I find particularly noteworthy this bit around 25:27:
“Tiddlywiki is written in itself […] the entire user interface of TiddlyWiki […] is all constructed out of wiki text primitives”
I haven’t been able to find anything on the internet regarding this property of TiddlyWiki
If I understand correctly, this means that TiddlyWiki is based on a “small” set of text primitives, that could be implemented in any underlying user interface language (for example Elm, or emacs lisp)
Are these text primitives Tiddlers?
Are there any different backend for implementing these primitives other than HTML+Javascript?
Is this still true or it stopped being true some versions ago?
Another example of an interesting backend could be Jupyter Notebook, maybe bringing together the wiki-style documentation with the Data Science exploratory data analysis.
It’s a webpage. Like 99.99% of webpages, it’s written in HTML, CSS and JavaScript. The TiddlyWiki UI (and increasingly much of its internals) are written in wikitext.
The answer is “effectively yes” in my view, because you do not need to compile it from a separate source, although in a way this is done from the git hub repository this is because it is the code management environment.
Once you have a TiddlyWiki you can modify any aspect of its operation, even the core, save and reload. Changes are immediately reflected. There is no need for any other software except that in TiddlyWiki and its operation within the “universal client”, the browser.
If tiddlywiki was a programming language, then this would be a different question, then we would be thinking of the language being defined in its own language, but TiddlyWiki is a new entity based on various internet/browser technologies and a non-trivial quine. A quine writes itself, TiddlyWiki writes itself (during save).
Unfortunately the Question “Written in itself” is more commonly used with programming languages and not solutions that use a package of technologies.
Yes tiddlywiki uses its own structure, HTML, JavaScript and CSS and yes it uses and saves these to file to change itself.
Joe Armstrong was investigating this concept of building a Quine in his tiddlywiki, but I don’t know if this means interoperability with another hypothetical backend:
If tiddlywiki was a programming language, then this would be a different question
I don’t think tiddlywiki has to be a full programming language, but it may be close. It “only” would have to be able to build tiddlywiki itself based on some building blocks. The code could be provided by the blocks themselves (be it javascript, erlang, or emacs lisp for example) and then have an executor that would actually create/update/read/delete tiddlywiki components
As a “quine”, you can alter it and have it output its new (or even unchanged) “self”, but that is “self-replicating”.
The very core of TiddlyWiki, you may override with your own pieces, but you aren’t changing the core. You’re just setting up a “please use my version instead of the core version”. But the core version remains. If that were done for every version of TiddlyWiki, every new version would still be carrying all previous versions of every overridden core tiddler and we would have ever-ballooning-in-size versions of TiddlyWiki.
The only way to change the core in a TiddlyWiki instance is by opening up that TiddlyWiki instance with some editor (even Notepad), to alter the core. Then you have a new TiddlyWiki instance with a brand new core, but TiddlyWiki didn’t create a new version of itself. It can’t.
New TiddlyWiki bits and pieces can be created, core TiddlyWiki bits can be overriden via tiddlers, but it can’t output a version of TiddlyWiki with a brand new core (i.e the javascript stuff that allows everything to happen.).
TiddlyWiki is a Quine. .. When you save it, it effectively does build itself. That makes it possible to have different download buttons at tiddlywiki.com
There is a big green Download Empty button, which uses a configuration which builds an empty version, using parts of tiddlywiki.com
If you click the “Check button” in the right sidebar it will use the actual content from the page and it will save / download itself – plus – the new content
I think the meaning of " TiddlyWiki is written in itself” is not clear, and what I’m aiming at is easiness of reimplementation independent of the browser.
If one were to reimplement the inner parts (say the bootprefix and the microkernel) so that the data model is the tiddler data model, all public functions that the plugins use are implemented, and the functions drawing and editing the user interface are written in some other language and provide an alternative interface (say emacs lisp, and the interface is drawn in emacs itself) then everything would work?
