Hello everybody on this forum,
first of all I want to say that Tiddlywiki is really great software, very productive, very flexible. Thanks for that.
…and now straight to my issue:
This issue will have been noticed by many non-English users, but it seems that until now it has never been reported, as it is difficult to describe exactly what is not working well there. In addition, the failure is rarely visible.
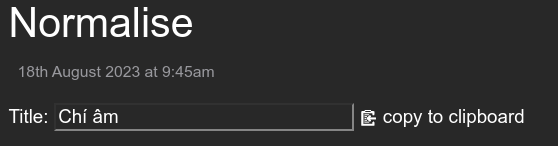
I’m working on a wiki with vietnamese texts about acupuncture and do partial translations into German. During editing, I’ve sometimes noticed that the search didn’t work as expected. Occasionally I also had the problem that links to existing tiddlers were displayed as “missing tiddler”. But that were links that were obviously not misspelled.
To further illustrate this issue I made this demo wiki at tiddlyhost: https://issue-with-nonenglish-unicode-chars.tiddlyhost.com/
For some time I had no idea what could be causing this and how to correct it.
Recently, while doing some research on this topic, I found the following article, which describes the problem very aptly and even offers a possible solution:
https://tech.glints.com/vietnamese-for-engineers/
There seems to be only rather simple changes needed, namely processing all input texts through the string.normalize() method. I don’t have the Javascript experience or time to dig very deep into the Tiddlywiki code. So I would like to ask the experienced code gurus here to take care of this problem.
Is it possible to change the core of an existing wiki with a plugin, or should it be included in the next update? Both would help me a lot, as it would help many other non-English users.
Best regards Michael Schroeder
more articles are here: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/normalize
https://www.stefanjudis.com/today-i-learned/string-prototype-normalize-for-safer-string-comparison/