Dear friends
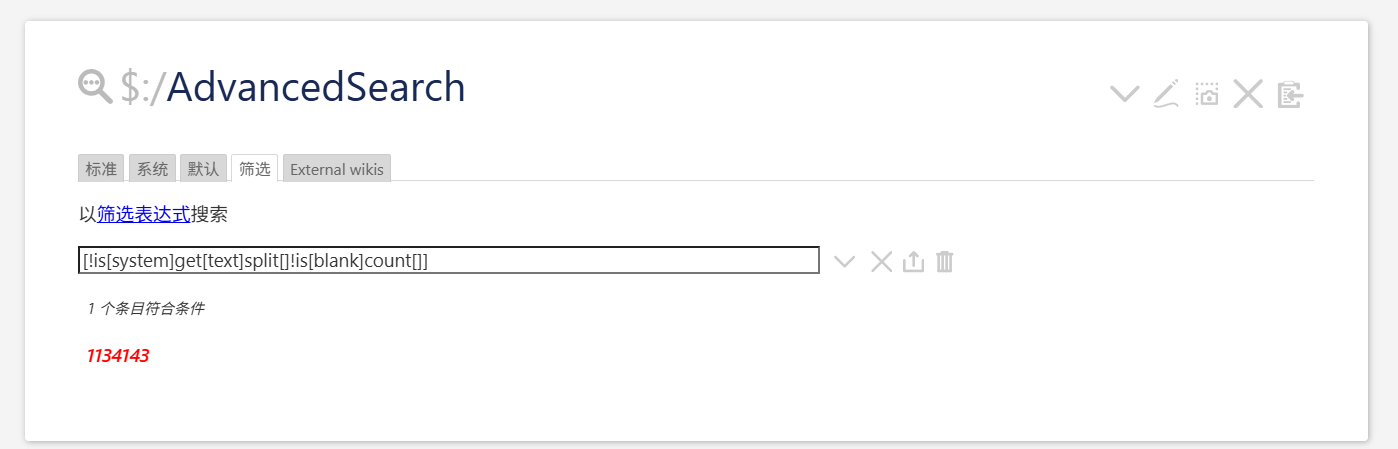
In a single-file tiddlywiki, which field’s tiddler should be set to render these Tiddlers only when they click on entries in the standard search or advanced search, thereby speeding up the browser loading speed of the single-file tiddlywiki
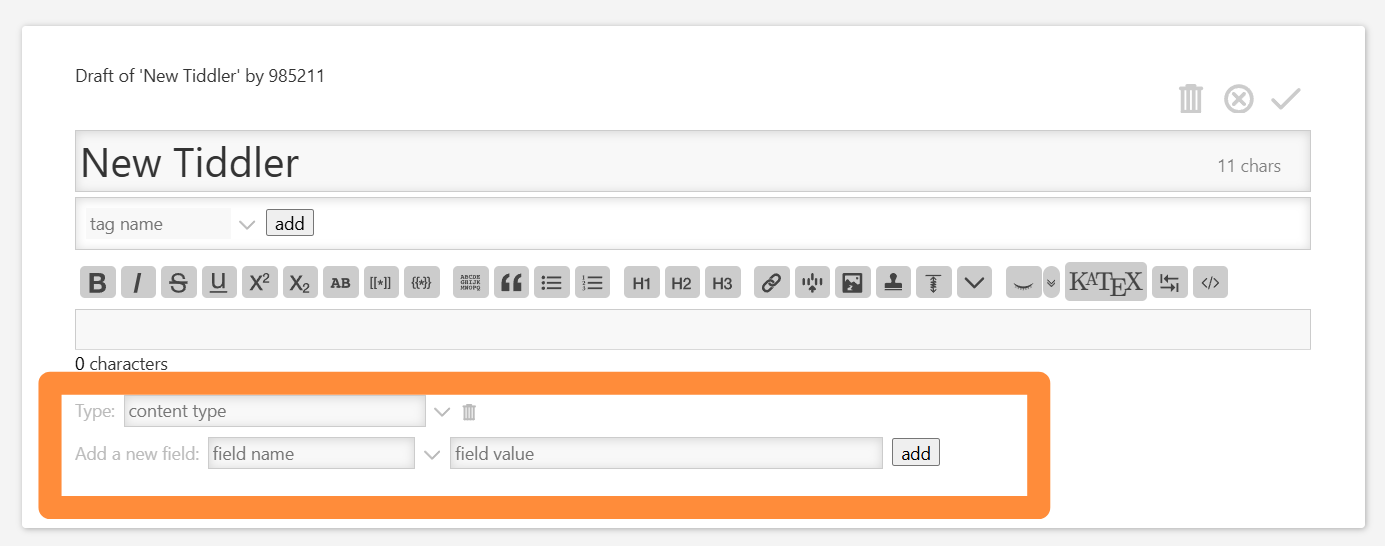

I hope tiddlywiki only renders tiddlers located in the story river

This will significantly accelerate the loading speed of larger single-file tiddlywiki
I hope this will significantly speed up the loading of the large single-file tiddlywiki. The loading time of DOMContentLoaded is less than 100ms, and even better, less than 50ms, because my single-file tiddlywiki needs to be updated frequently. Each time the loading speed of a single file on tiddlywiki accumulates, it affects the speed at which I take notes
Or are there any open service interfaces for the single-file tiddlywiki? The front-end and back-end of a single-file tiddlywiki can be separated. I can try to develop a fast server for lazy loading of tiddlywiki based on the python language
Could the interface be “$tw.< Method Name >”?
