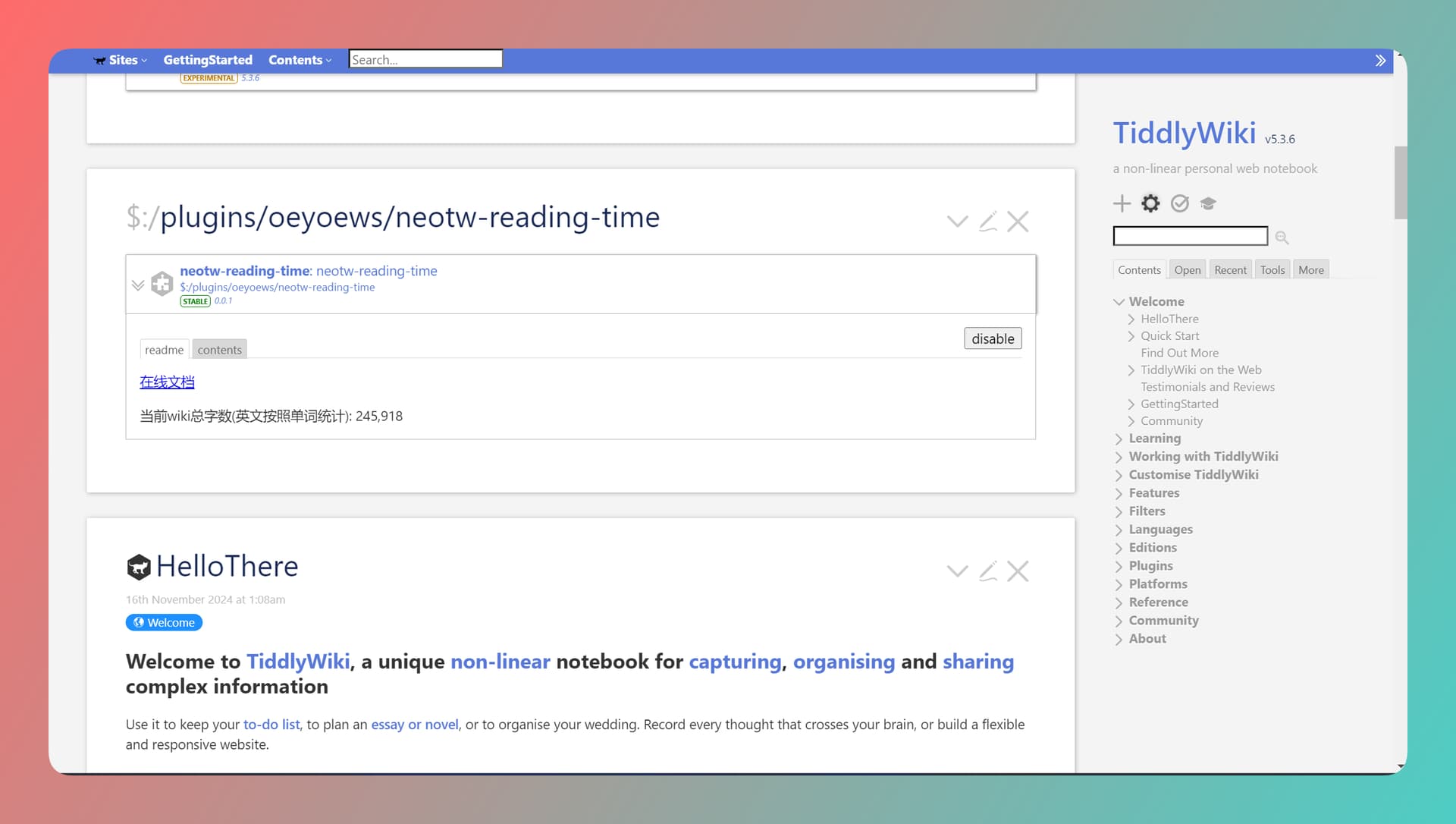
Dear friends
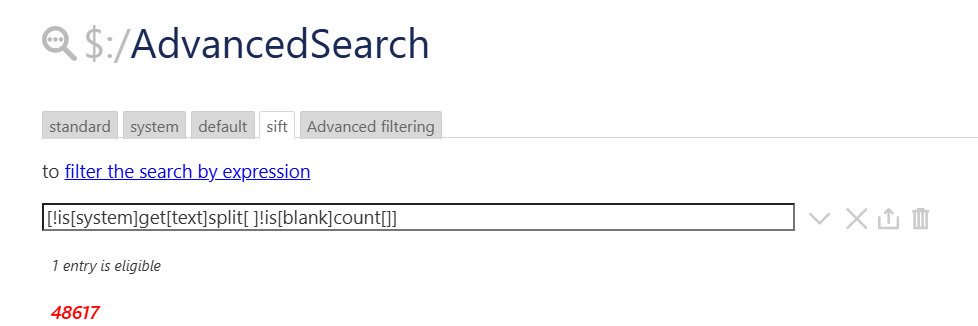
