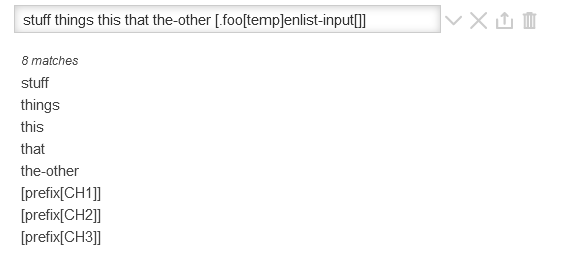
The reason I suggested a global function (aside from reusability and brevity when used as part of a longer filter) is that, once you introduce a :map filter run, it will act on all preceding input. This isn’t necessarily a major issue, but it does mean that any additional titles/filter runs, like @CodaCoder’s stuff things this that the-other, will have to follow the map step:
[[MyPrefixes]get[text]split[ ]] :map:flat[all[tiddlers]prefix{!!title}] stuff things this that the-other
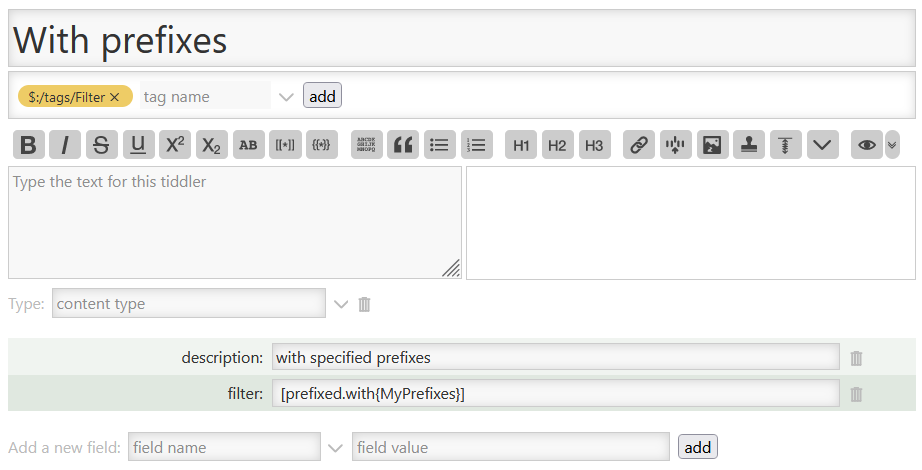
By isolating the :map step in a function with its own selection constructor [enlist{MyPrefixes}] (equivalent, in this case, to [[MyPrefixes]get[text]split[ ]]—though it also allows you to store multi-word prefixes in list format in MyPrefixes) you gain some flexibility in the sequence of filter runs.
You could also define several variants on the same structure and mix and match them within a filter:
\function has.prefix(input) [enlist<input>] :map:flat[all[tiddlers]prefix{!!title}]
\function has.suffix(input) [enlist<input>] :map:flat[all[tiddlers]suffix{!!title}]
\function has.tag(input) [enlist<input>] :map:flat[all[tiddlers]tag{!!title}]
\function has.tag.commas(input) [<input>split[,]trim[ ]] :map:flat[all[tiddlers]tag{!!title}]
[has.prefix{MyPrefixes}] [has.suffix[readme license]] -[has.tag.commas[exclude, a multi-word tag]]
Personally, I’ve been using @CodaCoder’s dynamic filter approach to eliminate long strings like [tag[A]] [tag[B]] [tag[C]] -[tag[D]] -[tag[E]] from my own wikis. [has.tag[A B C]] -[has.tag[D E]] feels much neater!