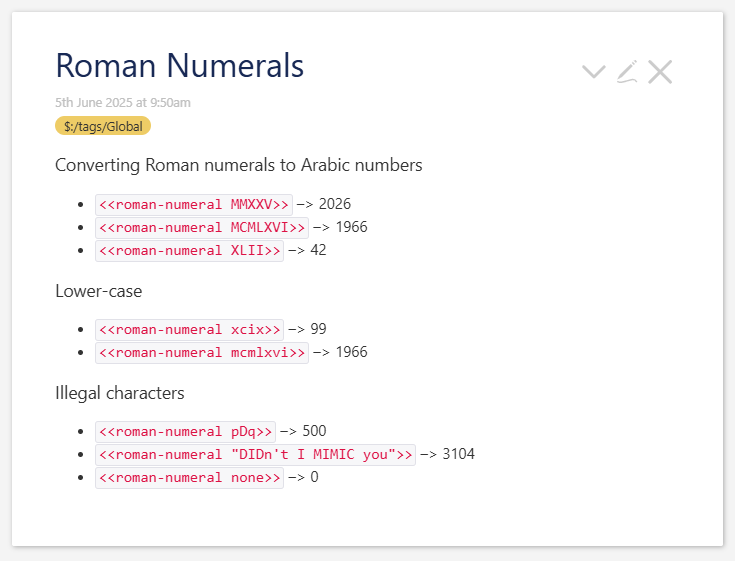
While this is light-hearted, and very much incomplete, I have created a Roman Numeral macro that is used in the above screenshot. It took the help of @EricShulman and @Mohammad over in a recent thread to put the finishing touches together.
Feel free to use it in its current state, but it is very limited:
-
It does not try to gracefully handle illegal input. In fact at the moment
<<roman-numeral PDQ>>throws aRecursive Transclusionerror. I think this is easily fixable. But we’d have to decide if that should be0, because, well, it’s not well-formed or50for theD. -
Upper-case only. Again, this will be easy to fix.
-
One direction only. There’s no equivalent
<<to-roman-numeral 1966>>→MCMLXVI. Once I have this one complete, I’ll probably try that. I think with what I’ve learned from here, it should be straightforward. -
For some reason when I try to call it with transclusion syntax using
<<currentTiddler>>it throws anotherRecursive Transclusionerror. I can prevent this easily by introducing another variable. That is, this fails with the error:<$list filter="MMXXV MCMLXVI XLII"> <li><<input>> --> <$transclude $variable="roman-numeral" rn=<<currentTiddler>> /></li> </$list>But this works fine:
<$list filter="MMXXV MCMLXVI XLII" variable="input"> <li><<input>> --> <$transclude $variable="roman-numeral" rn=<<input>> /></li> </$list>I have no idea what causes that. Any suggestions are welcome.
-
It uses
filter→firstas a poor man’s version offind, in the assignment ofr. That feels wasteful, and I would love to know about a truefindoperation that short-circuits when it finds a result. I suppose I could write a simple recursive version similar to myindexof, but I would love to know that there’s something already built-in. -
It is built on matching indices in two separate arrays:
rs: M CM D CD C XC L XL X IX V IV I vs: 1000 900 500 400 100 90 50 40 10 9 5 4 1I find that a fragile concept. I would much rather work with something like this:
ps: [["M",1000],["CM",900],["D",500],["CD",400],["C",100],["XC",90],["L",50],["XL",40],["X",10],["IX",9],["V",5],["IV",4],["I",1]]I did have a version almost working with this input:
cs: {"M":1000,"CM":900,"D":500,"CD":400,"C":100,"XC":90,"L":50,"XL":40,"X":10,"IX":9,"V":5,"IV":4,"I":1}But, although modern JS specifies that JS objects be traversed in the order of property definition, something in TW is traversing in alphabetic key order; perhaps its at the creation of an object from the JSON text. So when it should be finding
CMit was findingC. That was disappointing, and it sent me down this two-lists implementation. I still like the JSON array idea better though. So I will probably go back to that at some point. Doing so would also let me eliminate myindexofhelper, which would clean things up significantly. But I don’t get along particularly well with TW’s JSON operators, and I failed on my first two attempts. Maybe I can fix that now that the whole thing is actually working.
But it works! While I say this is just for fun, I will probably actually need it for a current project, where I will need to sort on roman numerals. That’s fine for I - VIII, which sort the same way viewed as numbers and as alphabetic strings. But it breaks down when you hit IX.
So I will try to harden it.
But I would love advice for improvement. My implementation feels overwrought. It is based on this (relatively simple) JS implementation:
const r2a = ((vals = [
['M', 1000], ['CM', 900], ['D', 500], ['CD', 400], ['C', 100], ['XC', 90],
['L', 50], ['XL', 40], ['X', 10], ['IX', 9], ['V', 5], ['IV', 4], ['I', 1], ['']
]) => (s, rn = s.toUpperCase(), [r, v] = vals.find(([s]) => rn.startsWith(s))) =>
rn.length == 0
? 0
: v
? v + r2a(rn.slice(r.length))
: r2a('', rn.slice(1))
)()
which also handles the uppercase issue and the illegal input one (returning 50 for PDQ.)
But I had to veer hard from that when I had problems making the JSON operators work for that style input, meaning I had to create an indexof operator so I could match the two inputs. Is there something built in that does this? My version seems heavyweight.
Here’s what it looks like:
title: Roman Numerals
tags: $:/tags/Global
rs: M CM D CD C XC L XL X IX V IV I
vs: 1000 900 500 400 100 90 50 40 10 9 5 4 1
\procedure indexof(x, xs, idx: 1)
\whitespace trim
<% if [enlist<xs>count[]compare:number:lt<idx>] %>
-1
<% elseif [enlist<xs>nth<idx>match<x>] %>
<<idx>>
<% else %>
<$transclude $variable="indexof" $mode="block" x=<<x>> xs=<<xs>> idx={{{ [<idx>add[1]] }}} />
<% endif %>
\end
\procedure roman-numeral(rn)
\whitespace trim
<% if [<rn>trim[]match[]] %>
0
<% else %>
<$let
r={{{ [enlist{!!rs}]indexes :filter[<rn>prefix<currentTiddler>] +[first[]] }}}
next={{{ [<rn>removeprefix<r>] }}}
>
<$wikify name="index" text="<$transclude $variable='indexof' x=<<r>> xs={{!!rs}} />">
<$let nbr={{{ [enlist{!!vs}nth<index>] }}}>
<$wikify name="balance" text="<$transclude $variable='roman-numeral' rn=<<next>> />" >
<$let total = {{{ [<nbr>add<balance>] }}} >
<<total>>
</$let>
</$wikify>
</$let>
</$wikify>
</$let>
<% endif %>
\end
Suggestions for improvements would quite welcome. You can play with it using this:
Roman Numerals.json (1.4 KB)