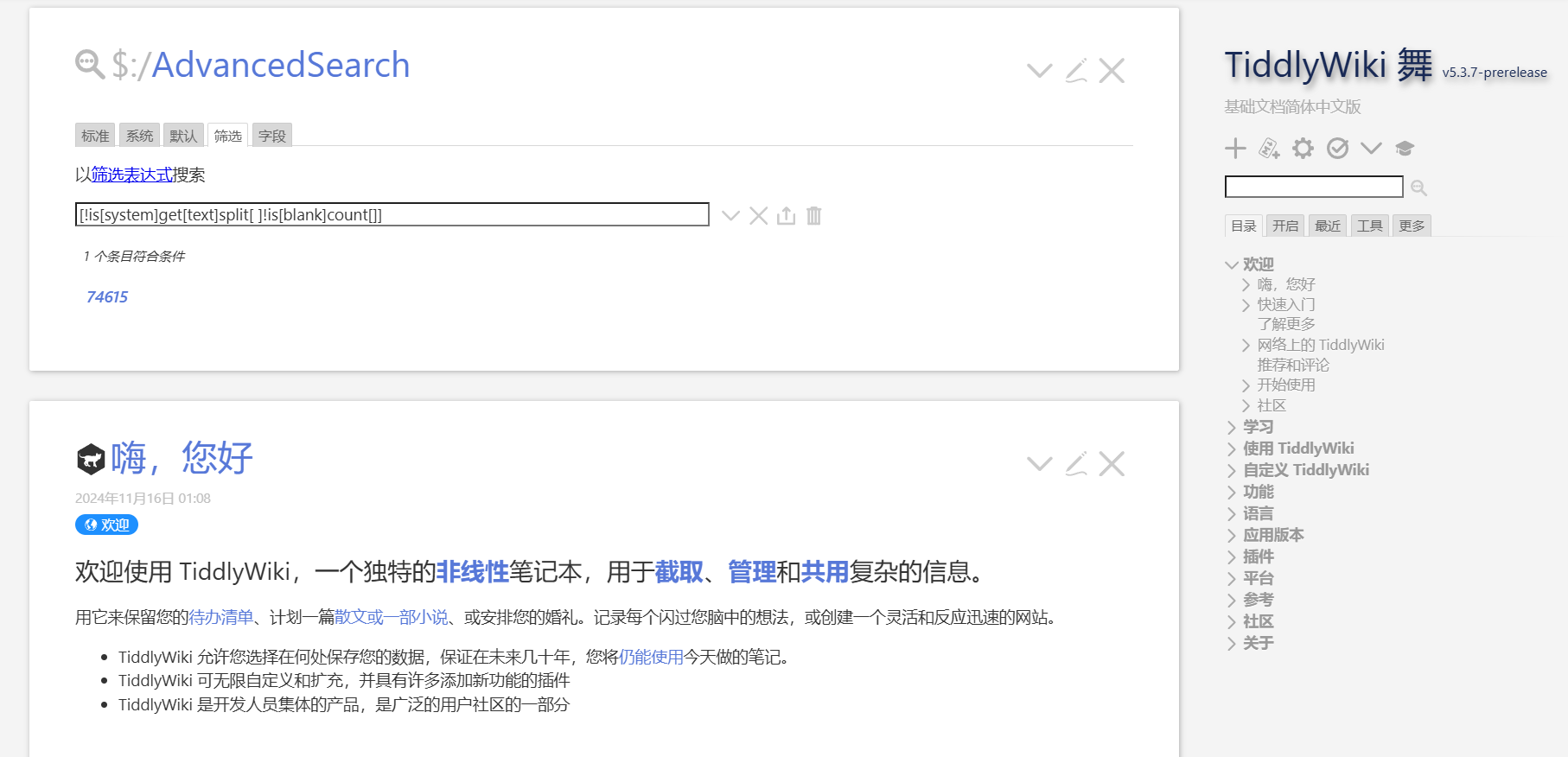
I use the filters below in my knowledge base and it works