One would need at least:
Some way of running emacs-lisp in the browser (although not as an interface, as only the plugins and the public function interface/wrapper would be running in javascript) and make calls to emacs to edit the actual interface
Working with javascript objects and modifying them to keep the illusion that there is a browser, possibly having to deal with recursive objects
Edit: Now that I think of it, the plugins probably assume there is a DOM, so you would have to replicate the entire DOM and at this point you are basically implementing a browser in emacs
Theoretically yes … The problem with “in theory” is, that it always works “in theory”, but in praxis it does not. … As so often the devil is in the details. Having one sentence of specification is a bit “sparse”
But
The TW data model is simple. It basically is a JSON structure, which is wrapped in an HTML <script> tag, that is embedded into an HTML file, which contains the TW core-code and core-UI.
So … If your UI can search for <script class="tiddlywiki-tiddler-store" type="application/json"> and parse a JSON array, that contains tiddler objects you are able to read every tiddler-store from every tiddlywiki.html file.
Important: It’s allowed to have several stores wrapped in <script class="tiddlywiki-tiddler-store" type="application/json"> tags.
If you are able to create a JSON “tiddler store” and inject it into empty.html using the described markers, you are able to create a valid file-TiddlyWiki, which can be opened and saved in the browser.
… If you want to render tiddlers in a “native way” with macros, variables and especially transclusions you either have to re-use the tw-javascript-rendering-engine or you’ll need to create a TW wikitext parser.
The existing regexp-based parser is in the works since about 2013 and the development is still ongoing. … So “here will be dragons …” and here too
Remember that wikis based on this core, and the core itself, all assume the existence of the Web layer underneath. That means that you would have to recreate all of HTML/JS/CSS, including such subtleties as the difference between buttons and links, the complexities of CSS selectors. It’s a giant job. The latest JS spec alone is well over 250,000 words long. The HTML spec is over half a million. Just the list of CSS Recommendations, Candidate Recommendations, Proposed Recommendations, Working Drafts and so on is huge, never mind the actual content.
So figuring out what precisely you would want to support from the underlying platform is a large job. Implementing it is comparable to the process of creating a new web browser from scratch.
So best of luck. If you’re looking for help with this, sure, I’ll be available eventually, but just remember that I’m out of office for the next few… centuries.
Yes, the idea is not to implement a spec-compliant web engine, “only” the wikitext parser. The thing is, as you say, that core (and probably plugins as well) assume there is a HTML/DOM object underneath. To what extent (and where in the code, and how much) do they assume it exists?
However if this is true:
excluding plugins, the UI and its internals should be increasingly easier to implement in another environment without HTML, JS, CSS
There is also this answer to help identify the different parts of the so-called “wikitext”:
This means you’d have to implement the interface for Document, including its createElement method, which would have to return an element, typed according to the tag supplied to it. Somewhere in that returned value’s hierarchy, you would have to have an appropriate setAttribute method. You would need to duplicate the JS this behavior, it’s Array prototype, including the split method, it’s behavior for || and &&, and so on.
Or not. You could say that you just need to supply the same interface as the ButtonWidget from some other stack, but you’ll need to remember that that interface right now is to generate DOM elements with certain styles and behaviors attached. If you did this for every JS Widget, macro, etc, my guess is that you would still have to create a huge swath of the web stack. And every upgrade might require more, because the core will certainly not restrict itself to some arbitrary subset of the DOM that you happen to have implemented.
But just the fact that wikitext is an extension of HTML and not an entirely separate language should be enough to point out the difficulties.
