New outage, just noticed (Feb 14 21:13 UTC)
I’ll delete post if it comes up very soon. Otherwise perhaps this will catch the attention of @simon …

New outage, just noticed (Feb 14 21:13 UTC)
I’ll delete post if it comes up very soon. Otherwise perhaps this will catch the attention of @simon …
Should be back up now.
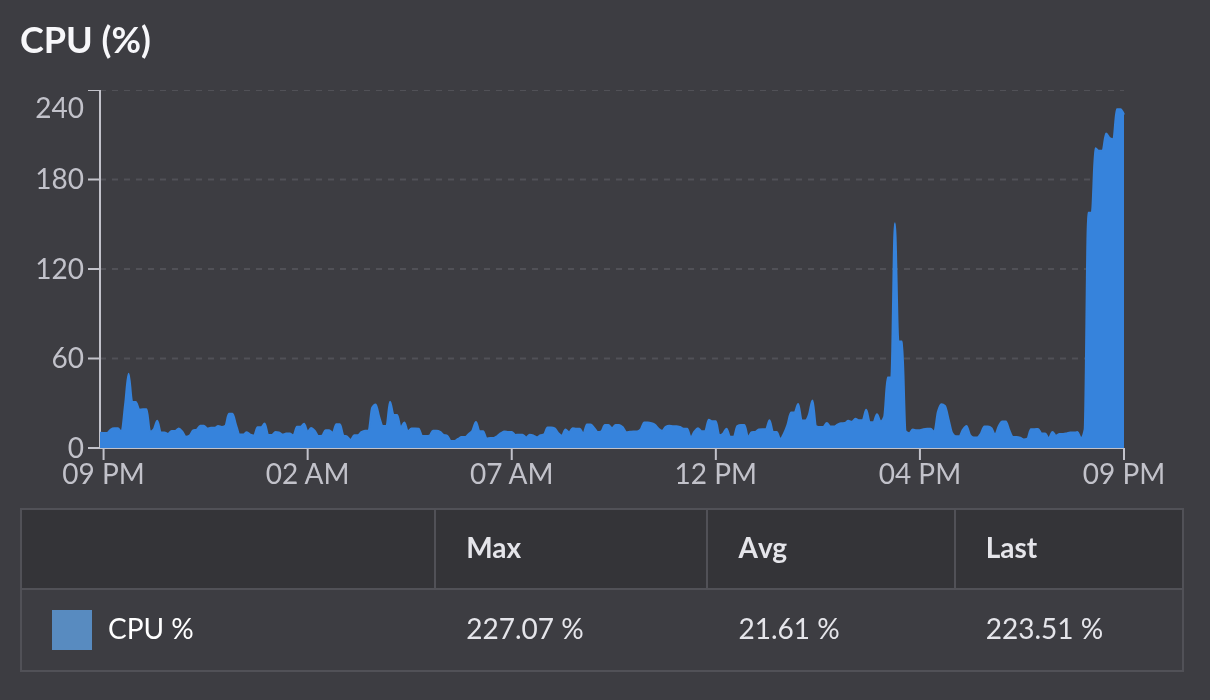
A quick share on what I think is going on:
In this screenshot you can see a smaller spike that it did recover from, and the bigger one from just now, that required a reboot.
So I’m trying to better understand what kind of events cause the load spike, what the tipping point is and how to avoid it, etc. I think that this helped, but I really have enough visibility into what’s going on, especially during the high CPU load. I can pull down log files from nginx, but I don’t have good tools for analyzing them, or tracking metrics (other than the Linode console where that screenshot comes from).
Thanks for your patience, and apologies for the unscheduled downtime. And if you’re a site reliability expert with suggestions on how to make Tiddlyhost more reliable, I’m interested!
I’m just appreciative that you do this at all!
Remember everyone, you can pay some money to tiddlyhost to help Simon cover costs!
Thanks Simon! Much appreciated…
Sorry to be the bearer of bad news @simon, but it appears that there may be another outtage going on right now.
Hopefully it isn’t a scripting attack 
Edit: Possibly not! just as I posted it appears Tiddlyhost is back up and running! Happy to see that it wasn’t anything serious 
Yup, it’s down atm for me.
One possible approach if possible would be to have a script running that tries to see if a number of hosted wikis respond. If out of 10 wikis 10 don’t respond, a server reboot may be initiated or perhaps just an alert message is send to one of several people capable of responding. One check every N minutes, 60 for hourly checks.
The script should not be running on the server itself, as otherwise the script could stop too.
I think the Tiddlytools plugin would be a good place to start, as it has several time functions.
Although TiddlyTools’ $action-timeout widget can be used to periodically invoke wikitext-based scripts that could, in theory, be used to check the status of a remote server (such as Tiddlyhost), this would require the use of a TiddlyWiki that would have to always be loaded into a client-side browser and does not suspend processing when the browser is in the background.
A much better approach for checking server status would be to have a server-side periodic cron job that uses curl with a --connect-timeout parameter to attempt to fetch “a number of hosted wikis” from TiddlyHost. Of course, this server-side cron job would have to be running on a separate server from the one that run TiddlyHost. This is similar to the way https://www.githubstatus.com/ is a separate server that is used to check the operational status of https://github.com.
-e
tiddlyhost still down? 

Looks like it, I just checked.
Would love to have @simon confirm (after this outage event is resolved) whether this kind of system would be easy to set up.
Just as important as the detection routine, however, is the question of what process is triggered if Tiddlyhost is down… As always, my hope is that more people could be in the notification / troubleshooting loop so that no one person is on the hook, 24/7, as the only person who can get Tiddlyhost back online…
Should be back up now, apologies
The automated outage detection and restart is a good idea, I’ll see if I can figure something out.
If the amount of work isn’t too much, I’d recommend rewriting it in golang. I’ve found that backend applications written in golang are less prone to crashing.
No need to know golang. just use AI assist.
This got me really triggered.