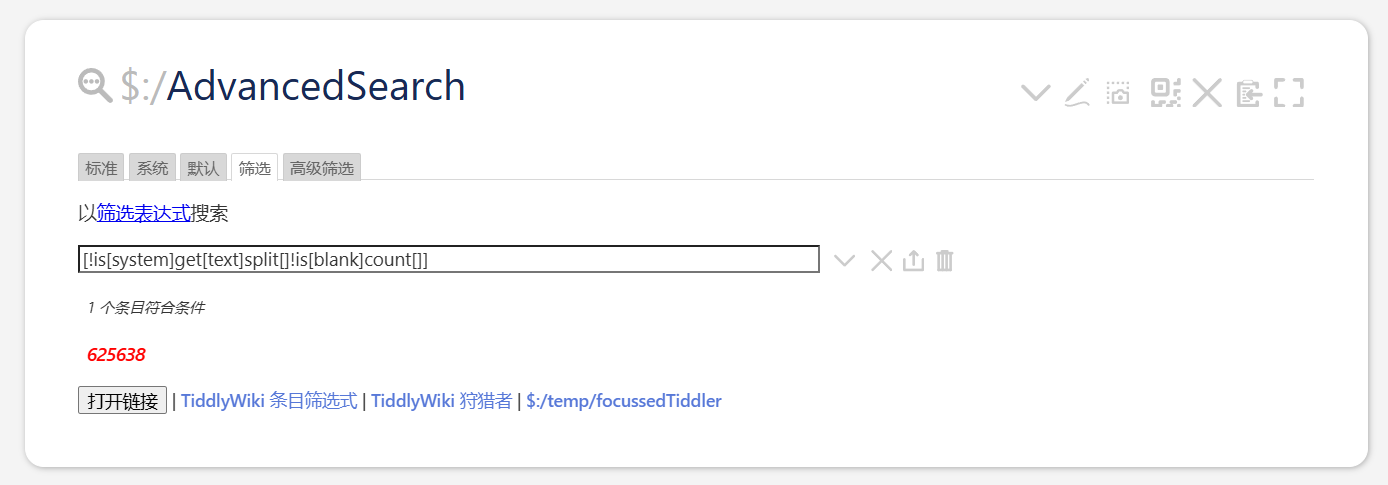
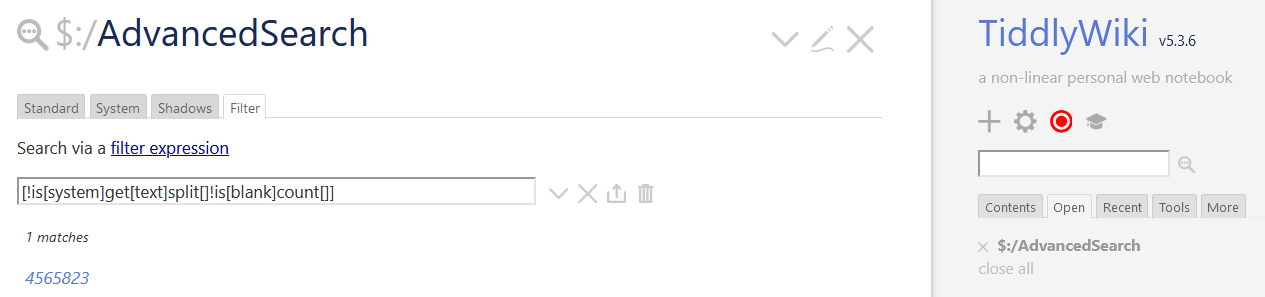
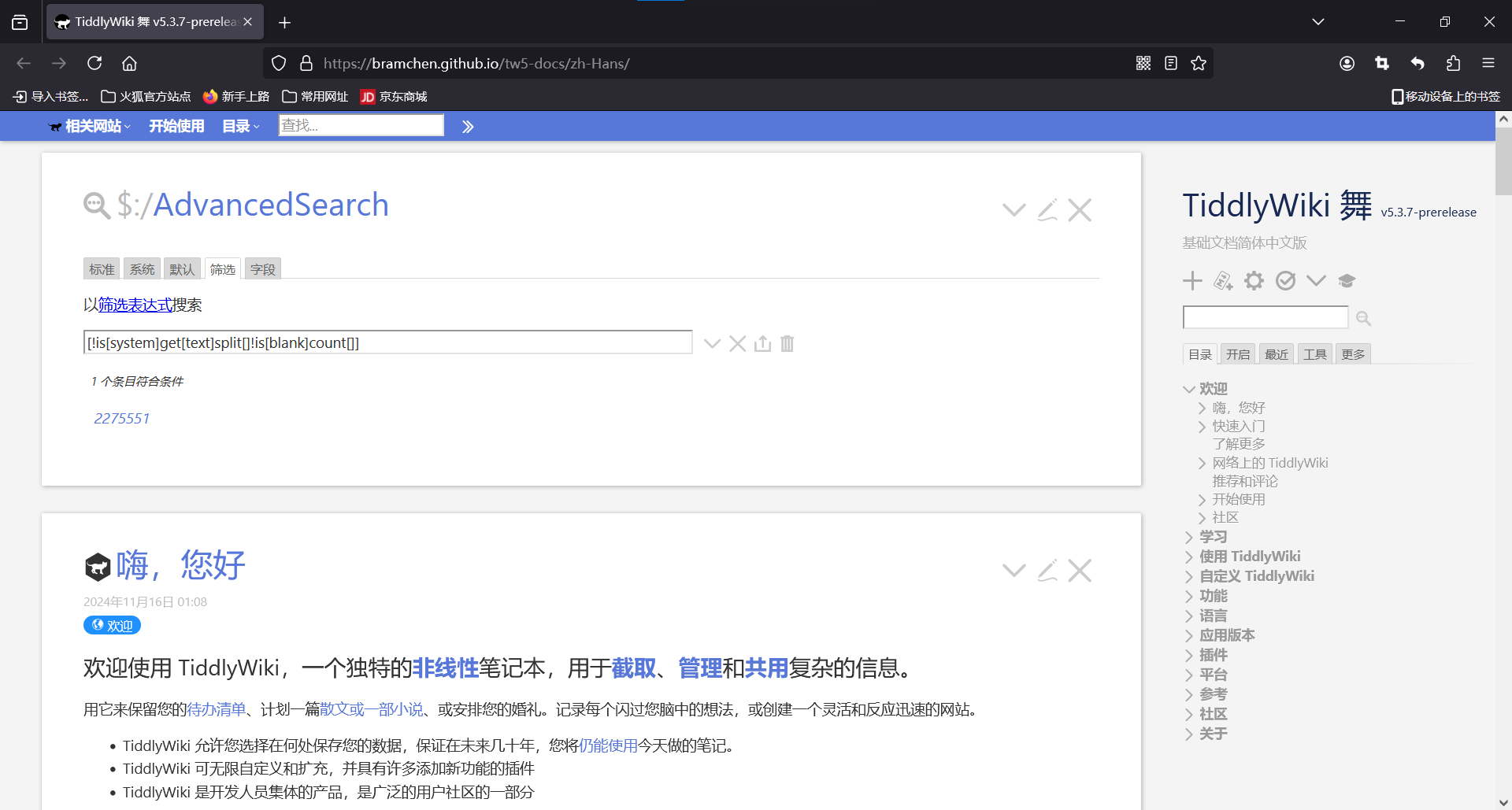
