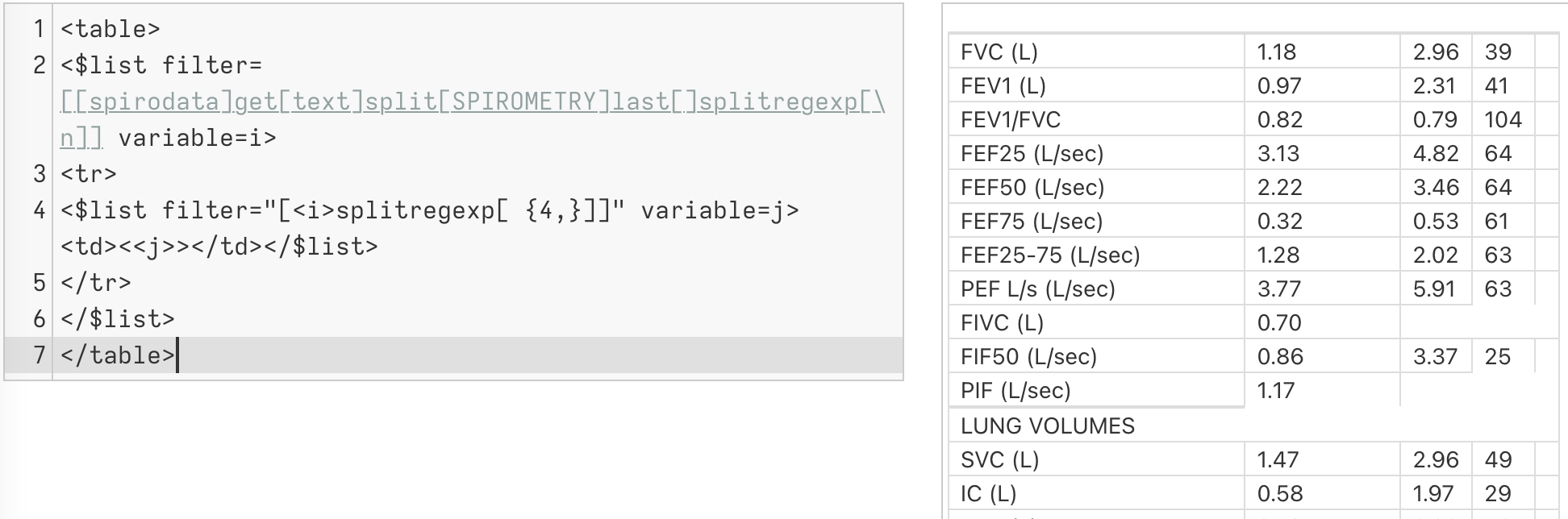
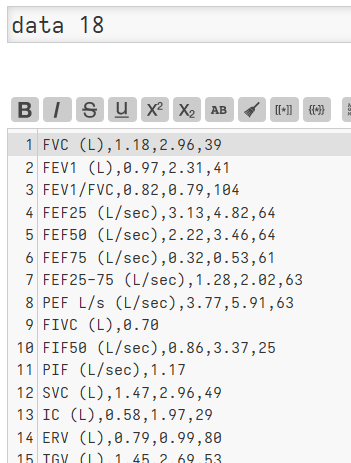
I would like to parse plain text data like that below using TW.
From what I can see you can’t use regular expressions to chop text up (only to match).
I must say I haven’t even been able to split the text into lines!
The desired output is a single data tiddler with fields like Name, Doctor, FEV1 etc.
Can someone get me started?
Thanks
Nick
Name: DOE,JOHN ID: T123456
Doctor: Riviera, Nick, Dr Height: 162.00 cm Age: 65
Technician: Bob, Sideshow Weight: 73.50 kg Gender: Female
Visit Date: 11/01/2023 Time: 08:42 Race: White
Diagnosis:
Dyspnea:
Cough:
Wheeze:
Years Quit: Packs/Day:
Years Smoked: Tobacco Product:
Comments: FVC likely sub-maximal due to coughing and some glottis closure so
please view with caution.
Variable lung volumes technique so only 2 technically acceptable attempts
achieved today so please view with caution.
Variable transfer factor technique, only 1 technically acceptable attempt with
the sample value only being 450ml.
Hb was tested using a HemoCue in the department today.
A six minute walk test was also performed.
PRE-BRONCH POST-BRONCH
Meas Prd %Prd Meas %Prd %Chg
SPIROMETRY
FVC (L) 1.18 2.96 39
FEV1 (L) 0.97 2.31 41
FEV1/FVC 0.82 0.79 104
FEF25 (L/sec) 3.13 4.82 64
FEF50 (L/sec) 2.22 3.46 64
FEF75 (L/sec) 0.32 0.53 61
FEF25-75 (L/sec) 1.28 2.02 63
PEF L/s (L/sec) 3.77 5.91 63
FIVC (L) 0.70
FIF50 (L/sec) 0.86 3.37 25
PIF (L/sec) 1.17
LUNG VOLUMES
SVC (L) 1.47 2.96 49
IC (L) 0.58 1.97 29
ERV (L) 0.79 0.99 80