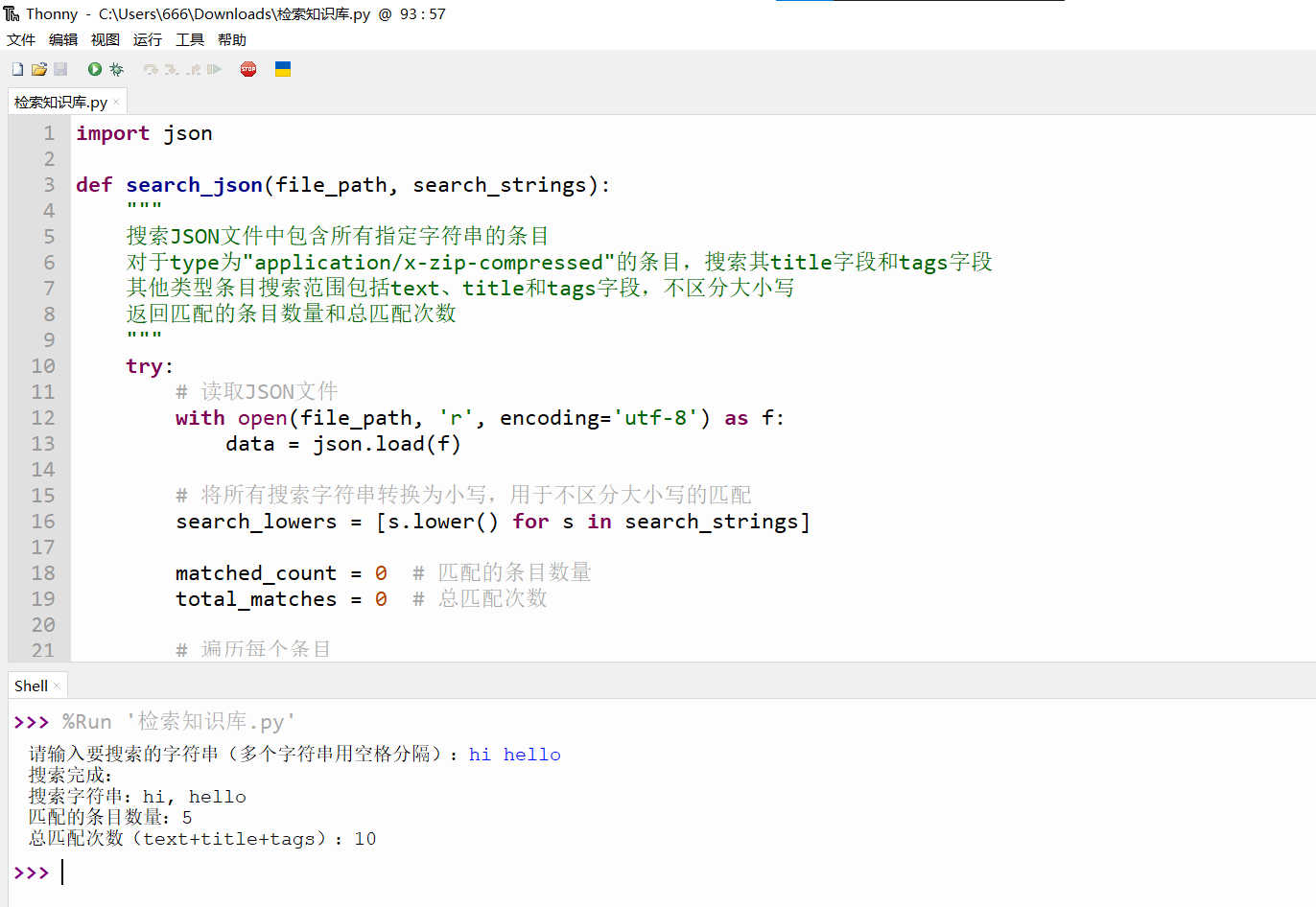
import json
def search_json(file_path, search_strings):
"""
搜索JSON文件中包含所有指定字符串的条目
对于type为"application/x-zip-compressed"的条目,搜索其title字段和tags字段
其他类型条目搜索范围包括text、title和tags字段,不区分大小写
返回匹配的条目数量和总匹配次数
"""
try:
# 读取JSON文件
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 将所有搜索字符串转换为小写,用于不区分大小写的匹配
search_lowers = [s.lower() for s in search_strings]
matched_count = 0 # 匹配的条目数量
total_matches = 0 # 总匹配次数
# 遍历每个条目
for item in data:
item_type = item.get('type')
is_zip = item_type == "application/x-zip-compressed"
item_matches = 0
all_strings_matched = True # 标记是否所有搜索字符串都匹配
# 检查每个搜索字符串
for search_lower in search_lowers:
string_matched = False # 标记当前搜索字符串是否匹配
# 对于非zip类型,检查text字段;zip类型不检查
if not is_zip and 'text' in item:
text_content = str(item['text']).lower()