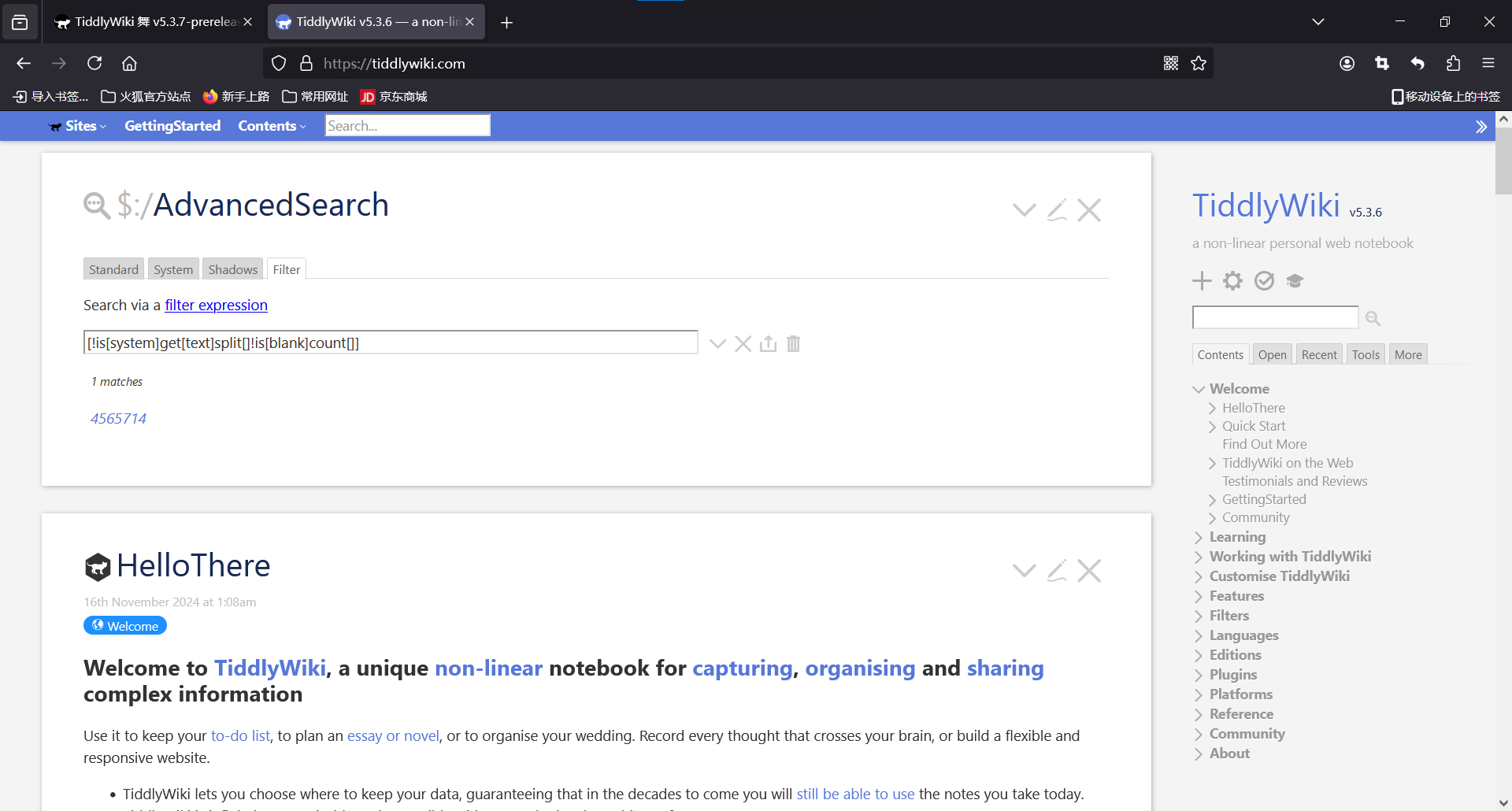
[!is[system]get[text]split[ ]splitregexp[(.)]!is[blank]count[]]
