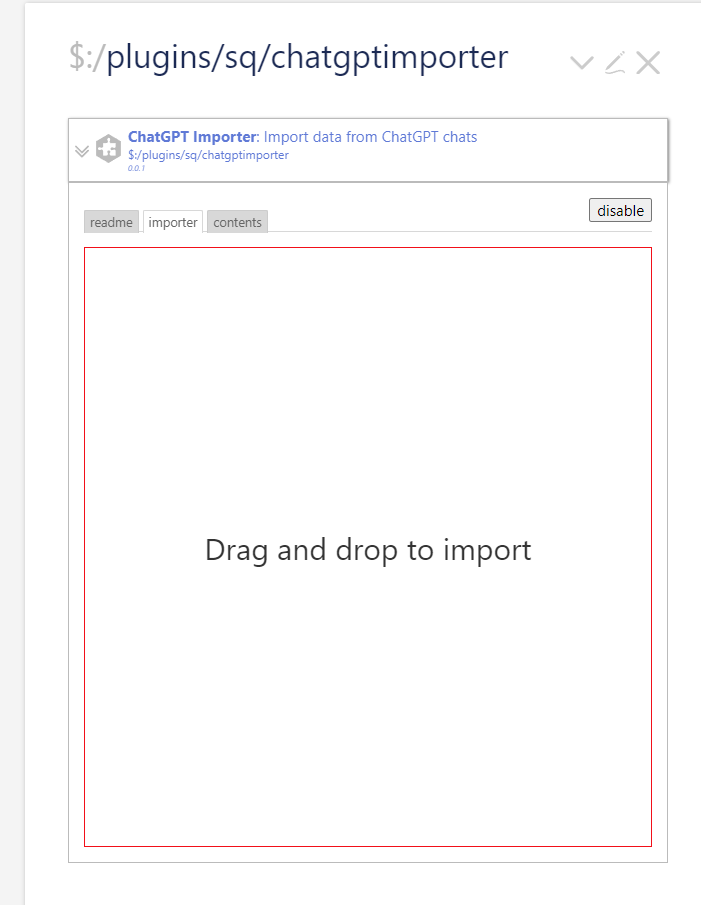
Output:
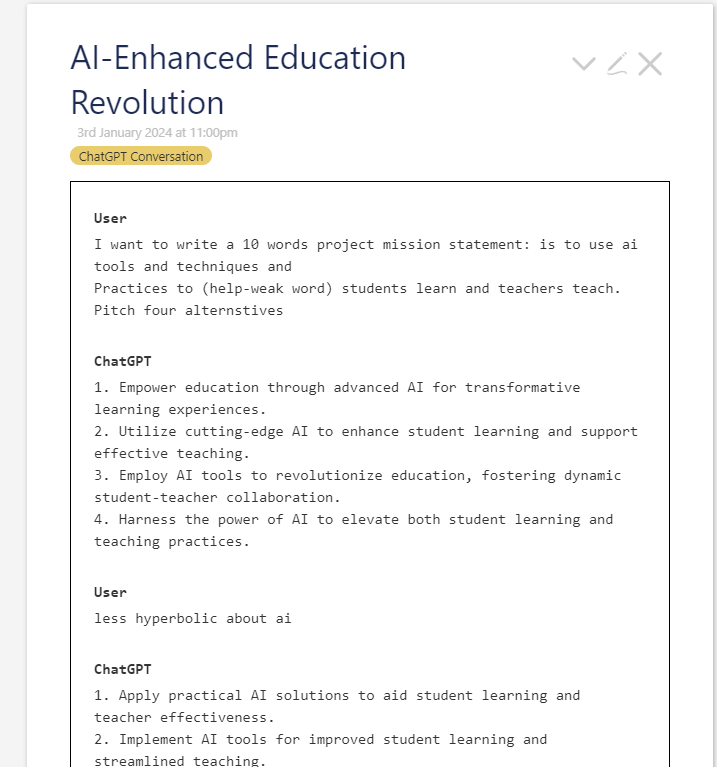
Some interesting (and promising) developments on the quest to have my chatGPT archive in a tiddlywiki
Saq, your deserializer worked on my 1-conversation sample, but fell apart on the larger file; generally timed out (28mb).
So I had chatGPT write a script (it chose python) to generate first html files, then .tid files, and after a few iterations, works well. The conversation is here: https://chat.openai.com/share/84e60770-5d73-4b18-a057-7c7a511ccdf1; you may need to rerun it to generate the scripts or find them here: https://chatgpt-conversations.tiddlyhost.com/.
You may notice at the end of the conversation, I tried and failed to get chatGPT to write a deserializer for tiddlywiki:
Creating a deserializer for TiddlyWiki that can natively process your JSON conversation archive is a more complex task, … Given the complexity of this task, it would likely require a skilled JavaScript developer with experience in TiddlyWiki plugin development.
I haven’t played further, but I’m reasonably successful in getting regular syntax…
//steve.
A further (and final, for this phase) update:
https://chatgpt-conversations.tiddlyhost.com/ now documents a full process to render a chatGPT archive in a tiddlywiki.
Structurally, each prompt and each response has its own tiddler, which will support future enhancements such as searching tagging or annotating specific prompts or responses rather than full conversations.
The process involves using open AI to generate a json file containing the archive, running a python script on the json file generated by open AI to generate a json file that can be imported cleanly into tiddlywikik, importing the json file into the tiddlywiki, and importing a template file to render conversations in appropriately tagged tiddlers.