if search_lower in text_content:
string_matched = True
item_matches += 1
# 检查title字段 - 所有类型都检查
if 'title' in item and not string_matched:
title_content = str(item['title']).lower()
if search_lower in title_content:
string_matched = True
item_matches += 1
# 对于所有类型都检查tags字段(修改点:删除了对zip类型的限制)
if 'tags' in item and not string_matched:
tags_content = str(item['tags']).lower()
if search_lower in tags_content:
string_matched = True
item_matches += 1
# 如果有任何一个搜索字符串不匹配,整个条目不匹配
if not string_matched:
all_strings_matched = False
break
# 如果所有字符串都有匹配,更新统计
if all_strings_matched and item_matches > 0:
matched_count += 1
total_matches += item_matches
return matched_count, total_matches
except FileNotFoundError:
print(f"错误:找不到文件 {file_path}")
return 0, 0
except json.JSONDecodeError:
print(f"错误:文件 {file_path} 不是有效的JSON格式")
return 0, 0
except Exception as e:
print(f"发生错误:{str(e)}")
return 0, 0
if __name__ == "__main__":
# 要搜索的文件路径
json_file = "tiddlers.json"
# 要搜索的字符串,支持空格分隔多个字符串
search_input = input("请输入要搜索的字符串(多个字符串用空格分隔):")
search_strings = [s.strip() for s in search_input.split() if s.strip()]
if not search_strings:
print("错误:请输入至少一个搜索字符串")
else:
# 执行搜索
matched_count, total_matches = search_json(json_file, search_strings)
# 显示统计结果
print(f"搜索完成:")
print(f"搜索字符串:{', '.join(search_strings)}")
print(f"匹配的条目数量:{matched_count}")
print(f"总匹配次数(text+title+tags):{total_matches}")
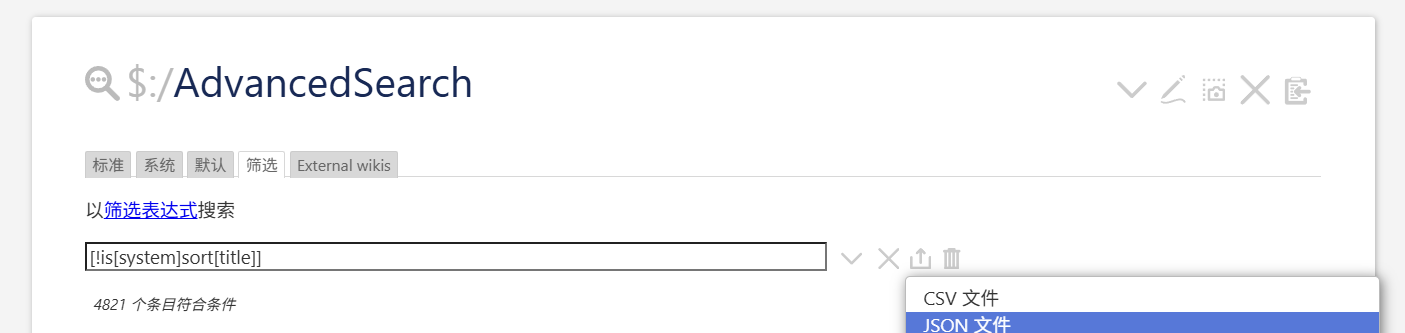
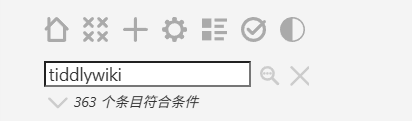
Test individual search terms
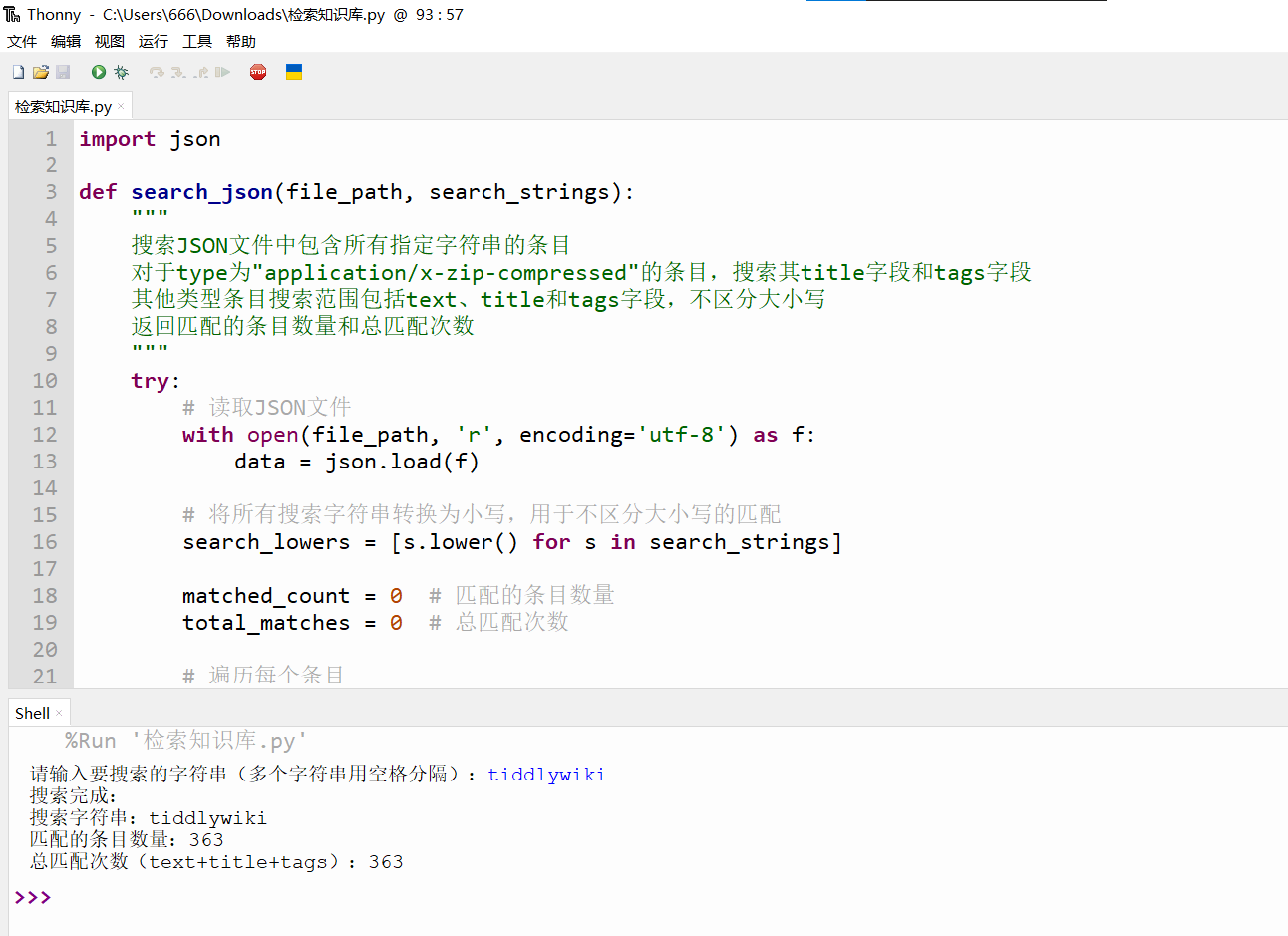
Test federated search for multiple search terms