Ref: A Filter Question: “Fullname, F. M.” - Discussion - Talk TW (tiddlywiki.org)
Question 1: How to split a full name into first, middle and last names? Code shall handle the name contains Nobiliary particle?
Example i:
“Ludwig van Beethoven” shall be parsed into
Ludwig
van Beethoven
Example ii
“Michael Joseph Jackson” shall be parsed to
Michael
Joseph
Jackson
I started with some KISS code like this
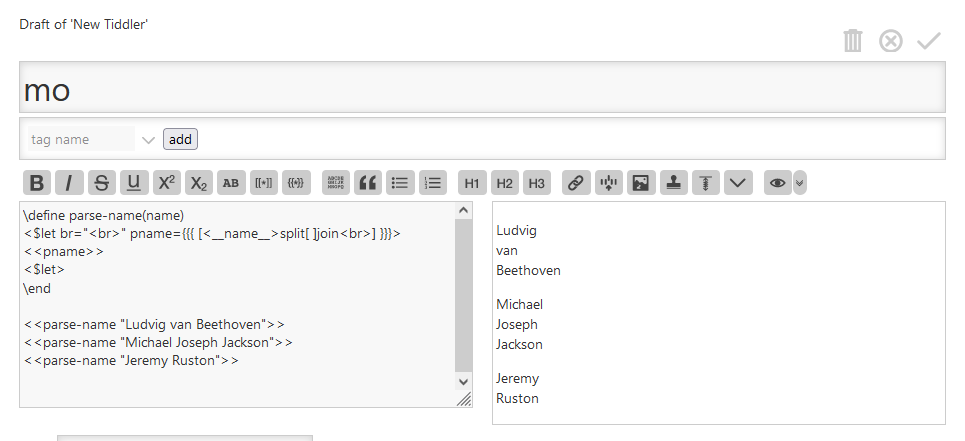
\define parse-fullname(name)
<$let name=<<__name__>>
pattern1="\b(?=[a-z])"
pattern2="\s"
>
<$list filter="[<name>splitregexp<pattern1>trim[]] :filter[<name>splitregexp<pattern1>trim[]count[]compare:integer:gteq[2]]">
<$text text=<<currentTiddler>> /><br/>
</$list>
<$list filter="[<name>splitregexp<pattern2>trim[]] :filter[<name>splitregexp<pattern1>trim[]count[]compare:integer:eq[1]]">
<$text text=<<currentTiddler>> /><br/>
</$list>
</$let>
\end
# <<parse-fullname "Ludwig van Beethoven">>
# <<parse-fullname "Michael Joseph Jackson">>
# <<parse-fullname "Jeremy Ruston">>
This produces correct outputs
-
Ludwig
van Beethoven -
Michael
Joseph
Jackson -
Jeremy
Ruston
I am looking for simpler solution.
What is a better regex to parse the full names in one go?