… that it doesn’t quite do what it says on the tin:
words: (the default) treats the search string as a list of tokens separated by whitespace, and matches if all of the tokens appear in the string (regardless of ordering and whether there is other text in between)
With my emphasis …
words: (the default) treats the search string as a list of tokens separated by whitespace, and matches if all of the tokens appear in the string […]
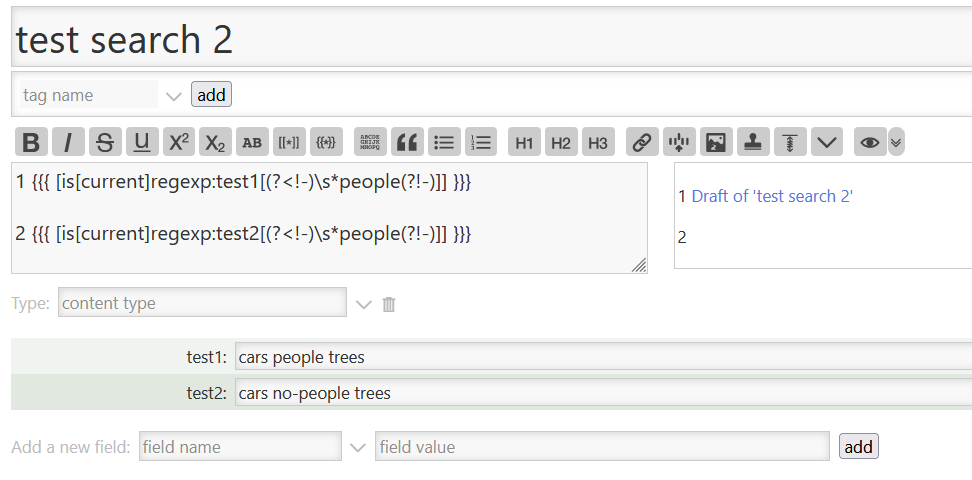
I don’t think that’s actually what it does. It seems to consider only “tokens” (i.e words) broken not even by word boundaries.
Try this on TW.com
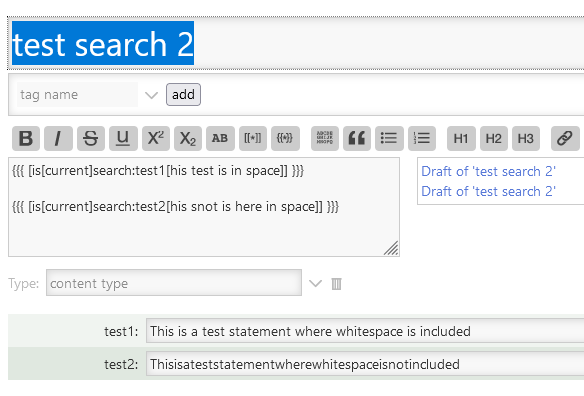
tiddler: test search
test: one-two one-two-three
text: {{{ [is[current]search:test[one]] }}}
Since “one” is not a “token separated by whitespace”, search should not write anything to the output.
This, just for fun…
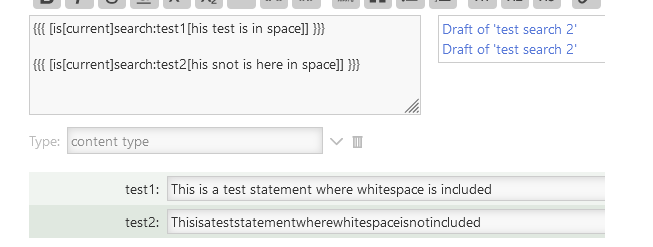
tiddler: test search
test: Was this really what you had imagined mate?
text: {{{ [is[current]search:test[his hat was a real mat]] }}}
Clearly, whitespace has no bearing on the matter at all. (Couple hours of my life I won’t get back.)
If I can remember how, I’ll submit a PR for the docs – at the very least, I’ll try to make it less misleading.