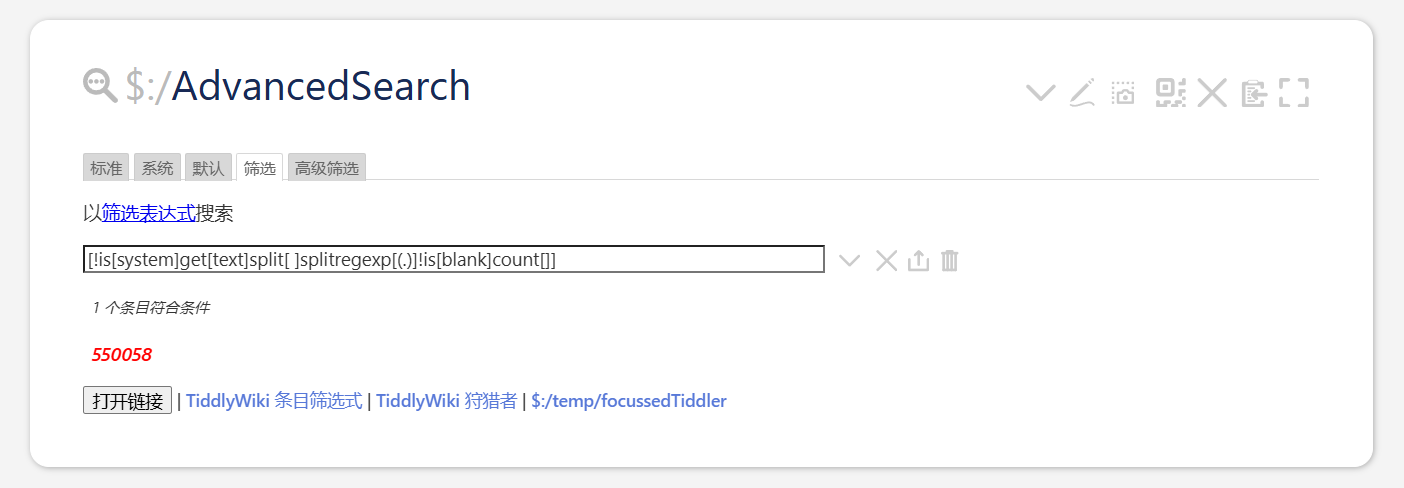
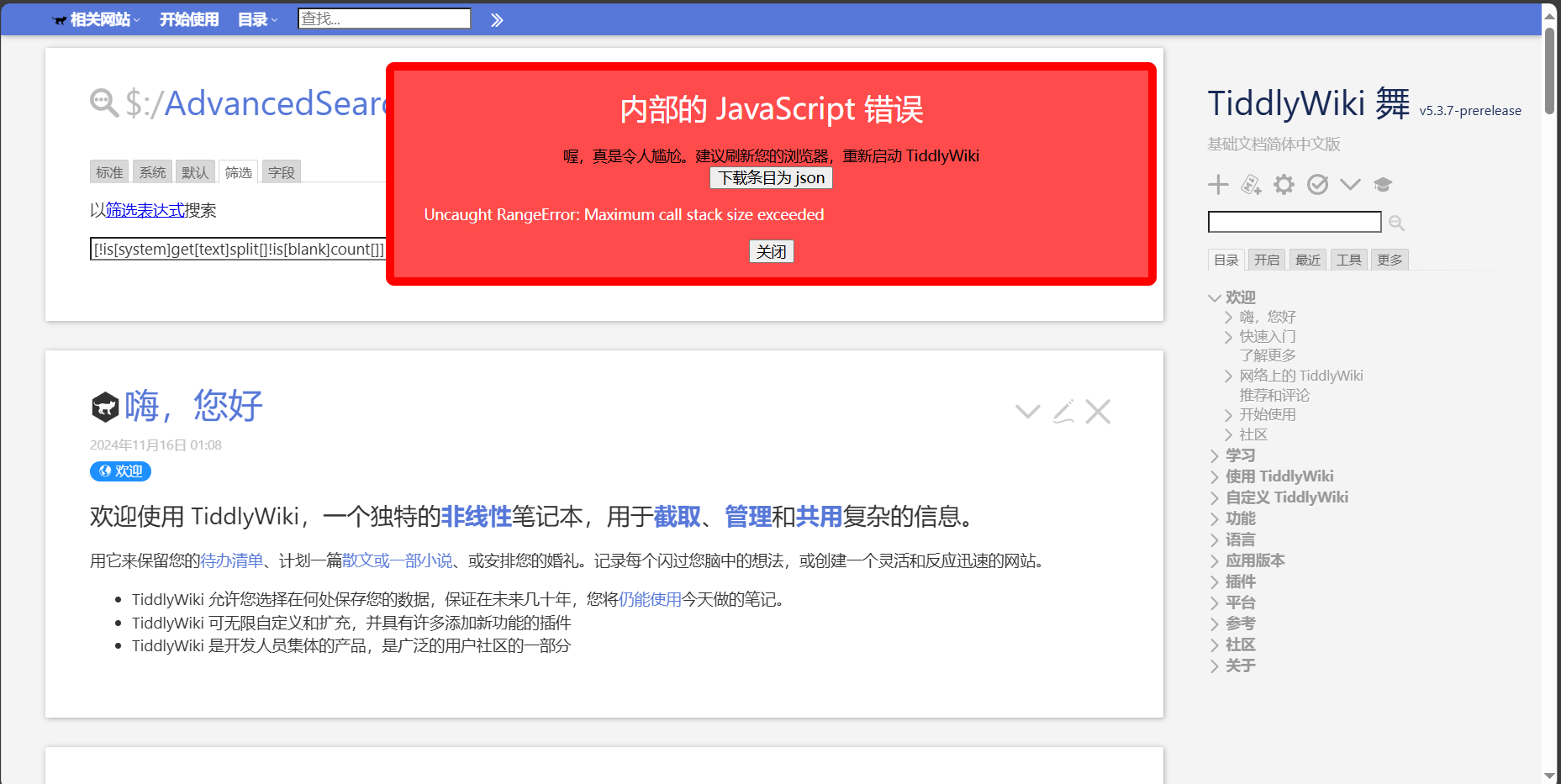
