Although I hadn’t tested this yet, I suspected as much. I knew I’d have to work on the actual footer. And several other responses already have fixes for it. I will update this evening.
Yes, I know about that and will fix it soon. It’s a fairly trivial fix. I probably should have delayed a day and fixed issues like this before announcing.
Interesting. I think I like the outline and background color on there – although that red would not be my choice – and I definitely like the inline-block rather than block mode for the list. In the end, I’m expecting to have an entirely different view here, some sort of graphic visualization that I haven’t come even close to working out yet.
One thing confuses me. It seems like you go to a lot of work to define type, and then never use it. Is there some automagical work that makes <$link ... /> respond to type? Or is this just copy-paste detritus? Or something else?
Hi Scott,
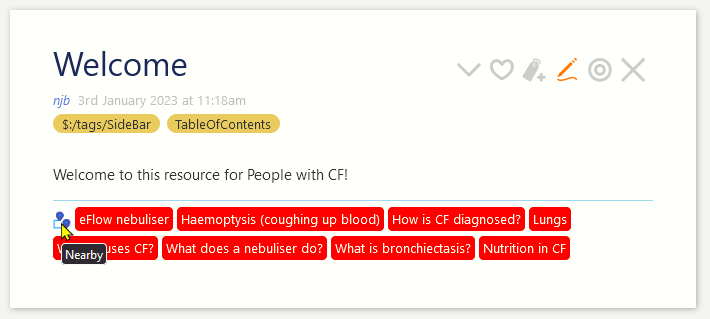
The Nearby Neighbors is a pretty neat idea. I was curious how hard it would be to do something like it in WikiText, based on your metric idea from the other thread, and came up with this:
Just tag a tiddler with this WikiText as $:/tags/ViewTemplate and you’ll get the list at the bottom of each tiddler. The score is only shown for debugging. If you wanted to only show the list when there actually are neighbors, just put everything inside the inner $set into a $list or $reveal which checks the neighbors list count.
It turned out to be fairly simple in the end. Some of the complexity is because I wanted to make it easier to amend and modify.
It does differ from @Scott_Sauyet’s original in two important ways:
Backlinks are not considered. I think calculating backlinks is quite resource intensive, especially for a large wiki with thousands of tiddlers. It can be added by adding a corresponding run to the linkedTiddlers filter expression.
It only regards the related field. I personally use this field to identify closely connected tiddlers in my wikis. The so connected tiddlers thus also get a very high metric. I haven’t thought about how to extend this to arbitrary / all fields, but this should be possible. I would exclude the list field, since that is often used for ordering and such and might result in extraneous high-ranking results (unless the associated metric is very low).
Curiously, I had to use the reduce operator in the neighborScore subfilter. That is purely to have access to a currentTiddler variable inside the sub-subfilter, which the subfilter or filter operators do not set (but sortsub does). I feel this is a bit of an inconsistency in the filter definitions. Also, I know of no straightforward way to check if some title is contained in a list that is stored in a variable – usually I would use the :intersection filter prefix, but I couldn’t get this to work in a subfilter definition. I’m sure @saqimtiaz has a solution or at least knows why that is.
This fills the sharedTagTiddlers list with one copy of the tiddler for each tag it shares, and then multiplies the number of occurences with the sharedTagWeight metric.
People have assured me that this is doable in wiki text, but this is the first demonstration of the possibilities. I’m not sure that it will extend in the direction I want to go, which is to use these initial values (or mine, based on the reciprocals of these numbers) as the initial values in a shortest-path algorithm to give give a truer metric of distances.
I will definitely be learning from (stealing from? ) your filters.
I don’t know what level of performance degradation I would accept to do it, but I would like to keep this like a real metric where dist(A, B) is always the same as dist(B, A). That’s the main reason I have dealt with backlinks here. It looks like there is already some caching going in in backlinks calculation, and that may help. I’m thinking that I will eventually add my own distance caching, but we’ll see.
Good call on the list field. I’ll exclude that one as well. For a general-purpose plugin, I think that all fields is a better approach than simply related, but I could certainly be convinced otherwise. One important point is that a wiki using many related fields already explicitly lists the information this plug-in is trying to extract implicitly; it probably simply wouldn’t need a plug-in like this.
