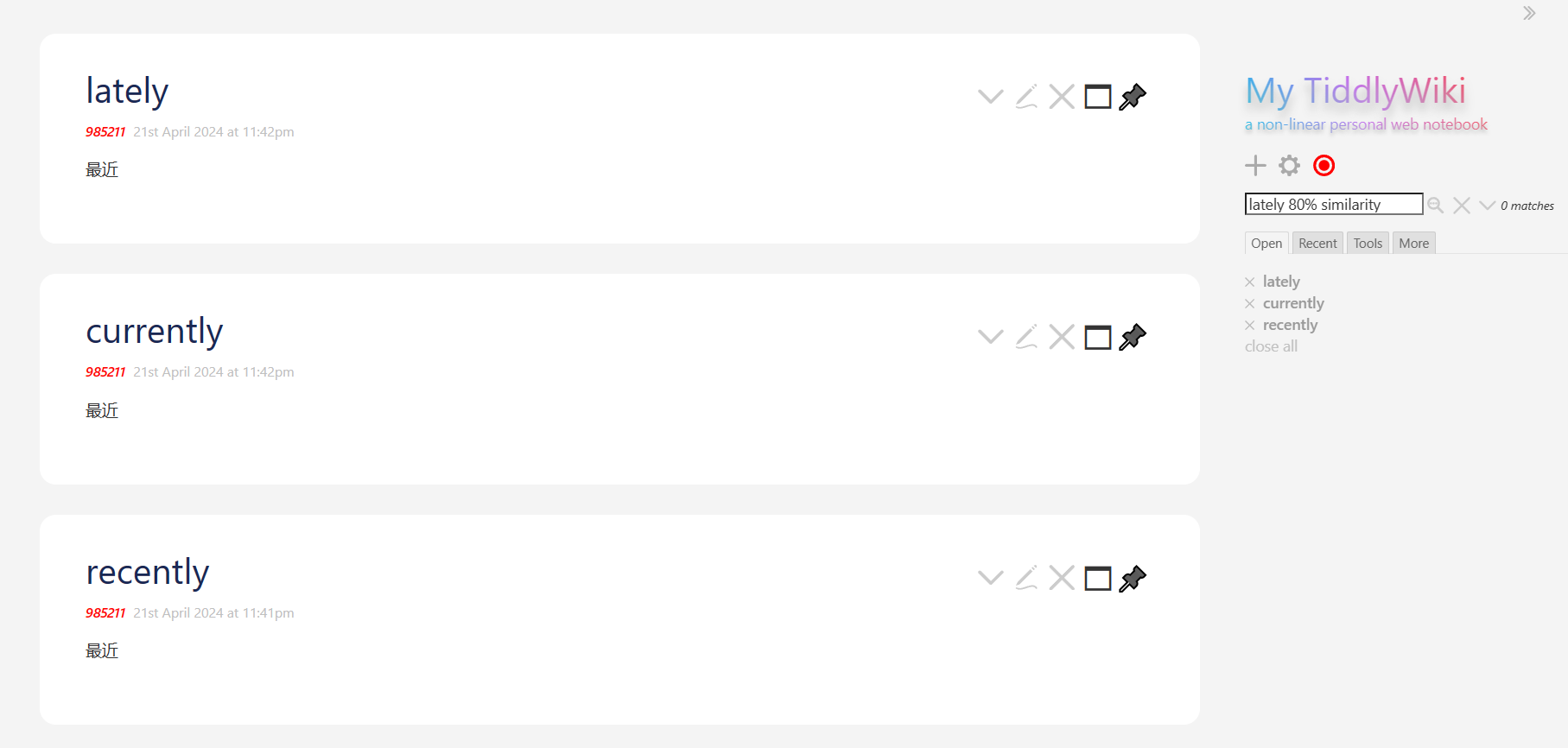
I think it is unrealistic that one search implementation will suit all users, once your needs start to become very specific I think it’s often a lot easier to develop your own search plugin or not even a plugin but simply a single tiddler that you can visit to perform searches that work the way you want to work.
I include the json for a single tiddler that I use, the original code was from another TW user and I adapted it over time to suit my needs.
Three text boxes - two are for literal so that I expect two or more words to appear exactly as specified “word1[space]word2” and then one “not literal” text box for space separated words that can appear in any order, there is no need to have more than one box for the non-literal search.
In addition option to specify tags in the search, in my case the logic is Tag1 AND Tag2 but you could adapt to be Tag1 OR Tag2 etc.
The output of this search is simply a list of tiddlers that appears at the end of the tiddler.
I also use the regular search as well - both have their advantages.
I recommend anyone who has the technical knowledge and needs specific or specialist searches to invest time in their own search code - for me at least it has paid off many times.
Multiple Tag And Word Search1.json (2.1 KB)
You could start by figuring out a way to store your own synonym data and then create code similar to the above that will automatically include other members of the synonym set when you select one. I think that the 80% bit will be very difficult because then you need to store a number that is a relationship between each word in the synonym set and every other member of the synonym set and that will end up with a lot of data and unless someone has created data sets for this you would likely have to create the data based on your own judgement.
If no existing data exists for this purpose then if this was my project I would be interested in creating a scheme where I manually enter synonym data sets as and when I required them so that over time the data set would suit my needs and most common searches and not include a whole lot of data that would never be used.
People tend to have a vocabulary that is a mere fraction of the number of words in the language being used - this is true at least for latin and germanic languages - I think I recall reading once that most people have a working vocabulary of 10,000 to 20,000* words but the set of words we might use in a search or that have sensible synonyms might hopefully be smaller than that.
- Oxford English dictionary (OED) online version has 500,000 words suggesting English speakers might be using something less than 4% of the language.