
Note this from Yaisog’s explanation above:
No, the reason is the missing filter run in neighbors, this run shall be added [enlist<backlinkedTiddlers>]
More comments:
I think it is good to have a terminology section to describe what is each node!
link
backling
tagged
tagging
sharedTagedTiddlers or spouce
There is an incomplete list of terms here: Shiraz 2.7.2 — create stylish contents in Tiddlywiki
but as the nearby neighbors has a litlle complex set of filters, to better understand it, I would suggest to add this terminology section
If you’re talking about the code in Yaisog’s first post to this thread, then I don’t see that backlinkedTiddlers is even defined. I thought the explanation I quoted was the reason. Yaisog believes these are too expensive to calculate for something like this. But maybe I missed the definition somewhere.
@Yaisog has attached his tuned solution later in post 21 → Nearby Neighbors Plugin: POC release - #21
1 Like
This thread is fascinating! Looks useful!
BUT it got very esoteric.
I hope the outcome gets published in an understandable form for mortals like me.
Just a comment
TT
Hi Mohammad,
you’re exactly right, the backlinkedTiddlers filter run was missing. I have updated the JSON-File in my Post #21 accordingly.
I’ll try to get around to define things a bit better. But where should I put that? Comments inside the tiddler? I would like this little project to not grow beyond a single, simple tiddler. I wouldn’t mind if someone turned this into a plug-in, with “real” configuration tiddlers and all. Unfortunately, I don’t think I have the time for that.
I don’t think it’s really worth the effort. You can just download the single, self-contained tiddler from Post #21 and drop / import it into tiddlywiki.com. It’ll be immediately functional and you’ll have your demo site.
Have a nice day
Yaisog
1 Like
I think this is fine! may be at the start or end of tiddler. I would recommend defining terms (as you did partially in post 21).
A dedicated thread for WikiText solution tagged with Tips and Trips would be beneficial.
1 Like
I’m not sure what Yaisog’s plans are, but I expect to continue to make changes as I have time and to post the results as new point releases to my plugin. I don’t want to call this anything even close to an alpha release yet, as I’m still trying to figure out if what I want to do is even remotely achievable for someone with my skills. But I’ll keep trying.
I don’t think I want to take it as far as you. I like where my neighbors list ViewTemplate is right now, as this is about as much as I need for my wikis. I just wanted to see if WikiText can be leveraged to obtain a solution. I have tried a bunch of approaches to find the best and most flexible one, and I am happy with the result.
Actually, I will need to figure out if this list of neighbors is even useful in my daily work. My wikis are set up in a way to show each tiddler’s parents and children, as well as the manually curated related field – this latter one being much used on a regular basis. The neighbors list might help when browsing, but not really when looking for information, which is what I use the wikis most for.
Anyway, @Mohammad has already proven that he understands my code and maybe wants to take this further, into a plug-in?
Have a nice day
Yaisog
1 Like
Published a new minor version. The previous one is available at 0.0.2. Not much to see here. I’m still noodling on the big changes, but just crossing off minor to-dos. Details are in the Changelog.
3 Likes
I feel the same. I believe Node Explorer in Shiraz gives more usable information and I use it in my Wikis. Using @Yaisog solution on https://tiddlywiki.com, for example on HelloThere shows 35 neighbors most of them because have the same TableOfContent tag.
I think this is the best solution for most real cases and worth to be discussed and documented in a separate thread
Absolutely!
The current solution is invaluable as it shows how WikiText and filter query language of TiddlyWiki can solve complex problems! The use of set to store intermediate results, the filter run prefix, enlist:raw, have important points to learn in this solution.
Using Gatha, this can be converted to a plugin easily (few clicks), but like Node Explorer in Shiraz, which is distributed as bundle of few tiddlers (lite has 1 tiddler, full has 4 tiddlers) and not packaged in Shiraz, I suggest keeping neighbors like that. This way it is more hackable and customizable.
I will start a new thread as wiki and move @Yaisog WikiText solution there under Tips and Tricks.