Thanks again, Saq, for the initial deserializer. And thanks chatGPT for the work on the python script.
//steve.
1 Like
Hi Steve,
If you would set a field code-body to yes in your python-script-tiddler, it would show the tiddler text as plain text.
Setting the type field to text/plain should do the same thing.
thanks for the suggestion on the type variable.
I’m now finding myself in the business of importing a 30mb / 12,000 tiddler file over and over again, as well as wanting to add additional fields to tiddlers that I want to protect. How do I import only tiddlers that don’t currently exist? I usually use the manual import to read from a file, but don’t really know how to modify that.
chatgpt suggested an importUnique function, but wants the 30mb json file in a single tiddler; that seems counterproductive to me. And this is pretty far outside my expertise…
Any thoughts, thanks!
//steve.
(function(){
// Export our macro function
exports.name = "importUnique";
exports.params = [
{name: "source"}
];
exports.run = function(source) {
var tiddlersToImport = $tw.wiki.getTiddlerData(source, {});
var imported = 0;
for(var title in tiddlersToImport) {
if(!$tw.wiki.tiddlerExists(title)) {
$tw.wiki.addTiddler(new $tw.Tiddler(tiddlersToImport[title]));
imported++;
}
}
return imported + " tiddlers imported";
};
})();
I am curious why you keep doing the import. Is it to capture new items?
- that is you only want to import new titles?
Can you limit the export to recent chats?
I have used a dedicated wiki with the json Mangler plugins to import and generate a plugin of data. Then drop this on my wiki.
- if I edit a shadow tiddler it becomes a tiddler
- I can drop in an updated data plugin without touching the edited tiddlers.
Good question!
chatGPT exports all conversations at once. So the import is to get new items, which might be new conversations, or new prompts/responses to existing conversations. chatGPT does an excellent job using fields to uniquely identify all prompts/responses, and to include a conversation ID and a timestamp so that conversations can be reviewed as they were generated.
Currently, my python script generats a json of tiddlers, and the raw import function wants me to check off those matching an existing title. that’s not feasible for anything at scale. i’d like the standard import to automagically reject any existing tiddler, which would also allow me to add additional metadata to tiddlers without worrying about overwriting on a subsequent import.
Ultimately, i’m heading to using the dynannotate plugin (https://twpub-tools.org/) on individual prompts/messages
//steve.
Update: Here’s a demo of an interface to chatGPT conversations that I’ve had in the past, and now exported.
It shows a few conversations imported into tiddlywiki after being exported by superpowerChatGPT & processed using a python script into a json file that can be imported using tiddlywiki.
The objective of the project is to allow those using chatGPT via the Open AI web version, and with superpower chatgpt browser extension installed, to (eventually)
(1) annotate/reflect/comment on their collaboration with chatGPT by annotating individual messages of exported chats,
(2) robustly search chat archive, and
(3) generate quotes and citations / links to specific messages to make visible prompts that generated specific responses.
So far, I can read in conversations and navigate from message to message…
Thoughts, suggestions, improvements, ideas, other attempts at similar tasks…?
//steve.
Steve I am very interested in your work here because I too make use of ChatGPT and save results in a TiddlyWiki. I would be happy to help refine the import process if you can give me;
- Some sample data with new and duplicate conversations I can import to a copy of your demo site.
- I may be able to build on this to achive the remove duplicates. I think its fair to reject tiddlers with the matching conversation code title.
However I am already quite happy with a simpler use of Tiddlywiki for ChatGPT, which I am open to improve. So here are a few notes;
-
I don’t import conversations, so much as create titles with key questions I asked and paste in select answers. This is more manual.
-
I use the markdown plugin, and set the new tiddler button to create markdown tiddlers.
-
I only copy some of the replies (bottom of conversation copy button) and paste these directly into the markdown tiddler. ie; I tend not to capture any refining prompts, or sometimes even the prompts, before I asked the Question.
- This can be different if I am researching prompting itself, where your full conversation approach would be helpful sometimes, but I am currently happy to leave these in ChatGPT
-
I have what could be described as an additional table of contents in a sidebar tab, lets call it an index, and a modified tags bar on tiddlers so I can drag titles from the Index to give Chats some structure, organised under subject areas etc… There are many given my diverse interests.
- I also install my reimagine tags tool set, so I can do more like open groups of tiddlers etc…
-
Since I do not presently code in python, I would be more inclined to capture the export from ChatGPT and parse and reformat that within TiddlyWiki, this would also reduce the number of steps in the import workflow.
Of note others are using API connections. There are other efforts in our community but they can be hard to follow because of the use of a lot of jargon.
Just an idea. When processing the raw JSON, perhaps the python script can ignore all conversations which are earlier than the last date stamp encountered in the previous run ? And at the end of each run, the python script will output the latest date stamp encountered in that run for use in the next run. Maybe append the latest date stamp from each run into a history file so you have a record and can redo the runs if need be.
Updating this thread: I’ve created a modest tiddlywiki that imports an archive of chatgpt conversations so that each message (prompt or response) is a tiddler with field values allowing it to be identified with a specific point in a specific conversation.
Additional tools and functionality on the way in the coming weeks.
//steve.
Great experimenting here. I am also considering using Saq’s Streams plugin to manage ChatGPT Conversations. I often find myself a few prompts into a chat, and then start to edit the last prompt a few times for different “branches”. It would be great to have a tool to visually navigate this.