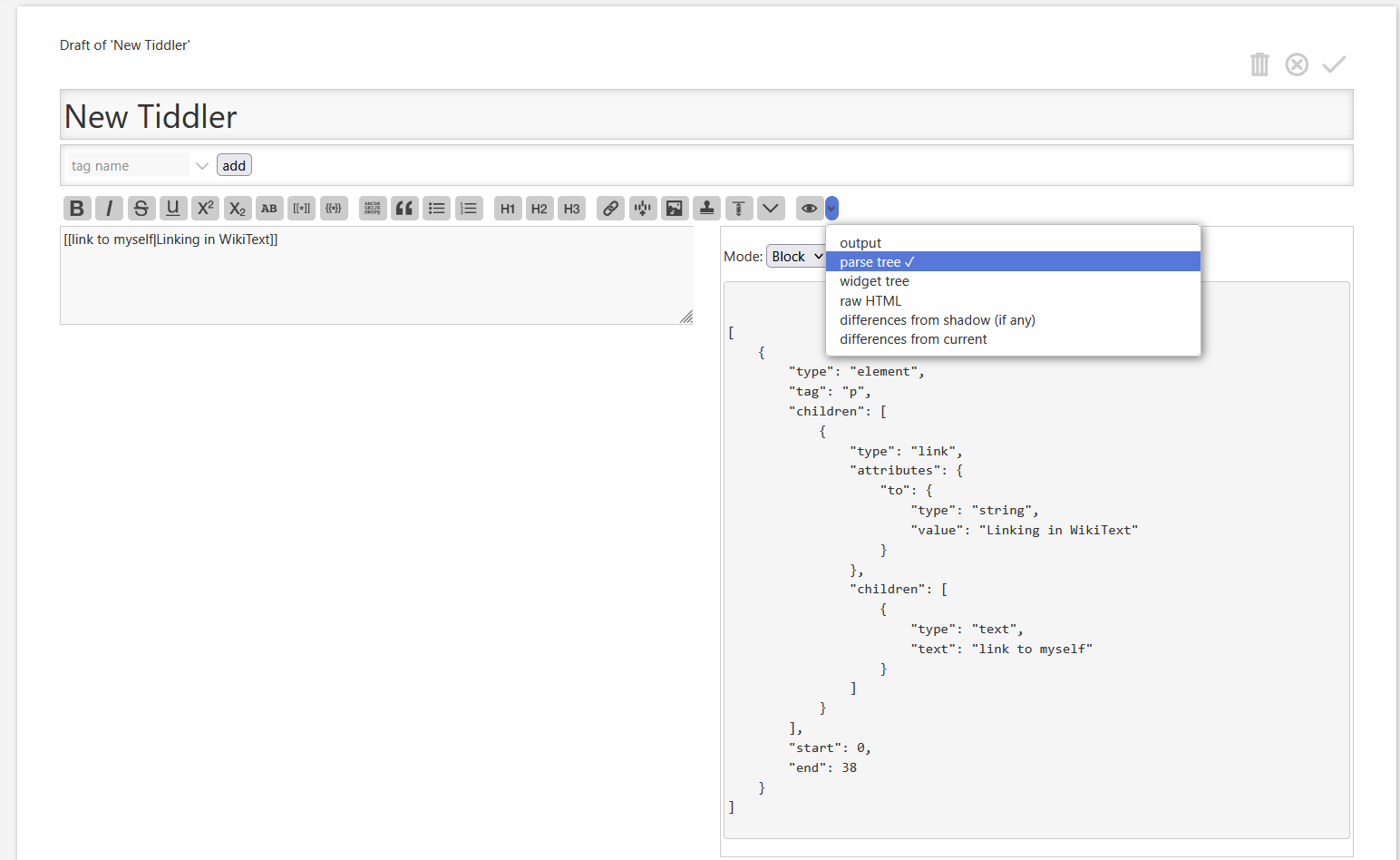
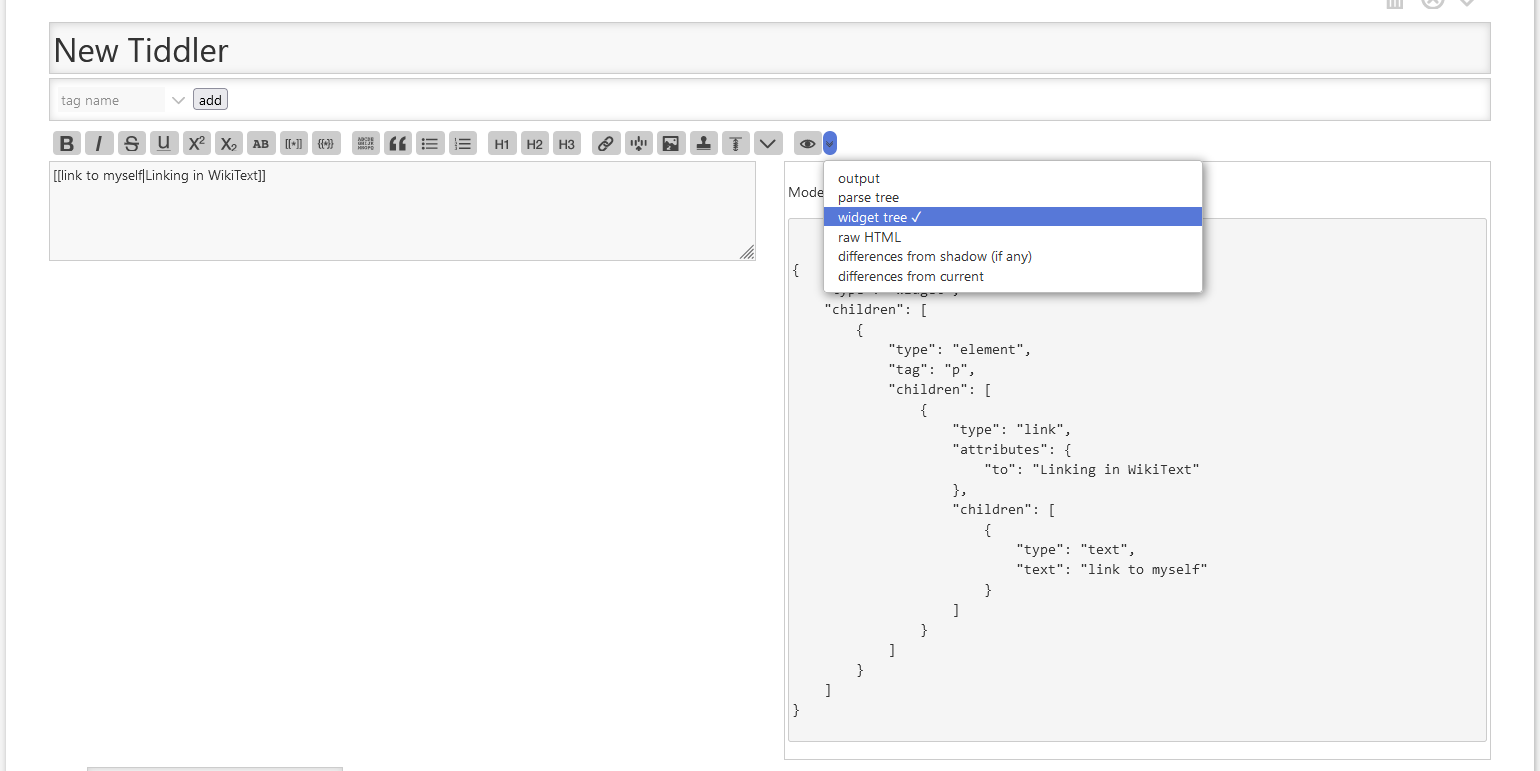
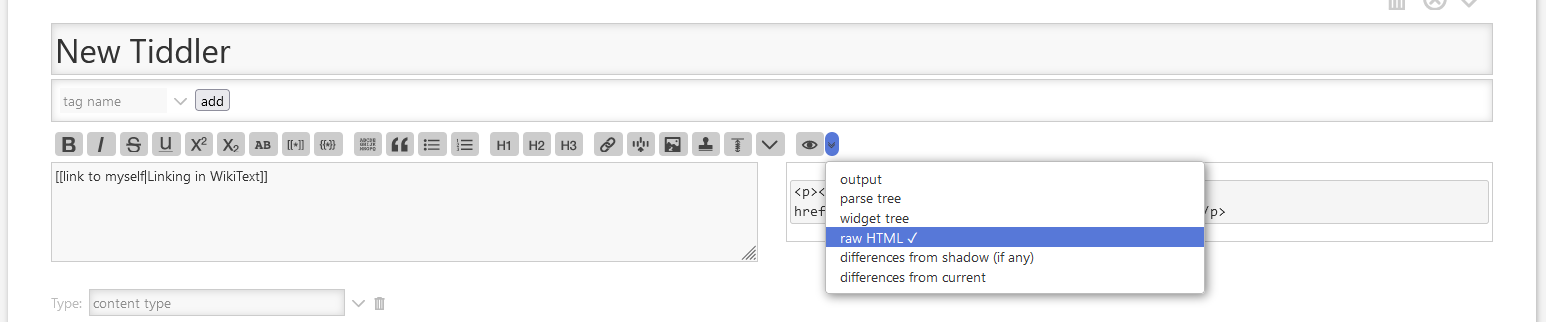
You can have a closer look at your second example on yourself. .. It’s the same pipelien. parser → parse tree → widget-tree → html code.