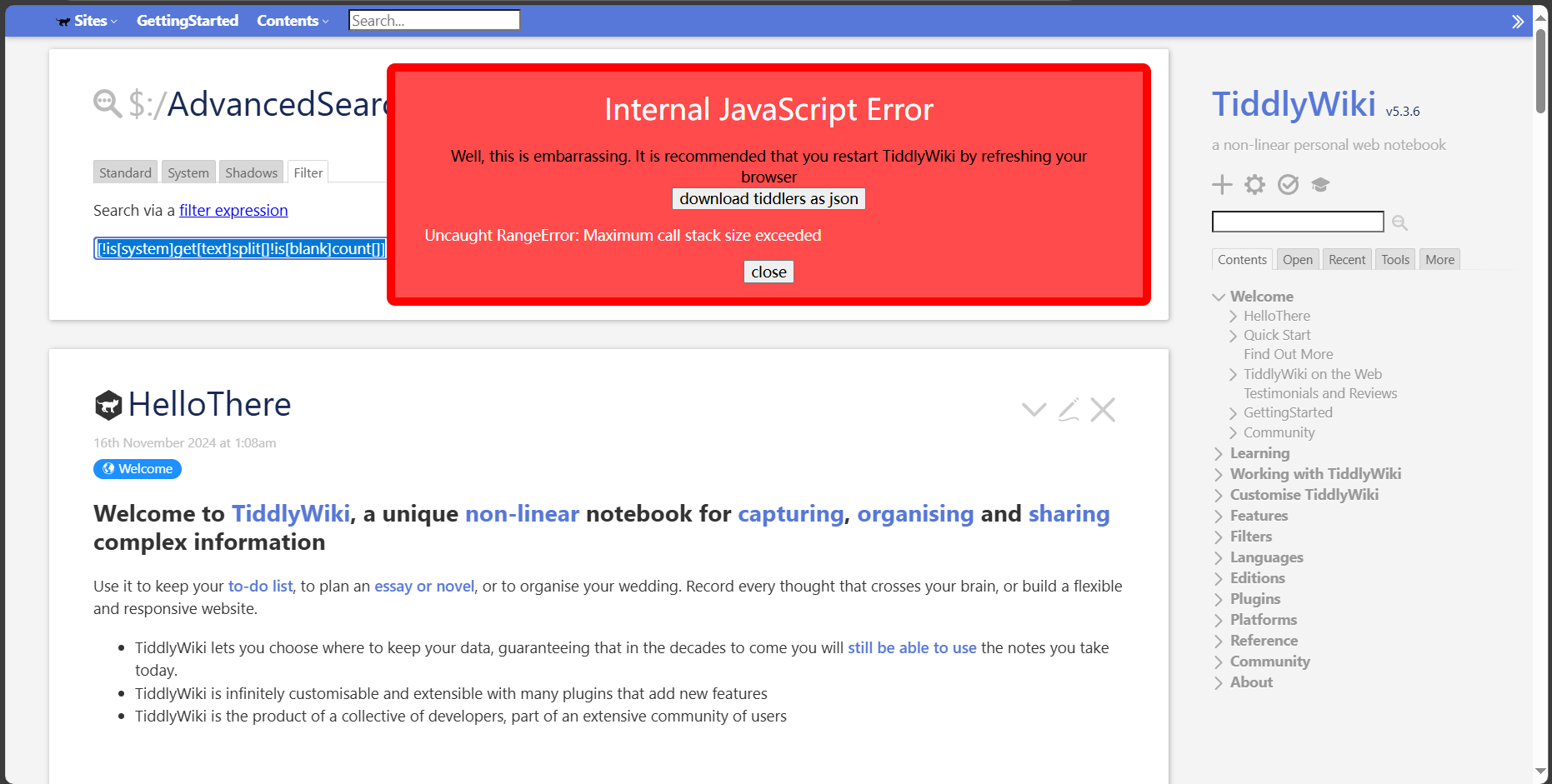
However, the following official tutorials in English and Chinese will not work
