
What’s the end goal?
I am trying to add a parser module for docx files. If I fix the problem then I will open a PR in the official repository.
What have I done so far?
(function () {
/*jslint node: true, browser: true */
/*global $tw: false */
"use strict";
const BinaryParser = require("./binaryparser");
var DocxParser = function (type, text, options) {
var element_uri = {
type: "element",
tag: "iframe",
attributes: {
src: {
type: "string",
value: `https://view.officeapps.live.com/op/embed.aspx?src=${options._canonical_uri}`,
},
loading: { type: "string", value: "lazy" },
style: {
type: "string",
value: "border:0; width: 100%; object-fit: contain",
},
},
},
src;
this.tree = options._canonical_uri ? [element_uri] : [];
};
exports[
"application/vnd.openxmlformats-officedocument.wordprocessingml.document"
] = DocxParser;
})();
This parser works fine if following conditions are met
- A tiddler type is
application/vnd.openxmlformats-officedocument.wordprocessingml.document - Tiddler has
_canonical_urifield set
In this case, the MS Office live viewer shows the document in an iframe.
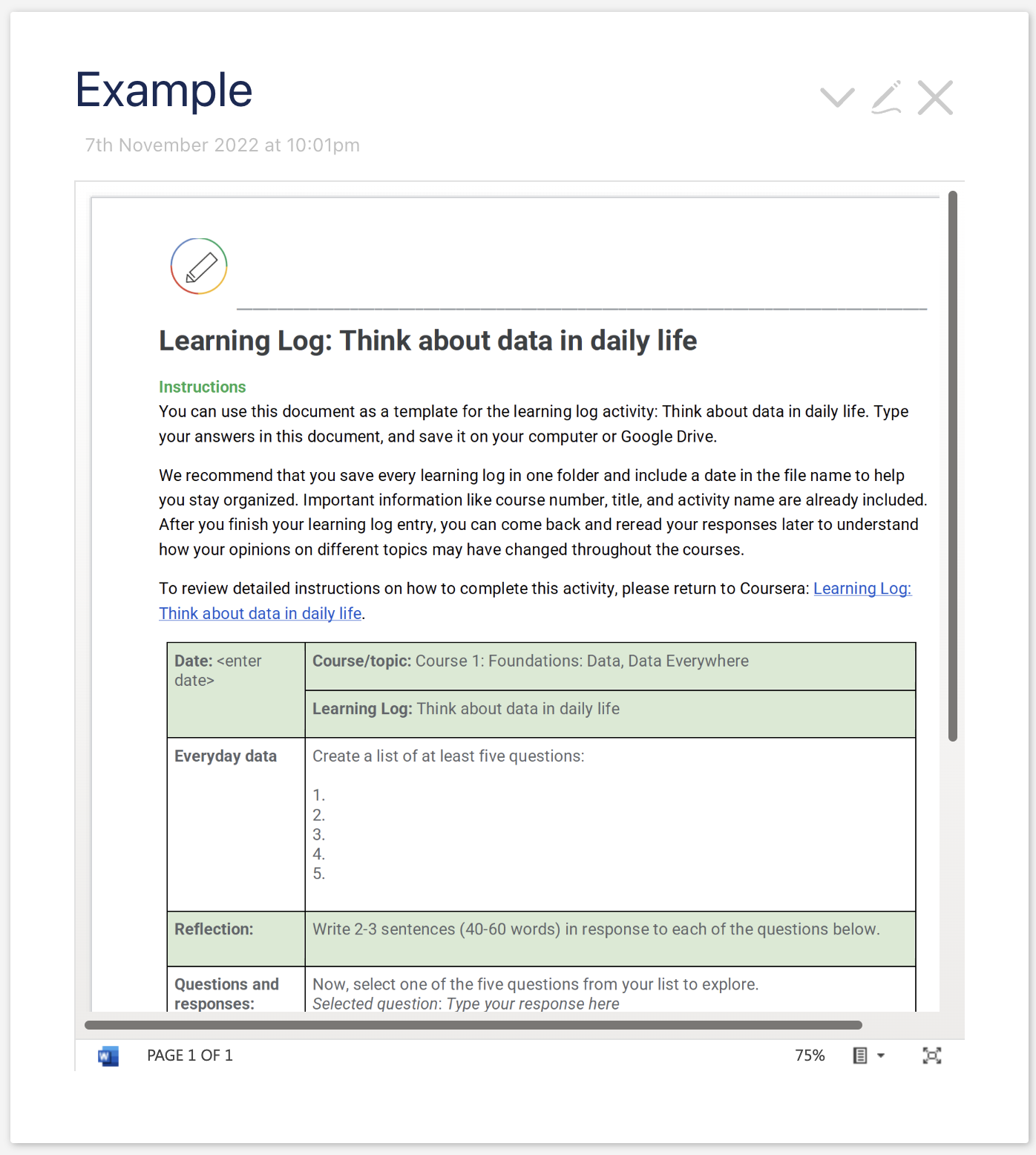
What’s the challenge?
