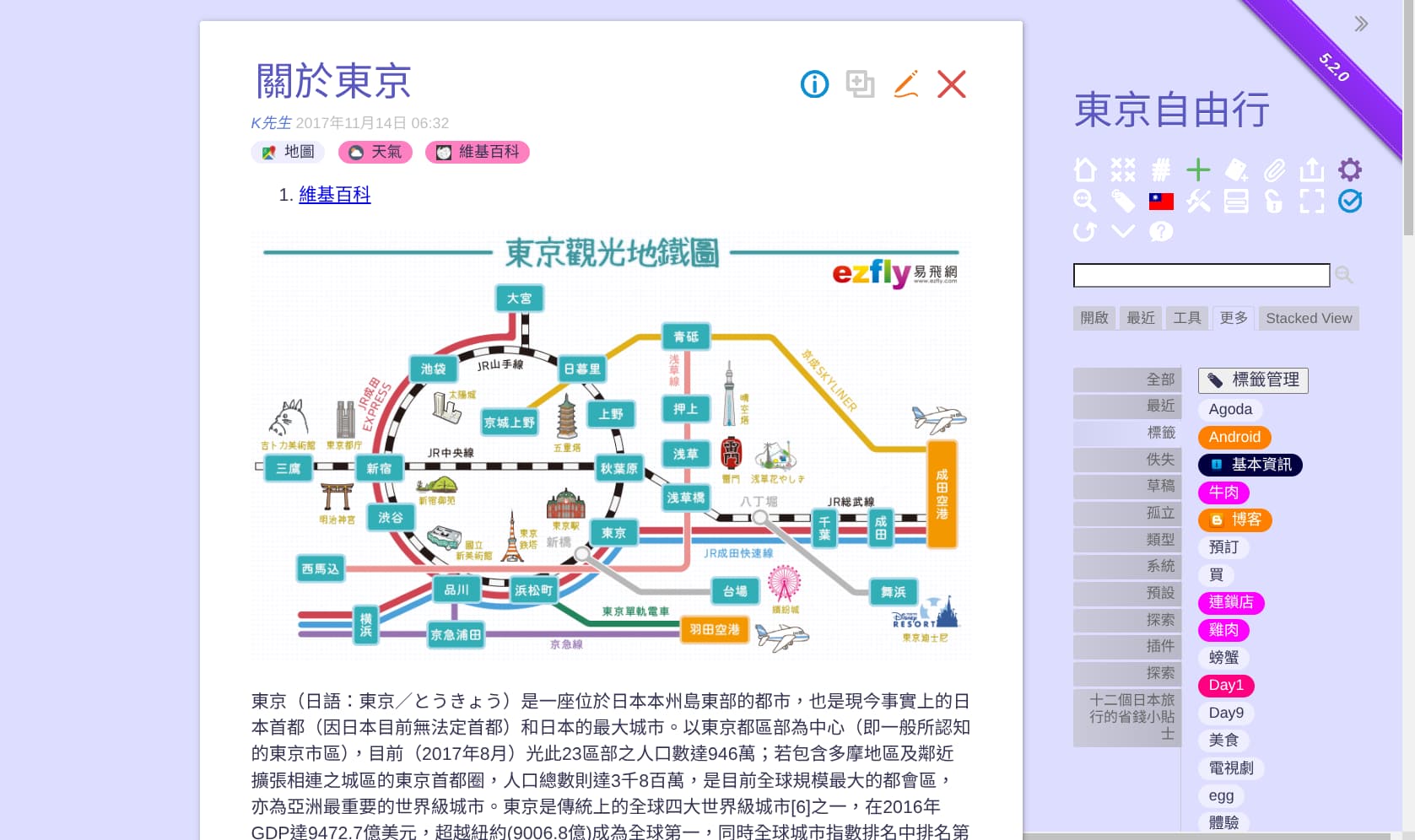
In the early days of websites, with weak search engins, we used to join a loop of links. Each site would be linked to, and link to another. One could follow the links to review all in the loop. If done in a standard way you could automate walking the loop and collect all the websites in it. Once you have the list, however you get it you can generate random links to one of them.