I’m going to have to look at how this operator, um, operates. I want to relate it to JavaScript’s Array.prototype.reduce, but that may be leading me astray. And subfilters are still a mystery to me. I guess I’ll be checking that out.
One more relation that I missed (item 5 in Scott’s original list): Other tiddlers that are also tags of subordinate child tiddlers. Apart from manually filling the related field, these other tags of subordinate (journal) tiddlers indicate the closest* neighbors in my wikis. The more children have a shared other tag, the closer. The corresponding scores and lists are:
Here again, multiple occurences of a neighbor count towards its score.
*Since in my templates, the tags of a tiddler (parents) and the list of tiddlers that is tagged with the current one (children) are always visible, these need not be duplicated in the neighbors list.
Thanks for the POC @Scott_Sauyet and I continue to watch with a keen eye on your work. @Yaisog’s approach is similar to what I postulated earlier.
I am interested to see when the resulting list of nearby items differs from the relationships we already can leverage.
As you pointed out some wikis are repeat with relationships already and nearby is not as much use, but how would we describe wikis that will benefit from the nearby algorithm?
When listing such “relationships” can some metrics or methods be displayed to indicate how it came to be classified as such?
Yes. If and when I do the Dijkstra’s algorithm work, I’ll be very interested to see if it can be reasonably ported to wiki-text!
As with all tools built on a base framework, it cannot do anything that the framework cannot already do, pretty much by definition. The question is whether it makes doing so simpler, more ergonomic, or in some way better. Standing on the shoulders of giants comes to mind here.
That’s an interesting question I’ll have to ponder. I have a use-case of my own, which is what’s prompting this, but I haven’t really considered what the general use-case would be.
Well I was hoping to display the shortest path value in some form, as text size in a word art, as edge length in a graph, as a value in a fixed color gradient. But I would not expect to explain directly that this value came from a tag and a link, and that one came from a shared tag, or any such. My thought is that this whole process is to consolidate that information into a single easily digestible view.
Ok, understood, Keep going, I think you contribution will prove of great value.
I tried “Nearby Neighbours Plugin” on a copy of tiddlywiki.com which is already setup with a lot of relationships.
A small reflection; No need to respond, just make use of if helpful.
Many tiddlers may appear to be “only one step away” eg B is transcluded in this A, A is tagged with B.
I would be reluctant to choose one over the other as “closer”, and apply a weight.
I wonder if “first we eliminate the obvious” then “analyse the distance” to the not so obvious. The idea is identify all “directly connected” which the info tab and other tools already do, and exclude them from the nearby algorithm, returning “Nearby but you would not have known” items.
With this work in mind and a long held desire I am building a seperate set of tools for establishing a network of tiddlers, rather than a hierarchy like the TOC and “new hear” methods do.
In the near future I hope to have a set of test data that may prove useful for this project.
Is it possible to show the relationship? For example, is the node is a tagged tiddler, or the one has the shared tag?
Nice work! We may categorize this in the group of node explorers (e.g. TZK, Mehregan, Shiraz Node Explorer, Stroll, TiddlyResearch, kin filter, …).
Some suggestions (ignore if not related)
S1.
Like above request, I like to know the relationship! So, if you add an option to let me turn on/off to show what is the relation of displayed node to current tiddler!
A dream would be to see nearby plugin output in a graph like Tidgraph. May be nearby could replace the old Tidgraph.
S2.
It would be great if there were some config tiddlers, allow me to display only selected categories! For example, if I do not want to show the linked nodes, or when I like to ignore all nodes tagged with the current tiddler.
Thank you for all your efforts and new plugins and tools you added to TW ecosystem.
Yes, I didn’t know all of these when I went looking, but they are clearly related ideas. I had seen https://zettelkasten.sorenbjornstad.com/, which is wonderful, but far more than what I wanted for my usage. The same goes for your fantastic Node Explorer.
I told Tony I would think about this question a bit:
And I believe the following answers Tony and gives at least a partial answer to why my initial pass at this won’t likely show that information:
TiddlyWiki is used for all sorts of purposes. As an ultra-portable, easily editable, content storage and display system, its uses tend towards individuals or small groups who are both creators and consumers of that content. Its sheer adaptability makes it able to handle all sorts of complex requirements in a consistent manner.
