
I played with levenshtein Operator in below wikitext. I tried to find tiddlers with title similar to the keywords I enter in the searchbox.
- go to https://tiddlywiki.com
- craeet a tiddler with below content and save
<$edit-text tiddler="$:/temp/lev" field=text tag=input type=search />
<$set name=term tiddler="$:/temp/lev" field=text>
<$list filter="[<term>trim[]limit[3]] :map:flat[all[tiddlers]!is[system]]
:filter[levenshtein<term>compare:number:lteq[5]]
:sort:number[levenshtein<term>] :and[first[250]]">
<$link /> (<$text text={{{ [<currentTiddler>levenshtein<term>] }}} />)
<br>
</$list>
</$set>
- Now enter something in searchbox like
Tiddlyand see the results
Remarks
- filter first checks the term and ignore empty or blank search term
- it next selects all non-system tiddlers
- it then evaluates selection by distance and remove those have a levenshtein distance more than 5
- finally sorts the result by levenshtein distance and limit output to first 250 matches.
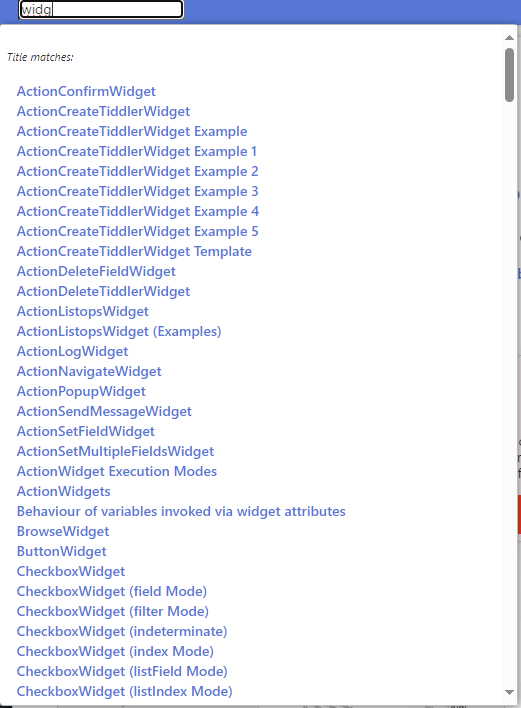
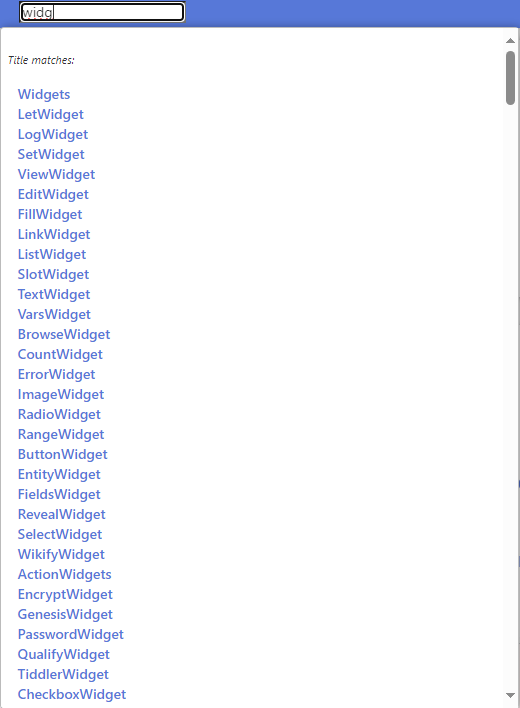
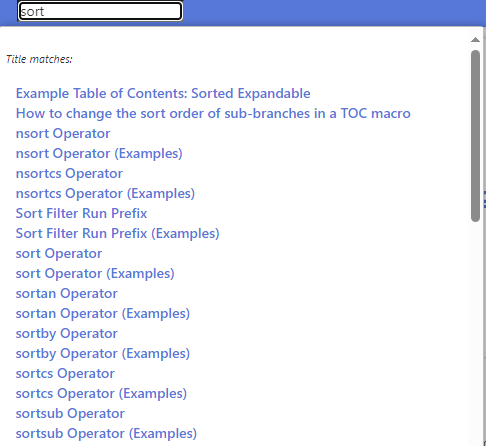
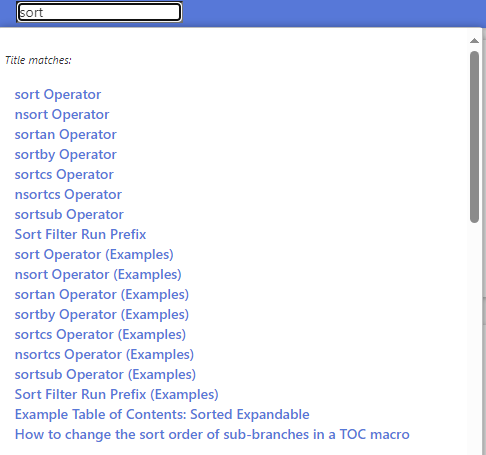
 . Well, at least I have found something useful for myself.
. Well, at least I have found something useful for myself.

