TW has “dash” -, “endash” -- and “emdash” --- … In your example you only use the single dash.
Here’s a regexp, that returns 3 backreferences + detailed description. The regexp works for 1 word-dash combination. So for your example it would need to be done 3 times
The 1st backreference contains every character except those in the list: ,<space>- comma, space, dash
The 2nd backref. contains the “spacers”, m-dash, n-dash, dash, <space>
The 3rd beckred. contains every char except ,<space>
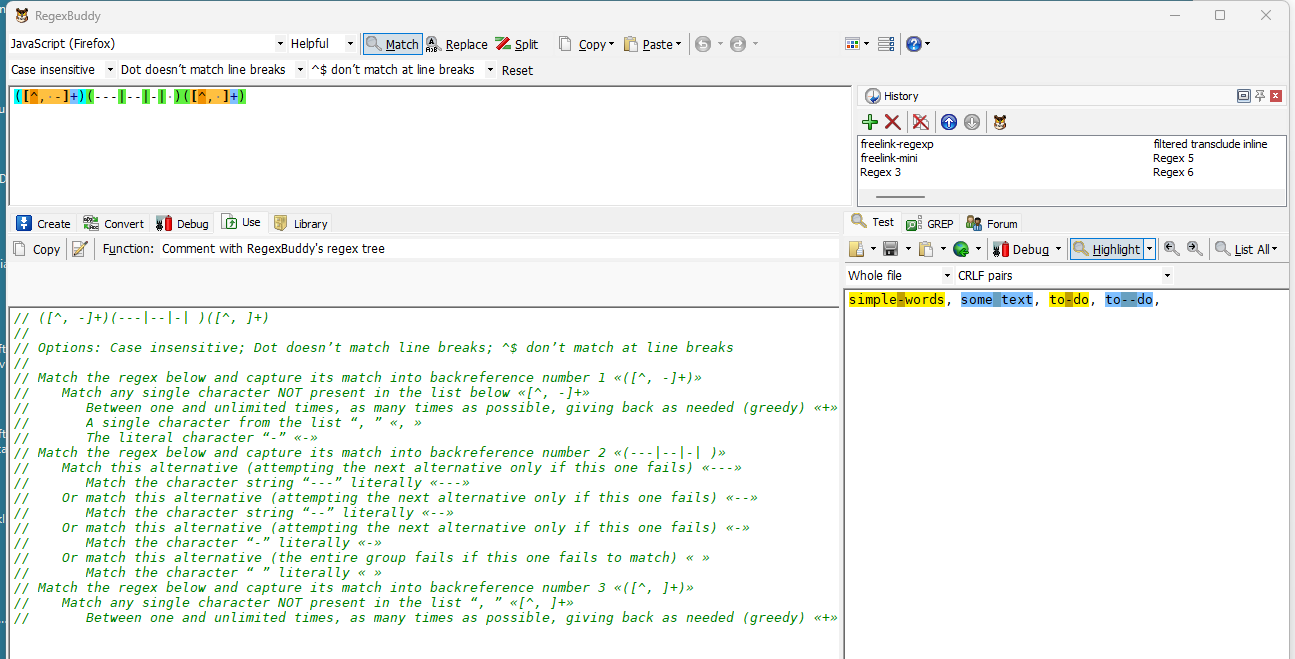
([^, -]+)(---|--|-| )([^, ]+)
// ([^, -]+)(---|--|-| )([^, ]+)
//
// Options: Case insensitive; Dot doesn’t match line breaks; ^$ don’t match at line breaks
//
// Match the regex below and capture its match into backreference number 1 «([^, -]+)»
// Match any single character NOT present in the list below «[^, -]+»
// Between one and unlimited times, as many times as possible, giving back as needed (greedy) «+»
// A single character from the list “, ” «, »
// The literal character “-” «-»
// Match the regex below and capture its match into backreference number 2 «(---|--|-| )»
// Match this alternative (attempting the next alternative only if this one fails) «---»
// Match the character string “---” literally «---»
// Or match this alternative (attempting the next alternative only if this one fails) «--»
// Match the character string “--” literally «--»
// Or match this alternative (attempting the next alternative only if this one fails) «-»
// Match the character “-” literally «-»
// Or match this alternative (the entire group fails if this one fails to match) « »
// Match the character “ ” literally « »
// Match the regex below and capture its match into backreference number 3 «([^, ]+)»
// Match any single character NOT present in the list “, ” «[^, ]+»
// Between one and unlimited times, as many times as possible, giving back as needed (greedy) «+»
hmm. There are languages which have different characters than included here. IMO the only way to catch all possible characters is to go with a pattern, that includes every possible char and excludes the separators.
I’m confused why you would specifically want to exclude capitalizing some text … maybe you’re just trying to draw attention to the hard parts?
I wonder whether a workable solution effectively replaces each hyphen with hyphen-plus-space, then capitalizes as usual, and then re-collapses each hyphen-space combination.
As far as I know, there is no place where hyphen is appropriately followed by a space…
… Actually, some people use two hyphens to represent an em-dash — like what sets this phrase apart — so I guess those shorthand em-dashes (--) would need to be corrected before doing any of that handling of actual hyphens (which you’re calling “dash” here).
I don’t understand why the version below doesn’t work. It does the proper thing with the hyphenated words, but strips out sapces. I can fix it with Charlie’s space conversion/restoration process, but I don’t know why that’s necessary.
This is the code:
<$let
in="simple-words, some text, to-do"
pat=(\w)(\w*)(-+)(\w)(\w*)
rep="[[$1]uppercase[]addsuffix[$2]addsuffix[$3]] [[$4]uppercase[]addsuffix[$5]] +[join[]]"
>
This vanilla JS equivalent works just fine:
"simple-words, some text, to-do".replace(
/(\w)(\w*)(-+)(\w)(\w*)/gm,
(_, a, b, c, d, e) => a.toUpperCase() + b + c + d.toUpperCase() + e
) //=> "Simple-Words, some text, To-Do"
Can someone explain why spaces – not captured by the regex – are removed with this call to search-replace?
Thanks. I got that from your earlier response, and I do understand what you’re doing with the multiple replaces – adding a placeholder for spaces, then replacing that placeholder with &nbps; – but my last two attempts above don’t use the <$list> widget; one uses <$text> and the other uses a <$let> variable. Am I implicitly using <$list>? Or is something else going on?
I’m sure it’s me being dense about syntax again, but I don’t see what’s wrong with them.
The text widget just takes the string coming at it and spits out that string without evaluating it. Curly bracket content gets evaluated, then text widget spits that out as-is.
The list widget takes a string and evaluates it. Curly brackets get evaluated, then the list widget evaluates the result of the curly bracket.
We need double evaluation. Triple curly brackets cause one evaluation, and then list widget causes another evaluation.
The only other widget you can use instead of list widget for second evaluation is the wikify widget. (TW 5.2.3 viewpoinr)
But that still strips out spaces. Obviously I can use Charlie’s technique, but I really want something simpler to work. I may simply have to get used to disappointment.
It may not be relevant but when splitting titles or strings to perform operations on them you can use +[join[ ]] containing a space to rejoin them restoring the spaces.