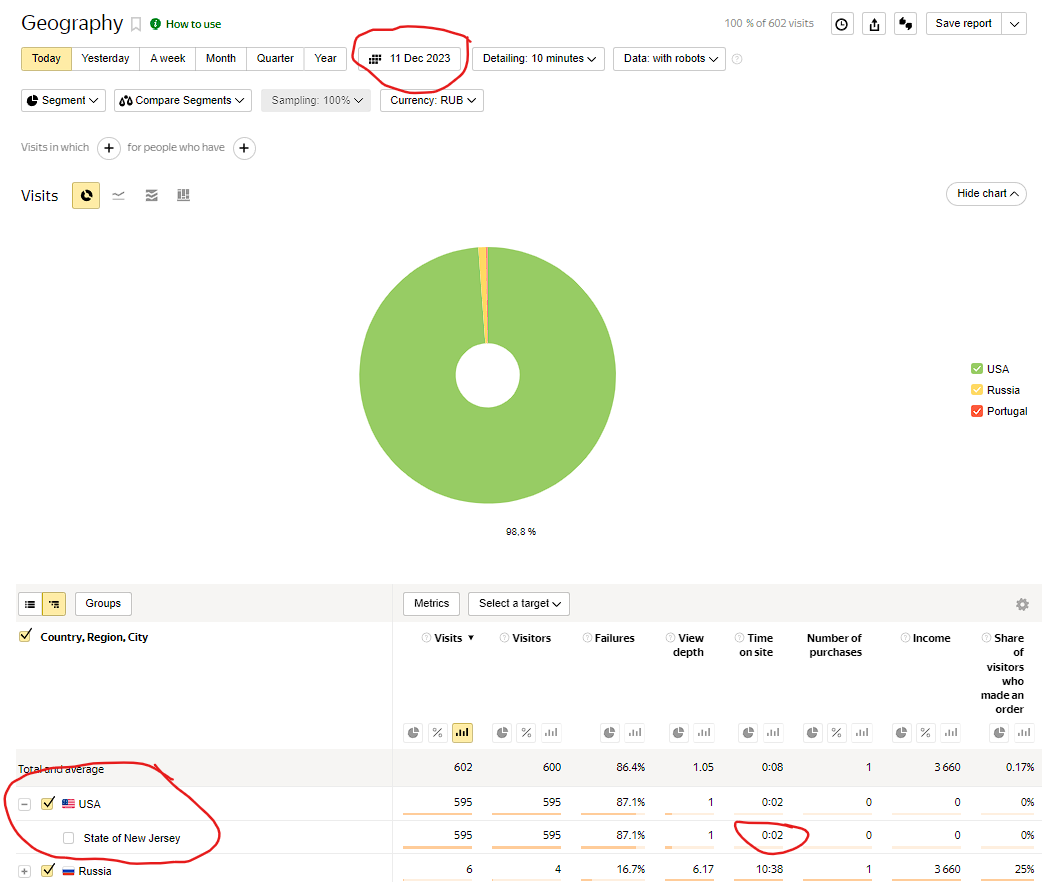
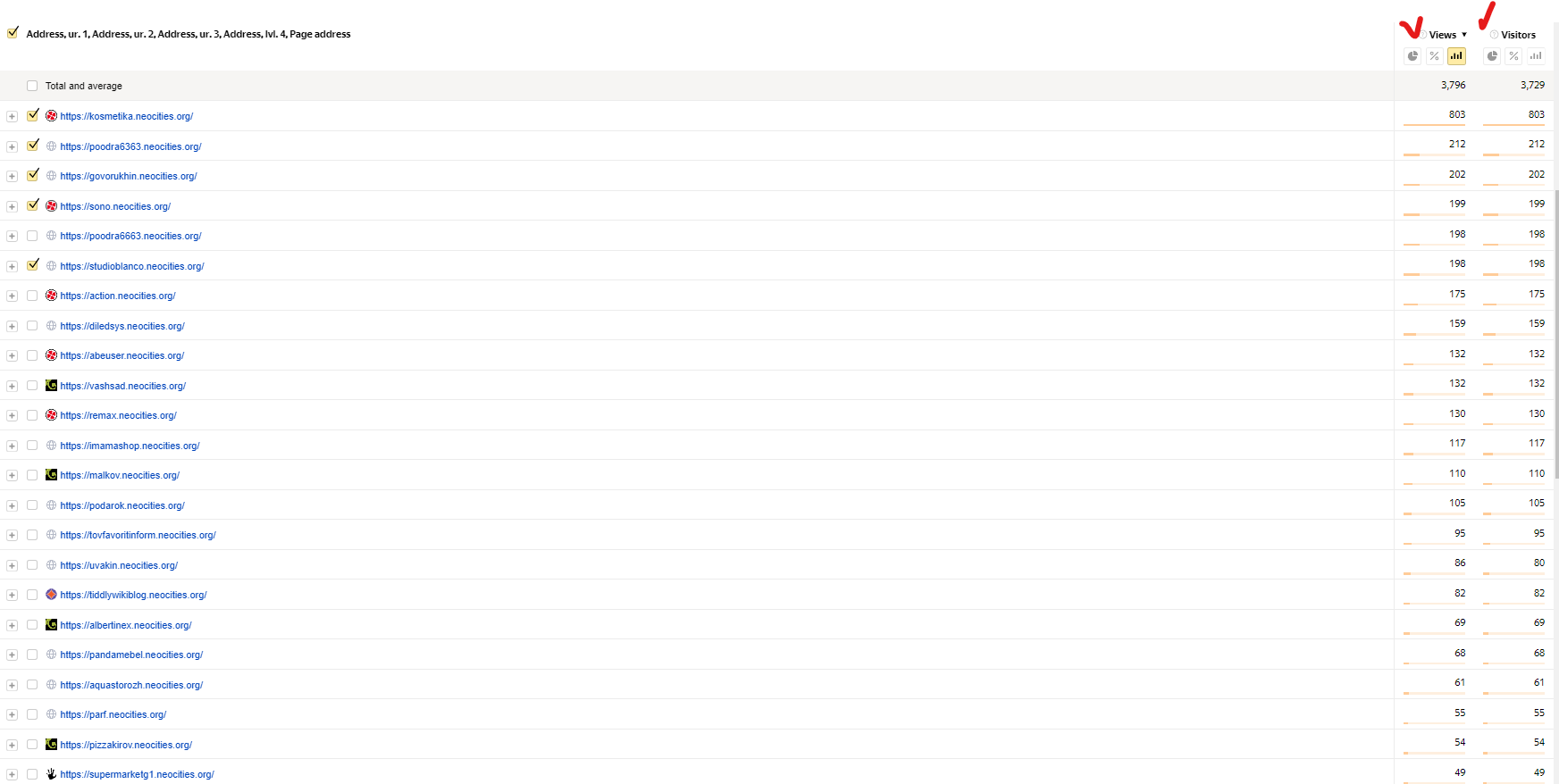
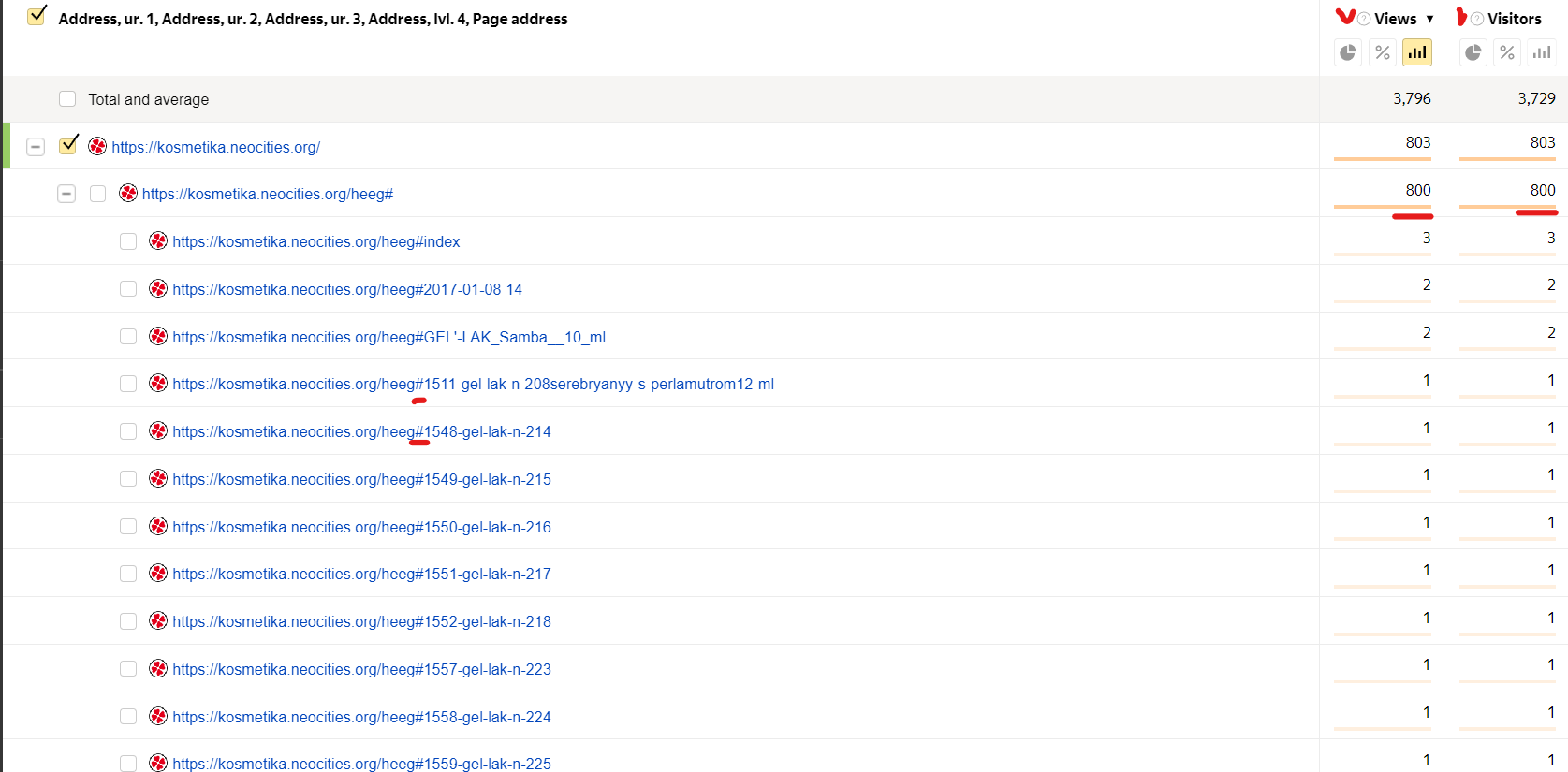
I run a website with a large number of visitors and I use bespoke hand written analytics which I can adapt to suit a particular emergency or attack, I always kept a very careful eye on bots.
I mean this nicely but I think it is very naive to think that bots will not visit a particular page on your site, you only need one person to reveal the URL of a page and a bot may end up trying to access it.
Expect bots to try to visit every page that your server offers - the only choice you have is what you serve an un-authorised user if they try to visit a page you consider private - do you serve them the real content or an “Access denied” page instead.
There was a time in my experience when you could expect a page to remain “quiet” simply because only a few people knew about it and you did not link to it anywhere but I think with social media, Google, the Chrome browser your ‘privacy’ becomes very leaky very quickly as soon as you tell one other person about your page.
You may have been lulled into a false sense of security because a particular page was quiet for a long time but again I think bots can ignore a page for ages and then all of a sudden they are all over it.
You may also be experiencing spam/scam bots which are often naively written and will continue to try and load the same page multiple times, these are the sort of bots which try and inject SQL and so on and probe for vulnerabilities - I often look at the injected code they are trying to use and it’s often hopelessly out of date and assumes people are still using vulnerable versions of mySQL which makes me think that there are sufficient numbers of unprotected devices out there to ensure that old viruses don’t die out.
They are like flies - nothing for months and then all of a sudden you experience what looks like a denial of service attack but actually on examination it looks more and more like a very naively written virus on a remote device somewhere that simply does not have the imagination or knowledge to break out of cyclic loop of links, it’s literally banging its head on the door repeatedly. You would think it would get bored and move on but no it just keeps on knocking.
I learnt a lot from writing and adapting my own analytics code.