So what I was thinking of was a gadget like RandomDog you could install in a wiki. And. Once a day, get a link to another wiki.
I’m hazy how that would work.
That’s the core of the problem. To get a random link to another wiki, there needs to be a full list of all possible links, from which that random is chosen.
In the case of random dog, the random dog website has all the random dogs, and you ask if to select a random one for you.
In the more general case here, you either need one of the following:
the same - someone else to have a list of all options and provide one at random when you request
someone else have a list of all options, which you obtain, and then you choose one at random from that provided list
some method to generate the list of all options when needed
From the point of view of the code you add to your local TW, the above is in order from simplest to most complex. But “simplest” means you’re offloading the complexity to a server elsewhere which does some of the work instead.
So the question becomes - is there an existing list of wikis that can be obtained?
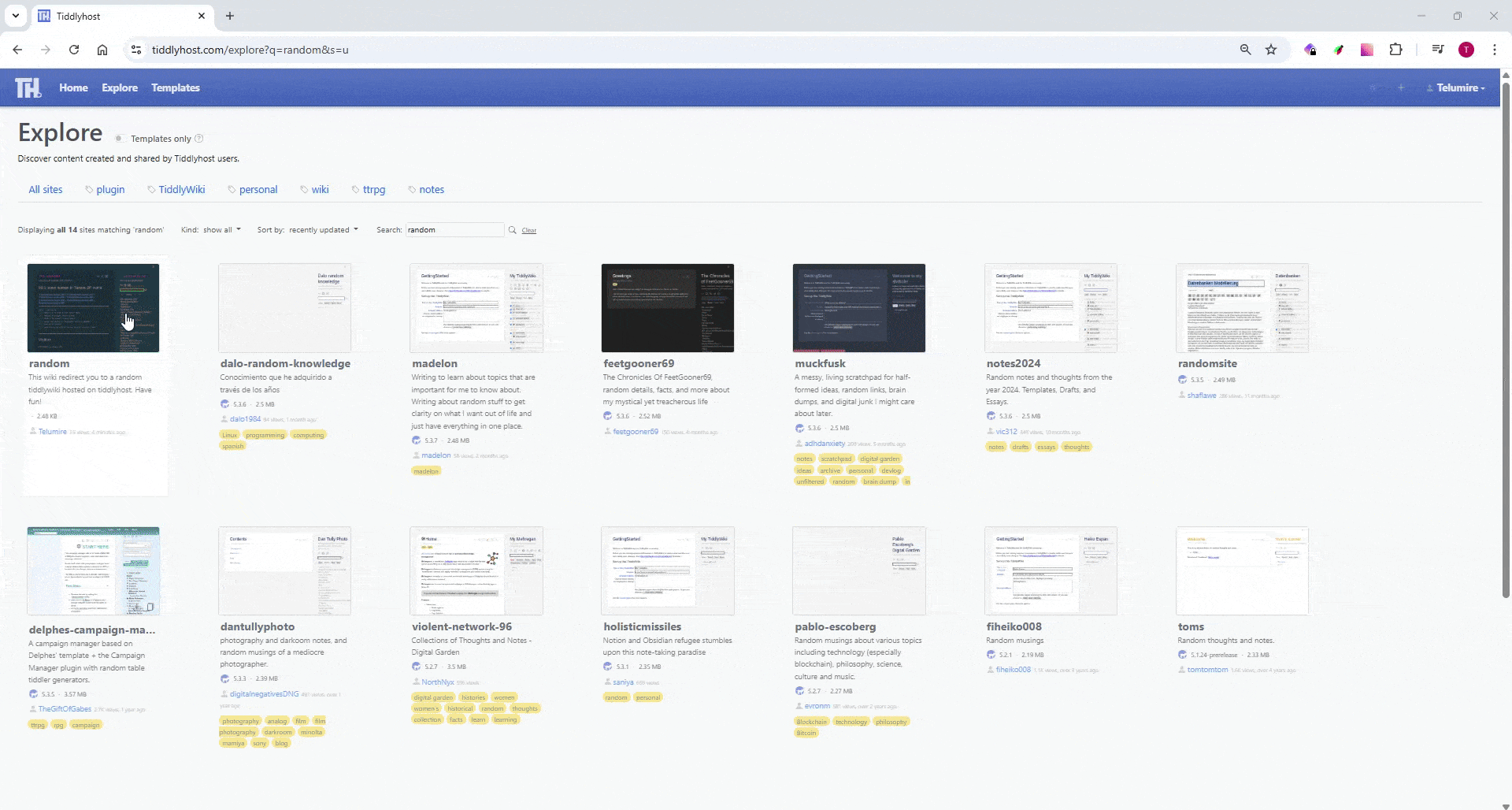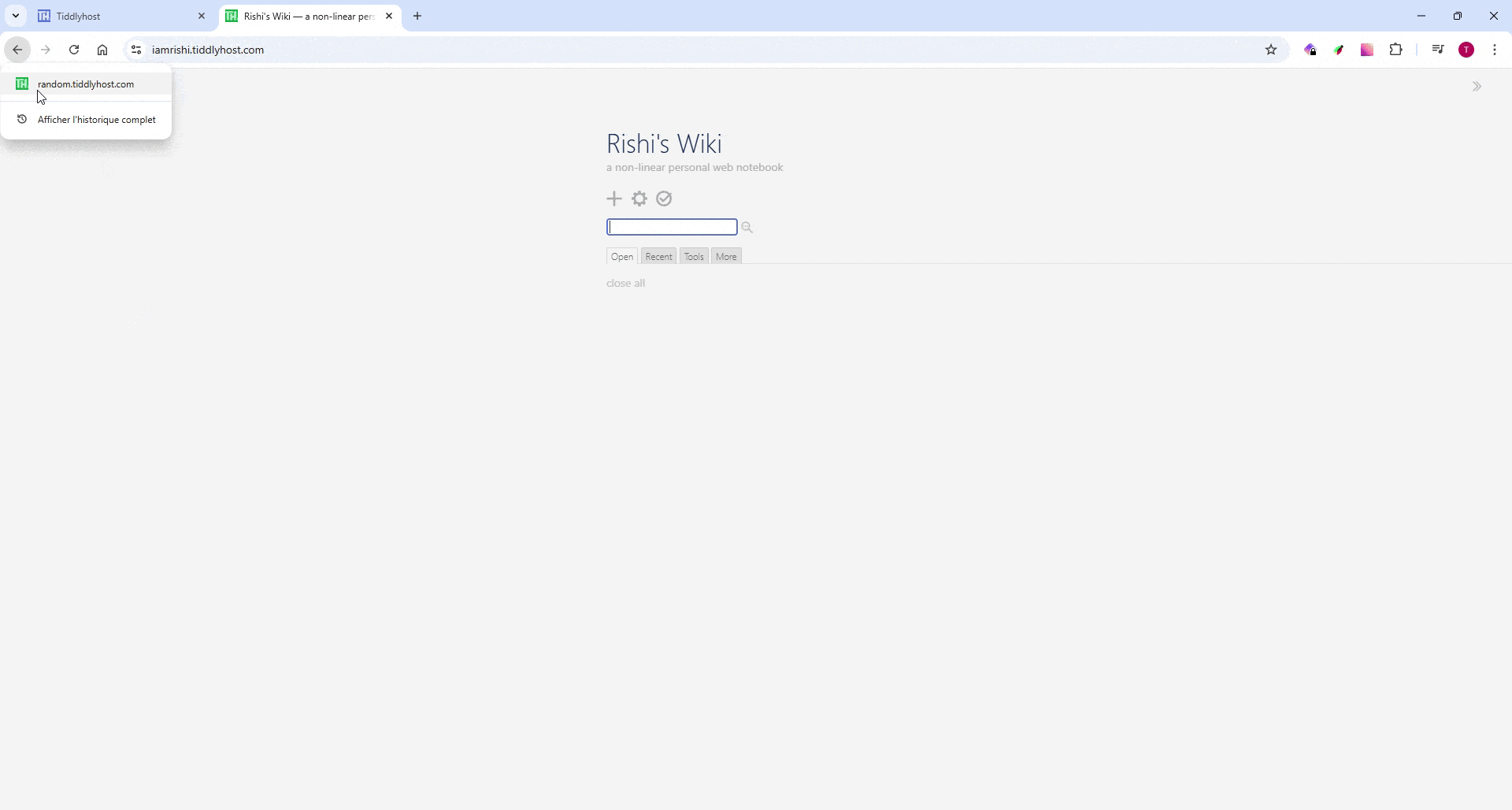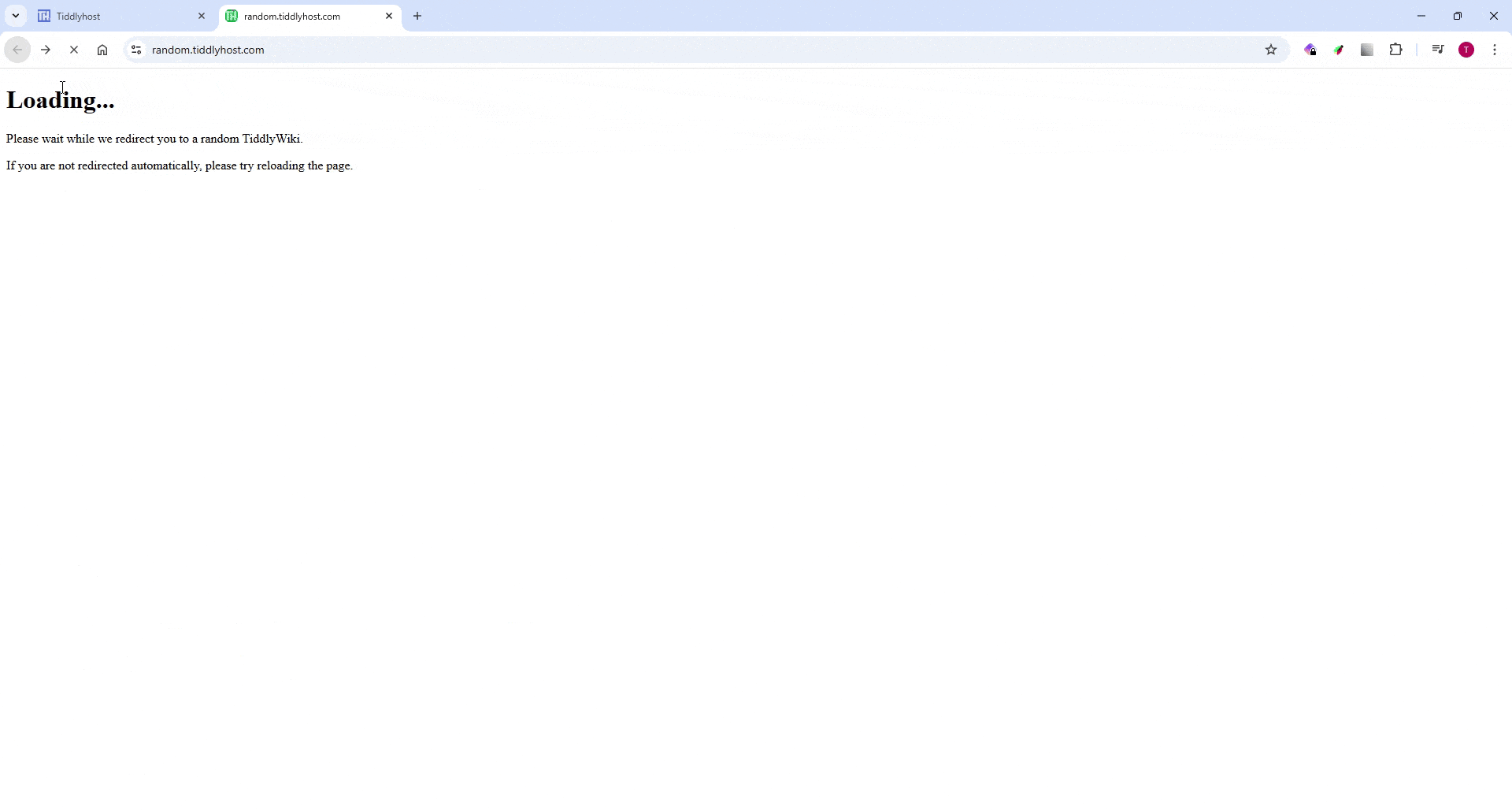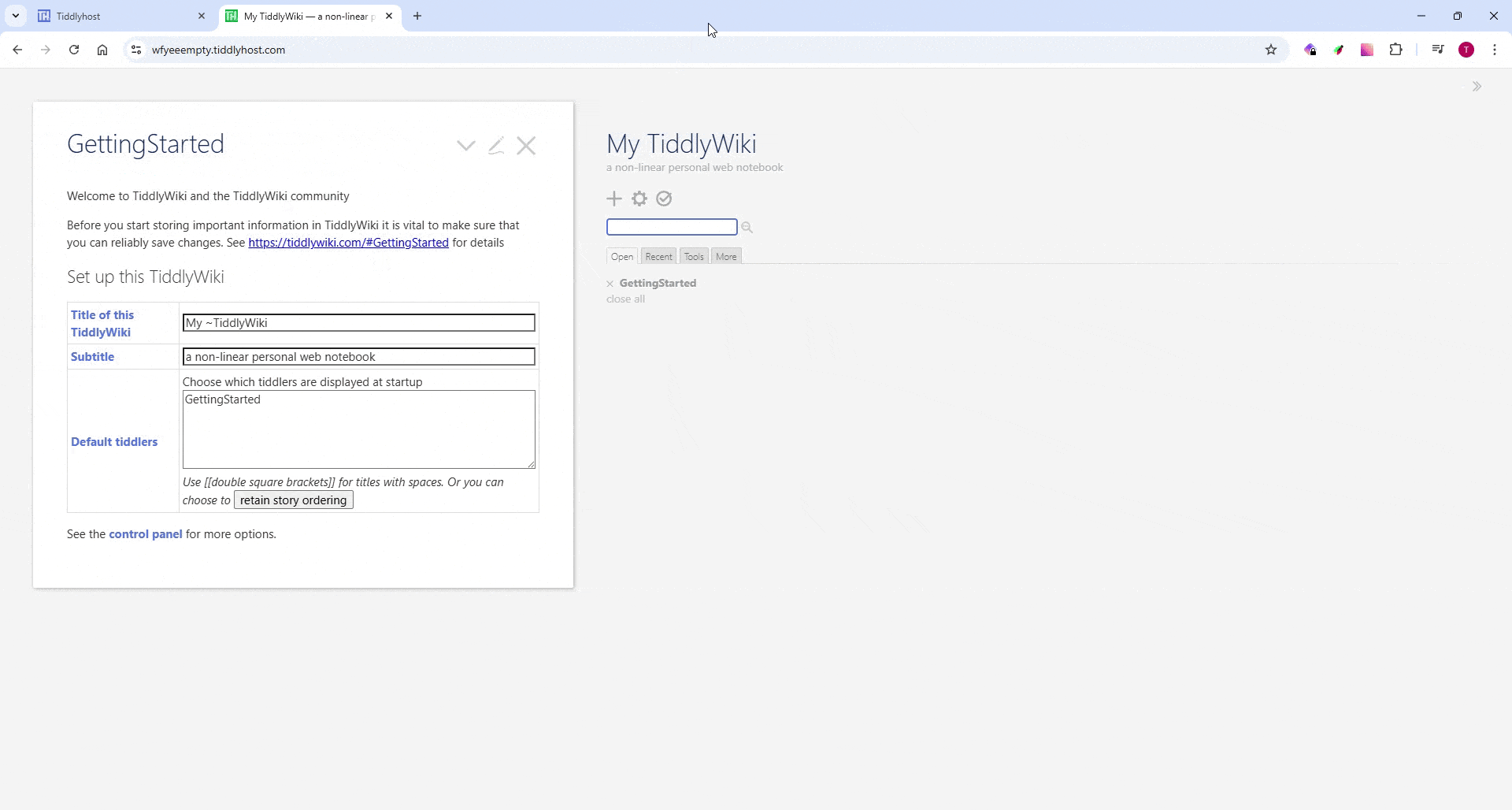
If it’s just a random tiddlyhost link, then some parsing of the output of https://tiddlyhost.com/explore?s=r to get the top link would work. If tiddlyhost has the same in an API then even better.
