1. Why use Json in TiddlyWiki by standard?
-
“JSON (JavaScript Object Notation) is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for machines to parse and generate. It is based on a subset of the JavaScript Programming Language Standard ECMA-262 3rd Edition - December 1999. JSON is a text format that is completely language independent but uses conventions that are familiar to programmers of the C-family of languages, including C, C++, C#, Java, JavaScript, Perl, Python, and many others. These properties make JSON an ideal data-interchange language.”
-
"JSON is a widely used format that allows for semi-structured data, because it does not require a schema. This offers you added flexibility to store and query data that doesn’t always adhere to fixed schemas and data types.
-
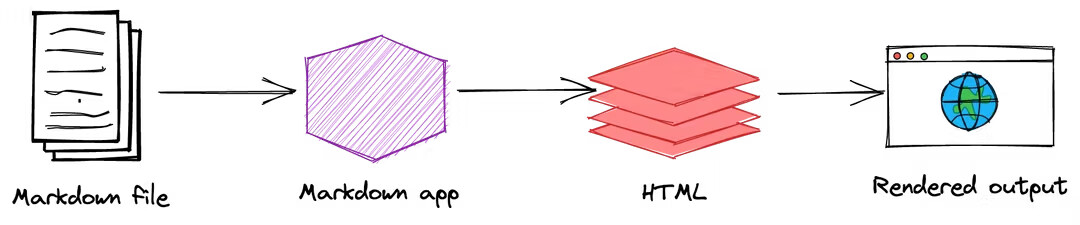
“Json, XML, other markup languages (markdown, wikitext, commonmark, html etc), email and EDI are all forms of semi-structured data.” But… “for embedded Markup” is good if it has Json for standard in TiddlyWiki
-
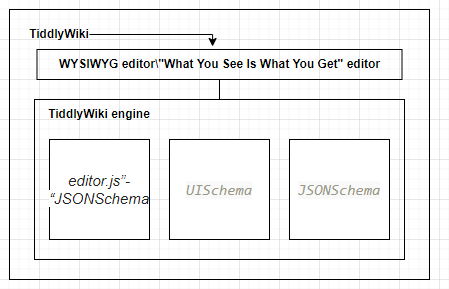
“Json is non-linear, tiddlyWiki” too.
-
Concept
{
"app": {
"config": "./settings.json",
"cwd": "./",
"src": "example/content/",
"filePattern": "**/*.md",
"dist": "example/output.json",
"name": "markdown-json",
"version": "0.0.1"
},
"data": [
{
"section": "Elements",
"title": "buttons",
"device": [
"desktop",
"mobile"
],
"styles": [
"https://example.com/styles/structure.min.css",
"https://example.com/styles/app.min.css"
],
"contents": "<p>Follow some application examples of buttons</p>",
"id": "buttons",
"meta": {
"relativePath": "content/buttons.html",
"createdAt": "2020-10-08T16:05:30.415Z",
"lastModified": "2020-10-08T16:05:14.452Z",
"size": 2095,
"formattedSize": "2.0 KB"
}
},
{
"section": "Elements",
"title": "icons",
"tags": [
"icons",
"base"
],
"contents": "<h1 id=\"icons\">Icons</h1>\n<p>Our icons list still is empty :(</p>\n",
"excerpt": "<p>Our icons list still is empty :(</p>",
"id": "icons",
"meta": {
"relativePath": "content/globals/js-utils.html",
"createdAt": "2019-08-27T18:01:33.747Z",
"lastModified": "2019-08-27T18:01:33.747Z",
"size": 331,
"formattedSize": "331 Bytes"
}
}
]
}
- References
- https:// www. w3schools .com/whatis/whatis_json.asp
- https:// en. wikipedia .org/wiki/JSON
- https:// www. json .org/json-en.html
- https:// en. wikipedia .org/wiki/Semi-structured_data
- https:// en. wikipedia .org/wiki/Unstructured_data
- https:// www .integrate .io/glossary/what-is-unstructured-data/
- https:// www .xml .com/pub/a/w3j/s3.nelson.html
- https:// www .xml .com/pub/a/2004/10/06/deviant.html
- http:// essaysfromexodus .scripting.com/tedNelsonWebHypertext
- https:// cloud .google .com/blog/products/data-analytics/bigquery-now-natively-supports-semi-structured-data
- https:// wikilabs .github .io/
- https:// www. vertopal .com/en/convert/markdown-to-json
- https:// www. npmjs .com/package/markdown-json
- https:// www integrate .io/glossary/what-is-unstructured-data/