But there is another style of usage, one where content creation and consumption are mostly separate. That’s where I’m focused right now. I’m working on a system where I’m the only – and soon to be one of only a few – people creating content. That content will be used by a few hundred others. Those others will likely know nothing at all of Tiddlywiki, and won’t even know its name unless they look at some fine print.
I’m using Tiddlywiki for this because of its microcontent focus, with the ability to reuse snippets across the pages, and to have various sorts of linkages between parts. I’m using it because I can make a simple link to the six specific pages this particular user really needs to read to solve a given problem. I’m using it because I can not only point to the URL, but also send the user an email with all the content packaged together. In short, I’m using it for many of the things that make TW great; but I’m not using it for any abilities of a user to add content. I’m not using it as a true wiki; that is reserved for just a few content-creators.
In this usage, I definitely do not want to show users that A is tagged B, that C transcludes D, that X links to Y. They should never care. But they might want to know that M is conceptually close to N. They might want to Q and R share some important connection. They would use this as an explorer, but a limited one. Here it would mostly be used for, “Well, I thought that page would answer the question I was asking, but it wasn’t quite it. What else is close by?”
While I and the other content creators could try to answer that with a related field or some such, that’s likely to be brittle and subject to all sorts of biases and oversights. It’s fairly rigid. The goal of Nearby is to gather that information organically from the structure of the wiki itself. It would be used to surf the documentation, following various trails through it marked by their own interest and not what I had in mind when creating it.
So the short answer to Tony’s question, is that this nearby algorithm will benefit wikis where the consumers will want to find their own ways through the content, not dependent on any particular schema or taxonomy the creators imposed. (This does not imply that it’s useless for personal wikis. The consumer and the creator could well be the same person.)
Yes, I’m hoping to create a graphical view, although likely not a tree. The list of links is a temporary placeholder. Although I’d seen Tidgraph a few years ago, I’d forgotten all about it. I will look to its implementation for inspiration.
Here’s where I see myself going with this:
Figure out a storage mechanism for a set of distance measurements across the whole wiki, perhaps a JSON Tiddler whose keys look like "Tiddler 1|Tiddler 2" and whose values are numbers.
Run Dijkstra’s algorithm or some other shortest path tool, using the distances I’m already creating as initial edge weights, to create a full set of distances. (Some may be infinite if this doesn’t connect the graph of tiddlers; I don’t think that’s a problem.)
Figure out a layout mechanism to display these in a graph, using the distances as guidance, centering a specific node (the current tiddler). If I try something like a force-directed graph, then perhaps make this an animation on expansion of the Nearby section. I imagine this will only involve the few dozen closest nodes, and not the whole wiki, although that might be a fun bonus of this technique.
Determine whether this is fast enough to run on a large wiki every time the user opens a tiddler or every time they expand a Nearby section. If it is (I’m doubtful), then proceed to the cleanup step.
If that’s too slow, figure out how to run steps 2 and 3 only occasionally. For my own purposes, this could be only at startup; but it might be possible to schedule this to run periodically on a Web Worker.
(Cleanup) Make this configurable in various ways. I’m thinking especially about the factors discussed in #5638 weighting the various kinds of connections and about the View provided to show the nearby neighbors.
I don’t know that I have the skills to do all of that, nor do I know if I’m willing to commit the time. But that’s how I would like to proceed. If I find myself unable to continue, I’ll probably at least do #6 to turn this from a POC to at least a beta level plugin.
Even discussing this here, I’m thinking about a potential alternative view, one that might appeal to those working on more personal notebook-style wikis: Lay out a graph of the whole wiki, and then, to show the neighborhood of one tiddler, pan and zoom that into focus. This might also include multiple edges between tiddlers with colors to indicate the type of connection. There’s a fair chance that this would be too busy, and that we’d have to find a way to remove or deemphasize edges for tiddlers not in the current view. This may be beyond my skills; I haven’t done much with graphics coding, but I could see this as a wonderful way to experience a complex wiki.

 ) your filters.
) your filters.