If a user drops a docx file to TW, then it gets added as a binary data. In that case the TiddlyWIki SHOULD SHOW binary data warning.
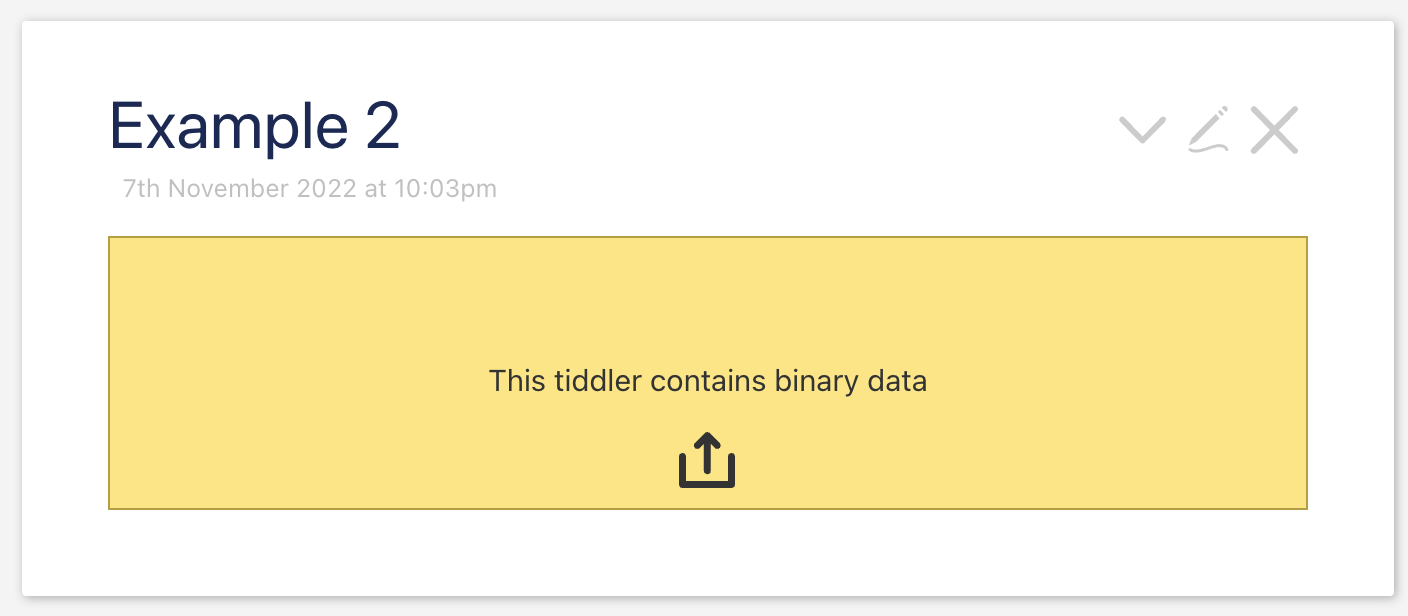
How do I tell my parser to use BinaryParser if options.__canonical_uri field is not set?
I suspect, I need to do something like this
this.tree = options._canonical_uri ? [element_uri] : [BinaryParser.element];
But I am not sure about the correct syntax.
 .
.