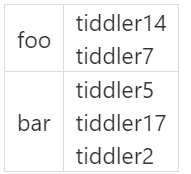
Scenario: Several tiddlers have a myfield field. Most tiddlers have uniquemyfield values, but a few have identical and arbitrary values like myfield: foo, some have myfield: bar, etc.
How can I make a table that lists only those field values that appear in multiple tiddlers and, next to it, all tiddlers that have this field value, like so:
The only approach I can come up is problemtic because, for once, duplicate titles must be kept in the filters and I must also count them to insure they are indeed duplicates. But maybe this approach is off to begin with…?
I’ve just written something similiar for my own use. Instead of counting each unique value, it uses the difference between the list of values including duplicates, and the deduplicated list to extract the duplicates:
This is the version I used, placed in a procedure. I found it useful immediately in all my other TWs and thought it might be worth flogging a dead thread :