I would sugget to have the TW5-Nearby plugin discussion in more clear way @Scott_Sauyet may also start a new thread for the next release of GitHub - CrossEye/TW5-Nearby. So, following up both solutions can be easier.
I’m not sure about Yaisog’s version, but I expect mine to be useful more in cases where the reader of the wiki is less intimately connected with it than the author. Various other Node explorers, including the one in Shiraz may always be helpful to the author. Although I didn’t know these others when I started mine, I might describe mine as a helpful gloss on the information those offer. It focuses only on the closeness/distance between various tiddlers. But if I ever get there, this gloss might allow for some interesting visualizations.
2 Likes
This is what other node explorers have not covered! So TW5-Nearby is of my interest and I am sure it will get enough attention. So, please keep going on. If a flexible graphical representation is added, then it would be a killing tiddler relationship explorer 
1 Like
Hi @Scott_Sauyet - I tried your plugin this morning in my railroad tiddlywiki. This wiki has over 5,000 tiddlers with nearly 2,000 of those tagged “Railroads.”
I do like the concept, but I would ask that there be some configuration options. With nearly 2,000 tiddlers with the same tag, I find the relation shares the same tag rather useless and cumbersome. I would like to turn that particular relation off or give it a lower score.
Also, I’m assuming because I have so many tiddlers, performance is very sluggish. I’ve attached a screenshot from the performance plugin for reference.
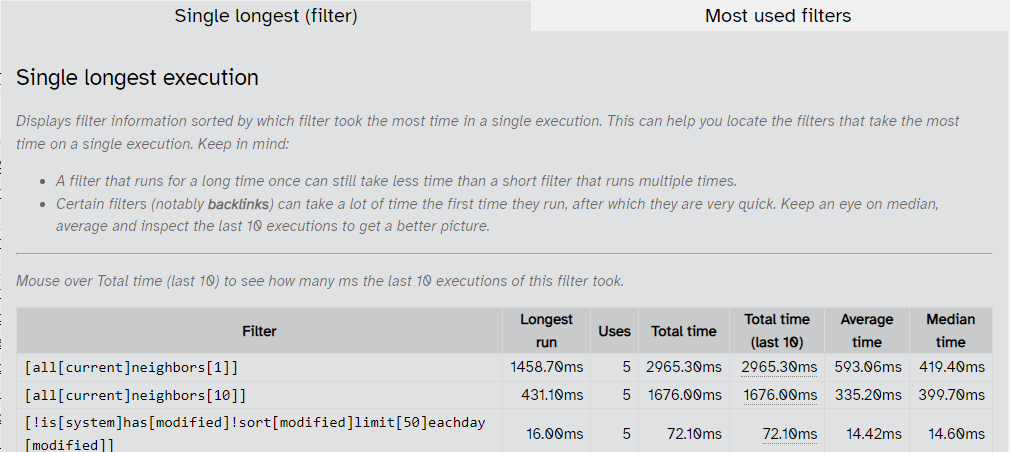
That’s absolutely the plan. The more I think about it, the more configuration I can see, to the point where organizing it might become difficult. But I expect to offer simple weighting for some factors, such as links/backlinks, say 8 points. For others we might choose to have multiple weights, e.g.: 5 points for the first tag the two have in common, 3 points for the next one, 1 point for all subsequent ones. That’s a bit awkward to configure if we also want to allow 5 points for the first, 3 for the second and nothing after that, although I suppose we can use some configuration like 5-3-1 versus 5-3-0. It’s just hard to square with the simplicity we’d like to use for plain weights.
Your experience suggests that we should also add a blacklist of tags to ignore during calculations. I imagine more things like this will creep up.
I originally was planning on moving on to the harder problems first, but I’m still thinking through them, so I will probably do some work on configuration next. It won’t be tonight, but probably over the weekend. Suggestions are more than welcome!