It’s possible to have a filter that works for them to count the total number of words?
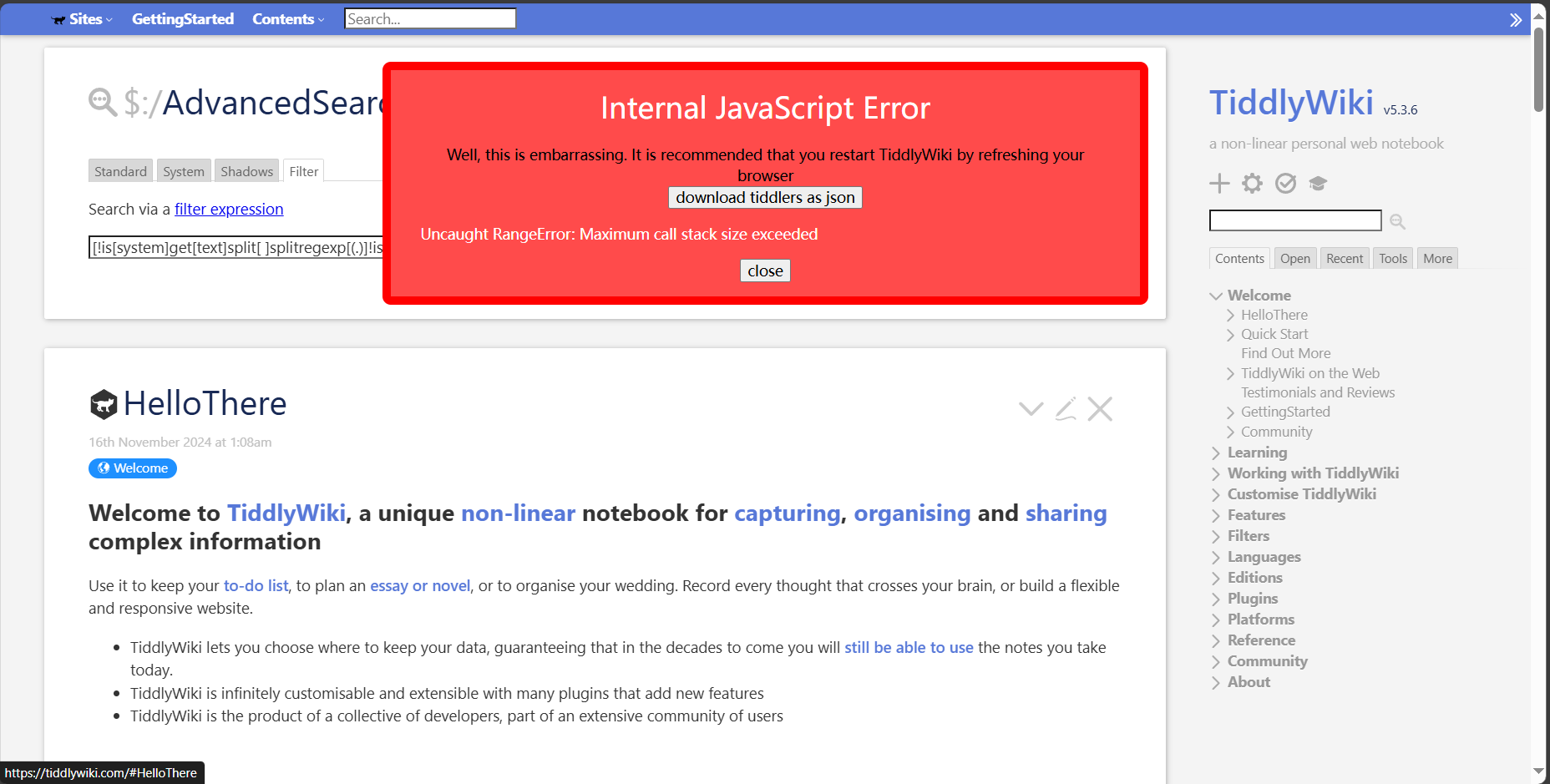
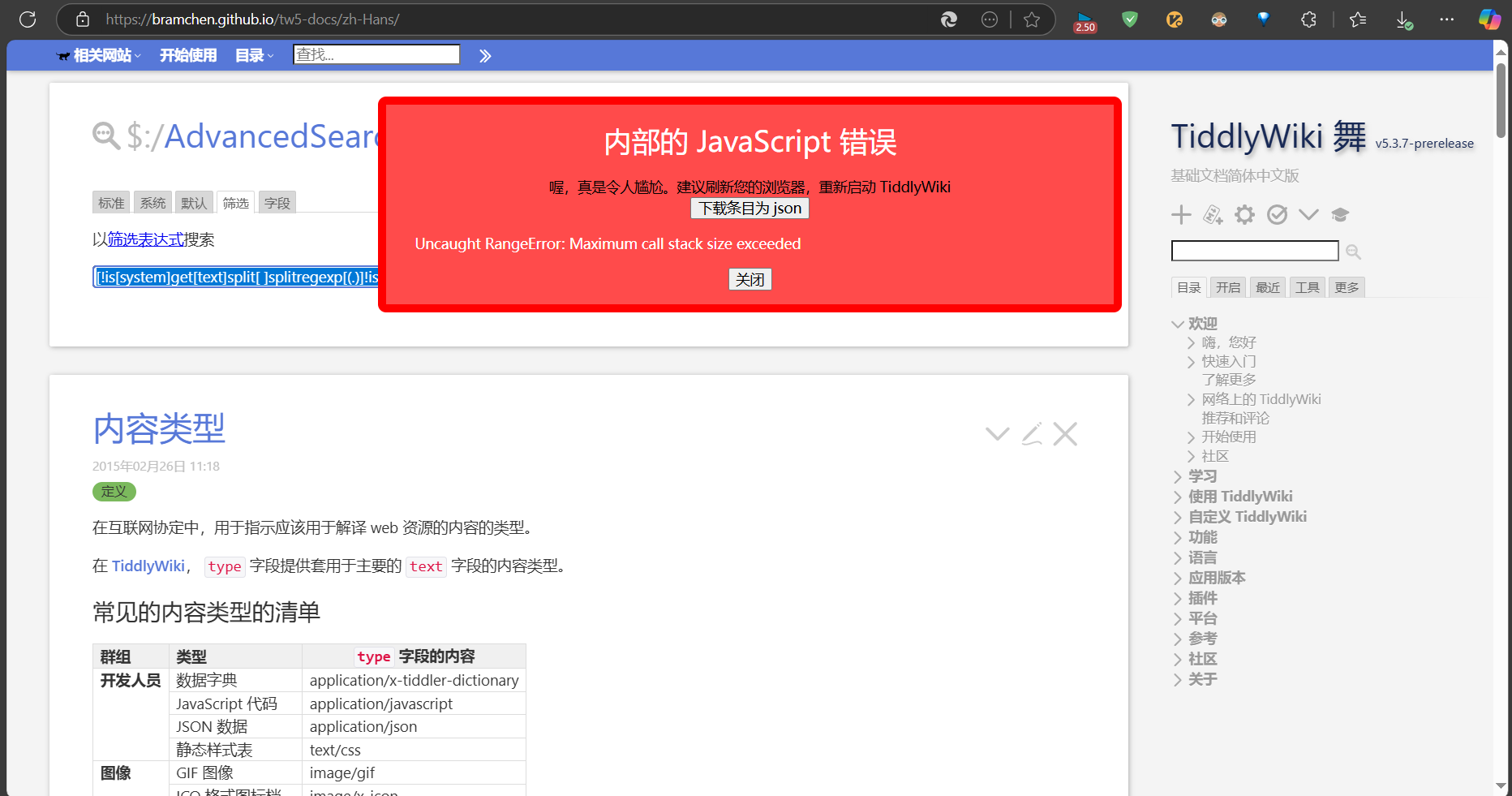
Any reply would be greatly appreciated