(parsing that output in wikicode is beyond me. In my native linux bash scripting, it’s trivial though fragile: curl -s "https://tiddlyhost.com/explore?s=r" | awk -F'"' '/a target/ {print $4}' | head -n 1
There are 1437 TWs reported there as of today.
Plenty for a random wiki for years.
I wonder if they have a simple list we might access via http-request for a Random Tiddlywiki a day? Or maybe we can do it already via an API? I don’t have the technical skill to properly understand how to do it.
<!DOCTYPE html>
<html>
<head>
<script async>
(async () => {
console.log("🚀 Starting redirect script...");
try {
const tiddlyhostUrl = `https://tiddlyhost.com/explore?k=tw&s=r&cache_buster=${Date.now()}`;
const proxyUrl = `https://api.allorigins.win/raw?url=${encodeURIComponent(tiddlyhostUrl)}`;
console.log("Fetching wiki list from:", proxyUrl);
const response = await fetch(proxyUrl);
if (!response.body) {
throw new Error("Response body is not readable.");
}
const reader = response.body.getReader();
const decoder = new TextDecoder();
let buffer = '';
console.log("Streaming response to find link...");
while (true) {
const { done, value } = await reader.read();
if (done) {
console.warn("‼️ Stream finished before a link was found. The website's HTML structure may have changed again.");
break;
}
buffer += decoder.decode(value, { stream: true });
// We search for the start of an anchor tag with a 'target' attribute.
const linkIndex = buffer.indexOf('<a target=');
if (linkIndex !== -1) {
// We found the link, now grab the href from that point forward
const relevantHtml = buffer.substring(linkIndex);
const hrefMatch = relevantHtml.match(/href=(["'])(.*?)\1/);
if (hrefMatch && hrefMatch[2]) {
const randomWikiUrl = hrefMatch[2];
console.log(`✅ Link found: ${randomWikiUrl}`);
await reader.cancel();
console.log("Stream cancelled. Redirecting now...");
window.location.href = randomWikiUrl;
return; // Stop the script
}
}
}
} catch (error) {
console.error("❌ An error occurred:", error);
}
})();
</script>
<meta name="application-name" content="TiddlyWiki">
<meta name="tiddlywiki-version" content="5.3.8">
</head>
<body class="tc-body">
<h1>Loading...</h1>
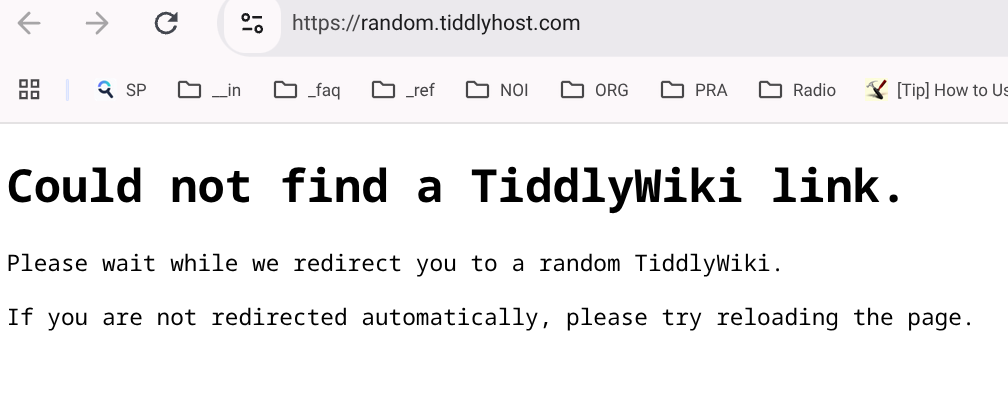
<p>Please wait while we redirect you to a random TiddlyWiki.</p>
<p>If you are not redirected automatically, please try reloading the page.</p>
<div id="storeArea" style="display: none">
</div>
</body>
</html>
I tried to make the redirect faster by using streaming to avoid waiting for the whole html page to be downloaded but it seems like it’s less reliable .. I reverted to a simpler fetching and a bit slower method which should work as long as the free proxy I’m using keep working