I don’t think it will make much of a difference, but it’s already been pointed out that I can replace all[current] with is[current] or <currentTiddler> for a performance improvement. My guess is that’s not going to materially affect the numbers you’re seeing, but I won’t know until I try. Presumably the best help for you would be the ability to skip certain factors and blacklist certain tags.
Is your wiki online, by any chance? If I start playing around with performance, I would love to try it on something that large. So far, my largest test case it tiddlywiki.com, with 1500 tiddlers and no obvious performance problem.
Please note that I called this a proof-of-concept. I’m hoping people will try it out and report back what works and doesn’t work, but I wouldn’t expect it to be ready for real-world use for at least a few more versions.
Scott,
Thanks for investigating this and the input from others is proving invaluable in the long run. Please try and document the algorithm at a high level so a general audience can have a little insight without a deeper understanding. I will help if needed.
- The key is we need people to know when it is suitable for use.
- Just to be clear I am confident the order of better performance to less perfdormance is as follows
-
[<currentTiddler>]reference to pre-set variable -
[all[current]yes sounds slower thanis[current]but more prefaomant. -
[is[current]]apparently not recommended.
This has being learned by me as a result of others advice who know more than I do.
Also;
Take advantage of indexed filter operators. The following constructions at the start of a filter run will be optimised to run many times faster than otherwise see Performance
- I am not sure how JavaScript solutions can leverage this.
What is interesting about this nearby tiddlers discussion is the “can of worms” it is opening when it comes to how we value and compare the different kinds of relationships between tiddlers. As an IT professional with lots of Knowledge (KM) and Information management (IM) experience it is of particular interest to me, I am happy to “geek out on this” but I also hold the value that we are democratising KM/IM, creativity and discovery in TiddlyWiki.
- Whilst it is easy for a professional to quickly visualise the different relationships, I suspect you and I are in this group, it is much harder for people new to organising complex information, and some data is just hard for everyone.
- I also have come to suspect this type of analysis is going to be somewhat dependant on the way the data it seeks to tame.
- As mentioned before, I am developing tools to build a “network” of related tiddlers in part because a network structure is possibly going to benefit most from a nearby tool, and a critical or shortest path tool.
Love your work
Tony (is that correct, you do go by Tony, right?),
Thanks for the encouragement and guidance.
I will document things as I develop them further. I’m still in the playing-around stage. But I want to get to a shortest-path implementation in the next week or so, and then look at graphical representation after that. The first I’m sure I can do; the latter will be a learning experience for me. I played around with force-directed graphs a few years ago, but that’s my only automated graph layout experience.
Thank you. I seem to have misremembered (and was too lazy to look up what you said). So thanks for the correction.
I’m still pretty convinced that this will end up being a JS solution. I will certainly code it that way first. I simply can’t imagine Dijkstra’s algorithm being written efficiently in wikitext. Maybe this is just a fault in my imagination. I’d love to be shown wrong. But that’s for calculating the shortest paths. After that, perhaps there can be more core TW in the presentation. And I’m guessing that efficient JS won’t be too hard to come by. But a large wiki (@HistoryBuff is testing on a 5000-tiddler wiki) might simply be beyond the capacity of a tool like this. OTOH, the current, simpler, implementation seems to work fine on the 1500+ tiddler tiddlywiki.com.
Yes, I wasn’t really expecting that. I figured I’d make it configurable since people will have different ideas about the weightings of the factors, but I will play around to figure out what seem to be sensible defaults. For now my choices are entirely arbitrary (well, except that the numbers are drawn from the Fibonacci numbers, just for fun.)
I want to keep pointing out that the way I’m capturing information here is a gloss. It will probably be more useful to those with less understanding of the data. But such tools can sometimes be surprisingly informative to those with greater understanding too. I find that if I create a diagram of a complex system, and then tweak it a bit, moving things around almost at random, I can find some underlying principles I didn’t know were lurking there. This might on occasion lead to such insights.
But that’s not the goal. This is mostly meant for people to have an intuitive way to surf the data without depending on rigid hierarchies or pre-specified relationships. That it’s built on those hierarchies and relationships is buried in the derived numbers
1 Like