If you use my example, you will see a bigger difference between parse-tree and syntax-tree. .. If there are transclusions, the widget-tree “resolves” them recursively. The parse-tree only parses the content of the current tiddler.
Thanks @lytex for an intriguing question – and welcome to the community.
Thank you! It’s nice to remember Joe. He was an inspiration to me, and I was honoured by his enthusiasm for TiddlyWiki. His untimely passing was a great tragedy that I still feel keenly.
The most important philosophy of TiddlyWiki is that the purpose of recording information is to re-use it, and TW proposes that the best way to optimise information for reuse is to cut it up into the smallest semantic units. One can then use links, lists and tags to weave the fragments together into multiple overlapping narratives.
The observation about TiddlyWiki being written in itself relates to some secondary principles:
that the individual needs of users are all different, and so it is not respectful to try to impose the same user interface on every user
that users are not generally in a position to know up front what their ideal user interface looks like
that the most efficient way for users to figure out precisely what they need is by iteratively modifying the user interface themselves
We address these needs by making wikitext powerful enough to be able to implement TiddlyWiki’s entire user interface.
To address your specific questions:
That’s right. As others have pointed out, the target platform of TiddlyWiki is the browser, and so even if TiddlyWiki were to be rewritten in a different language it would still need a web browser (or an emulation of one)
The only available implementation of the TiddlyWiki primitives is currently JavaScript, targeting HTML.
I am not familiar with the internals of Jupyter Notebook, but given the fact that it manifests itself as an interactive web page it must include JavaScript in its implementation. If that’s true, then the simplest path to integration might be to integrate the existing JS implemention of TiddlyWiki.
Thank you all for your patience, understanding and support, especially @pmario for helping me visualize the process and digging into the internals of TW
After studying TW and Jupyter architectures I’ve come up with some objectives/principles:
Two distinct integrations
There are two types of integrations: TW into Jupyter, which means writing a Jupyter extension, and Jupyter into TW, which means writing a TW plugin
Have the TW editor bar on each Jupyter cell
This is the main result from the Jupyter point of view (I call this “Integrating TW into Jupyter”). In the future it may be interesting to execute code from TW by making calls to IPython kernels, but I want to:
Focus first on markdown cells
Jupyter has also code cells for executing code. Being able to call IPython from TW is what I would call “Integrating Jupyter/IPyhton into TW” but it seems better to first get comfortable with the inner workings of Jupyter
Run TW in server mode
Running TW In this way means all the .tid tiddler files are available, which allows the following correspondence:
1 cell, 1 tiddler
I think a good approach is considering a notebook a particular arrangement of tiddlers and each cell an individual tiddler. I’m considering plugins such as the Rider plugin to be able to edit a transcluded tiddler/cell.
The filesystem and in particular the .tid files can be the shared interface between TW and Jupyter to keep the underlying files synchronized
It may be a view month in the future, when the transclusion mechanism can do this out of the box, once the parametrized transclusions PR gets merged. …