Is there a way to get the raw text of a widget body inside its execute method?
I see it’s parseTreeNode children have start and end attributes, which I could use if I had a reference to the tiddler text (which is not necessarily currentTiddler)
Changed the category
Hi @Ittayd there is no direct way for a widget to get the plain text representation of its content.
Widgets are created from a parse tree, which does not necessarily derive from parsing plain text; some widgets construct partial parse trees that are then rendered as their children.
My question was for those widgets that get their parse tree from the wiki text.
Alternatively, is there a way to instruct the parser to not parse the body of a certain widget, so the parseTreeNodes of the widget then has only one text child? I see there is a configuration for self closing and void elements, can there be one for ‘raw’ elements? Or alternatively, support cdata?
One approach would be to write a custom parse rule that returns a parse tree with your widget wrapped around the raw string content of the block delineated by the parser delimiters, see for example the codeblock parse rule. However, it can be tricky to find appropriate delimiters.
1 Like
I’m not really sure what you’re asking for, but do you mean this? (try at tiddlywiki.com)
<$wikify name="hey" text={{{ [[HelloThere]get[text]] }}} output="parsetree">
<<hey>>
</$wikify>
1 Like
hmmm. I think you should be more specific about what you want to achieve instead how you want to achieve it. IMO it would probably be easier for us to make suggestions.
Hi @Ittayd those are both interesting ideas.
- The first is that the HTML parser should not parse the content of certain elements/widgets, instead treating the entire content of the element/widget as a text node. We would need a mechanism for plugins to be able to add custom entries to the list. I think that could work; the main restriction would be that the list of raw elements/widgets would need to be fixed at startup. That’s because the architecture at the moment assumes that the result of parsing a given block of text is always the same (and therefore can be cached)
I think the main disadvantage of this approach is that it requires the user to understand an irregularity: that certain elements/widgets are treated differently. That’s already the case for self-closing elements, but you might notice that we don’t emphasise that capability in the docs.
- The second is that we introduce a special character sequence that marks a block of plain text that is not otherwise parsed. The CDATA syntax used by XML is quite verbose and clumsy, perhaps we would want to think up our own alternative. For example, we could use triple hats.
<div>
^^^ This is plain text, and <span> won't get parsed ^^^
</div>
I think I slightly prefer the 2nd idea, but need to think through the implications.
1 Like
What about a pragma similar to the \rules pragma. The following example configures the parser to only detect code blocks. .. Something similar could probably be done … But I’m not sure what @Ittayd actually wants to do
\define myMacro()
\rules only code
''asdf''
\end
<<myMacro>>
In what seems to be related I have played with building an additional macro that given a named tiddler and html tag can extract blocks of text in a named and also arbitrary html tag, the idea is to be able to extract the content of such tags and perform other actions on it.
- This way a class and css can be applied to such “blocks” defined by those arbitrary tags, starting with “display: none;” to hide it.
- We could extend this to include widgets to extract its content, or raw body text.
A general solution available as macros and widgets would have broad applicability whist satisfying the OT.
There are some devil in the details but I think a powerful extension of design and innovation would be forthcoming. Complications include.
- Nested tags/widgets
- ignoring and/or extracting the parameters in the opening tag.
- Being able to treat the content using a “custom render” inside a tag/widget block “in line” inside the rendering of the text, rather than via methods such as above/below the text in a view template.
- This would be like allowing custom “blocks” within the text body to be rendered by custom renderers by design.
Here is a simple example
something
<quicklist class="quicklist">
Item one
Item two
another item only separated by new line
each could become a tags with a checkbox etc...
</quicklist>
something else
- In this case just the text inside the quicklist tags will be handled differently to the normal render, perhaps like raised here
Right, and I ended up just using codeblock in the body of the widget and extracting it. The problem with creating a custom parse rule is that I need to invent a new wiki makrup which I didn’t like. Trying to create a parse rule for the widget tag itself doesn’t work as TW doesn’t allow to set the priority of rules (it just tries them one by one according to the order in which they were configured) which means my rule is ignored.
Then HelloThere needs to have the widget and when it is wikified the widget’s body will be wikified before the widget is executed.
Without an example with sample input and expected output, I can’t help.
Best wishes to you in finding a solution.
To clarify, @Ittayd has run into a common scenario when writing custom widgets. It can be explained in relation to the KaTeX plugin that adds maths formatting to TiddlyWiki:
https://tiddlywiki.com/plugins/tiddlywiki/katex/
The purpose of the plugin is to let authors use standard LaTeX notation to insert mathematical formulae in wikitext. One might expect that the implementation would involve a <$katex> widget that might be used like this:
<$katex>
f(x) = \int_{-\infty}^\infty\hat f(\xi)\,e^{2 \pi i \xi x}\,d\xi
</$katex>
However, as @Ittayd discovered, that won’t work because the content of the <$katex> widget will be parsed as wikitext, and so any part of the formula that happens to also have a meaning in wikitext would be disrupted.
So, the approach taken by the <$katex> widget is to instead pass the formula as an attribute:
<$katex text="f(x) = \int_{-\infty}^\infty\hat f(\xi)\,e^{2 \pi i \xi x}\,d\xi"/>
That would clearly be pretty horrendous to type on a regular basis, and so the KaTeX plugin also includes a “parse rule” (in other words, a JavaScript module that matches a particular piece of wikitext syntax, and emits the corresponding underlying widgets). The parse rule looks for text contained in double dollar signs, and emits the corresponding KaTeX widget, with the formula placed in the “text” attribute.
$$
f(x) = \int_{-\infty}^\infty\hat f(\xi)\,e^{2 \pi i \xi x}\,d\xi
$$
Which displays as:
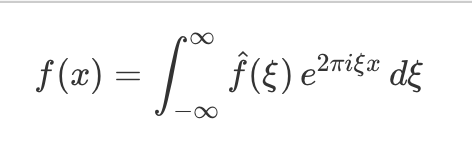
1 Like
Not as easy to type, but the existing Typed Blocks in WikiText could be used like this:
<$katex>
$$$text/plain
f(x) = \int_{-\infty}^\infty\hat f(\xi)\,e^{2 \pi i \xi x}\,d\xi
$$$
</$katex>
Then the widget code can extract the text by rendering child widgets
KatextWidget.prototype.getTextContent = function() {
var dom = document.createElement("div");
this.makeChildWidgets();
this.renderChildren(dom);
return dom.textContent;
}
But maybe this isn’t any better or much different than using codeblock in the body of the widget as @Ittayd says he ended up doing.
Having had the same need a few times, the problem I have found with most such workarounds is that it requires the user to use special syntax within the widget to get the expected behaviour, which is far from ideal and error prone. An ideal scenario would be that the widget definition dictates how the child content is parsed, however this is problematic as in the TW architecture this falls within the realm of the parser rather than the widget.
1 Like