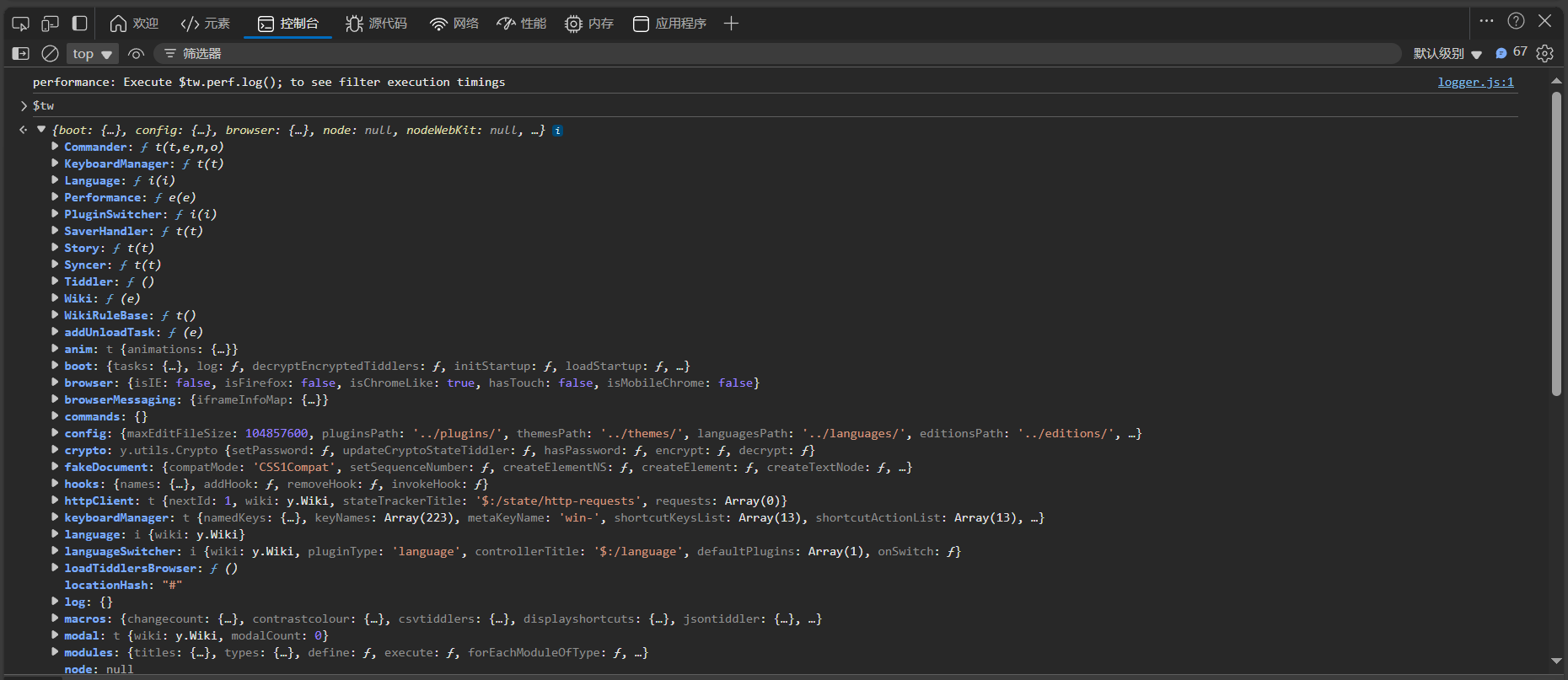
I have tried a local server specifically designed for single-file tiddlywiki based on python, which combines asynchronous loading, gzip, and browser caching. However the loading time of DOMContentLoaded has not been significantly improved
Any reply would be highly appreciated