Hi all,
This is a sharing of (yet) another way to import local file links ! This one works by copying the screen content from a Web browser’s directory listing screen into Tiddlywiki.
Desktop browser can browse files in local file directories using a URL such as “file:///C:/Downloads/”. The screen content of the browser’s directory listing screen can be copied into Tiddlywiki by selecting the entire screen or some file entries, copy (’‘with Ctrl-C, not drag-and-drop which will copy the files themselves instead of the screen content’’), and paste into an empty region in Tiddlywiki. Tiddlywiki will import the content as “text/html” and “text/plain” files which contain the respective html and text contents of the browser’s web page.
Although the imported “text/html” in TW looks identical to the browser directory screen and the file links even work when you click on it, both file formats are not immediately usable for manipulation in TW. The file entries info needs to be extracted to be useful in TW.
Extracting Chrome’s directory listing from “text/plain” file
The sample wikitext below extracts Chrome-formatted directory list info from an imported “Untitled text/plain 123” tiddler into “filenameList” and “fullpathList” variables:
\function slash.prefix.for.windows() [all[]] :map[<currentTiddler>!prefix[/]then[/]else[]addsuffix<currentTiddler>]
\function line.feed() [charcode[10]]
<$let rawDirList ={{{[[Untitled text/plain 123]get[text]splitregexp[\r\n]format:titlelist[]join[ ]]}}}
filepath ={{{[enlist<rawDirList>first[]search-replace[Index of ],[]search-replace:g[\],[/]slash.prefix.for.windows[]]}}}
filenameList={{{[enlist<rawDirList>butfirst[3]] :map[splitregexp[\t]first[]format:titlelist[]] +[join[ ]]}}}
fullpathList={{{[enlist<filenameList>addprefix<filepath>format:titlelist[]] +[join[ ]]}}}
>
The directory pathname on browser’s directory screen is shown only at the top of the screen so you need to copy the screen content from the top down for this to work.
Extracting Chrome’s directory listing from “text/html” file
The sample wikitext below extracts Chrome-formatted directory list info from an imported “Untitled text/html 34” tiddler:
\procedure pattern_chromeTblHeader() <tbody id="tbody">
\procedure pattern_chromeRowSeparator() </td></tr>
\procedure pattern_chromeTableRow() ^.*href="([^"]+?)([^"/]*)".*data-value="([0-9]+)".*data-value="([0-9]+)".*$
\function line.feed() [charcode[10]]
\procedure dir_contents() $1┋$2┋$3┋$4
{{{[[Untitled text/html 34]get[text]splitregexp<pattern_chromeTblHeader>butfirst[]splitregexp<pattern_chromeRowSeparator>butlast[]search-replace:g:regexp<pattern_chromeTableRow>,<dir_contents>format:titlelist[]join<line.feed>]}}}
into this intermediate format I’m using for storing multiple pieces of file info:
( Path ┋Filename┋file size ┋date modified )
/C:/Downloads/┋Filename1.pdf┋2847575┋1685023056
/C:/Downloads/┋Filename2.png┋1861073┋1686443160
You can use your own format, such as “$1$2” for full pathname, or “[ext[$2|$1$2]”, by changing the line \procedure dir_contents() $1┋$2┋$3┋$4 accordingly.
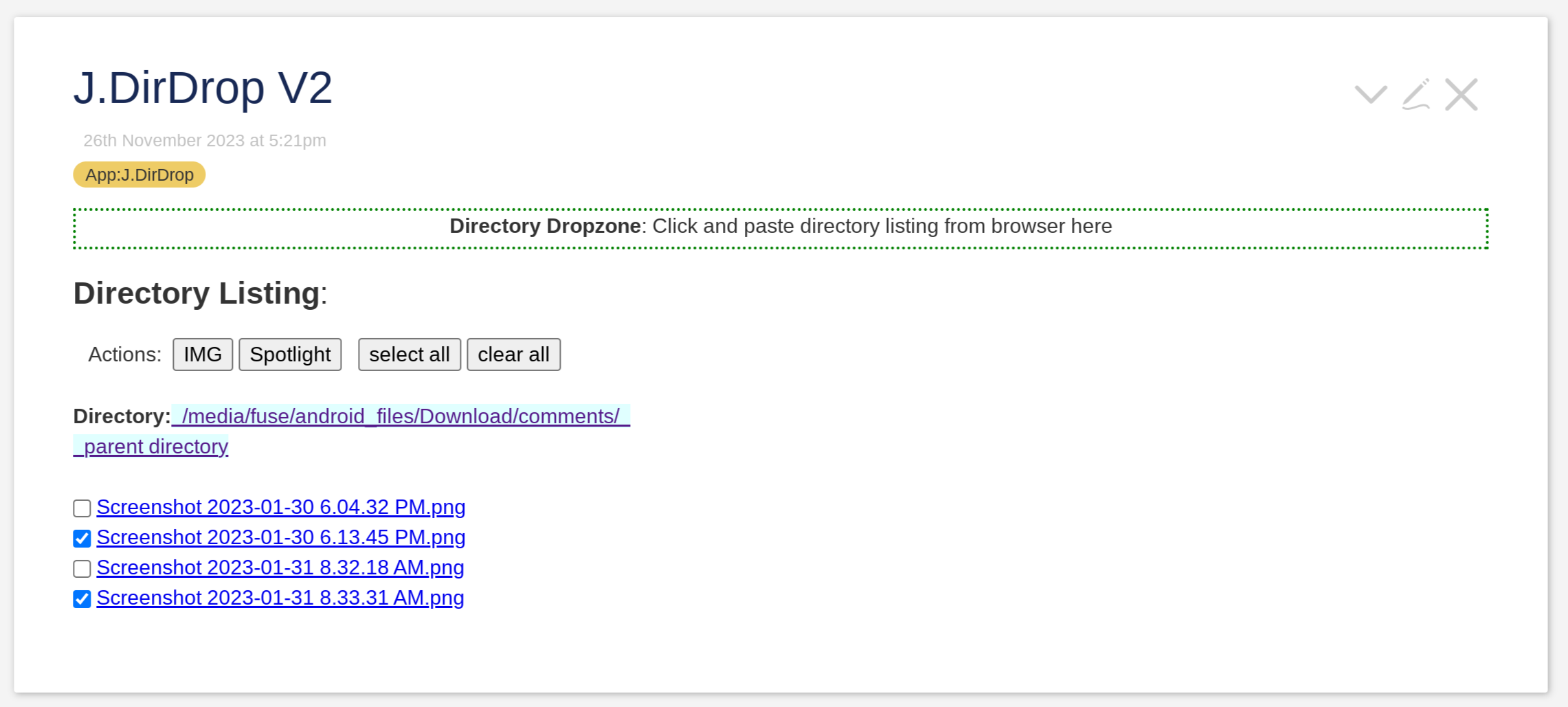
Sample app to import Chrome browser’s directory listing
Attached is an example app J.DirDrop.json (9.9 KB)
that uses the wikitext above for “text/html” to import Chrome browser directory listing. This works only on Chrome for now because I didn’t have time to do one for Firefox browser. I find this method to be quite efficient using mouse and keyboard for importing a single directory of file links. You can customise it to do your own processing on imported file links. I didn’t do a thorough test so there might be edge cases where the importing didn’t work. Usual caveats apply regarding using it with care and saving your files.
Have fun !