
I’m putting this in the developer category because after trying to find what I was doing wrong, I think the problem is something deeper and too deep for me.
I was trying to use the Levenshtein operator on csv strings and getting results from computations that didn’t make sense. I think it is relevant that my strings are expected to be quite different at this stage except for the fact that being csv strings, they will have a few commas in them.
If I understand Levenshtein distance correctly, the largest possible distance between two strings is the number of characters in the longer of the strings. As I dug into why my calculations seemed off I found that I was sometimes getting Levenshtein distances that were greater than the length of the longer string.
I assumed I was just feeding the operator something other than intended since I was calculating my strings in filters but I have now tested filter defined strings, strings stored in fields, strings stored using \define and hard coded strings (e.g. [[cat]levenshtein[dog]] ). When the strings are completely different (like cat and dog) or very similar (cat and cot) the results are as expected but when the strings are very different except that they have a character or two in common in very different positions the distance returned can be greater than the length of the longer of the two strings.
For example [cat]levenshtein[dogc] returns 5 when it is really a 4 character operation to turn one into the other.
I made a little test tiddler than can show the effect of inserting a single a string (shows the problem best with a string consisting of a single character but longer strings work) into 2 strings that are completely different (I used upper and lower case versions of each other for clarity) and then calculating the distance and comparing it to the maximum possible distance (see https://levenshtein-test.tiddlyhost.com).
From looking at a lot of different versions of the table (different string lengths and insertion positions for the common string), it looks to me like the algorithm is making whatever additions or deletions are needed before the common section in order to make the common section of the two strings line up (so in the cat dogc example above, it makes 3 deletions from the beginning of dogc to line up the c in both strings, then 2 additions ( a and t) to the end of the string to get cat. That method works in many cases but in this case gives a distance of 5 but just deleting the c in dogc and replacing dog with cat is the better operation in this case and gives a distance of 4, which is the expected maximum.
Here is an example of the table showing a series of bad distances-
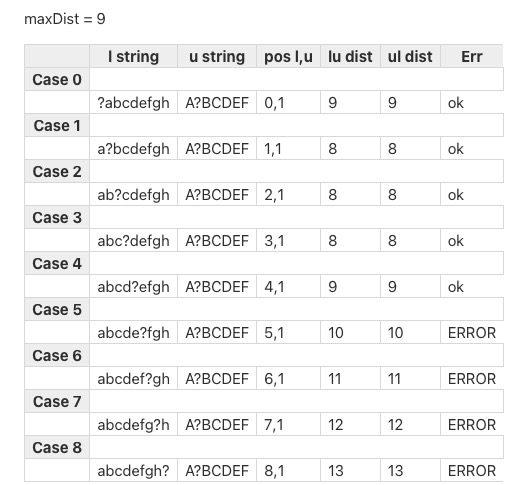
Entries in the table marked ERROR are just the ones where the distance calculated exceeds the maximum distance. There may be cases when the calculated distance is less than the maximum but still greater than what it should be.
Unless I have misunderstood something about how this operator is supposed to work or I’m doing something silly, I think I have gotten as far as I can with understanding this.
Thanks for any feedback!