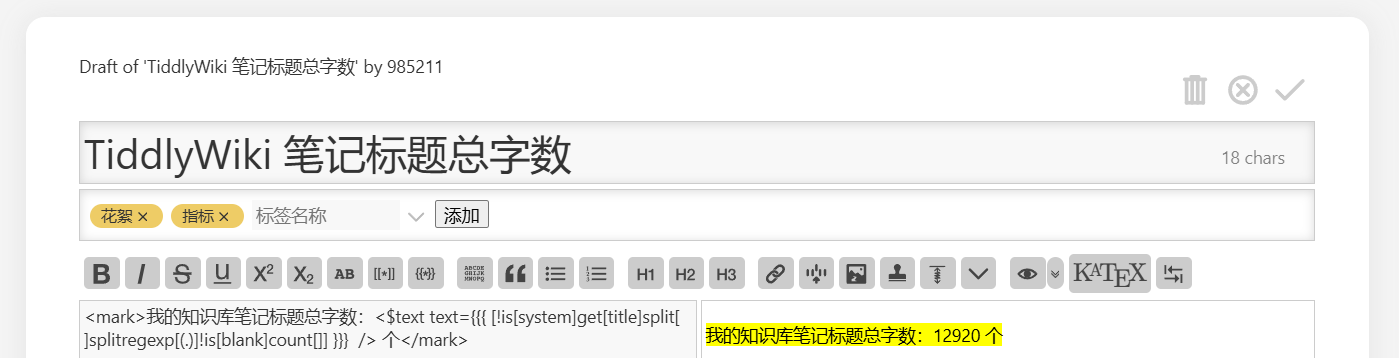
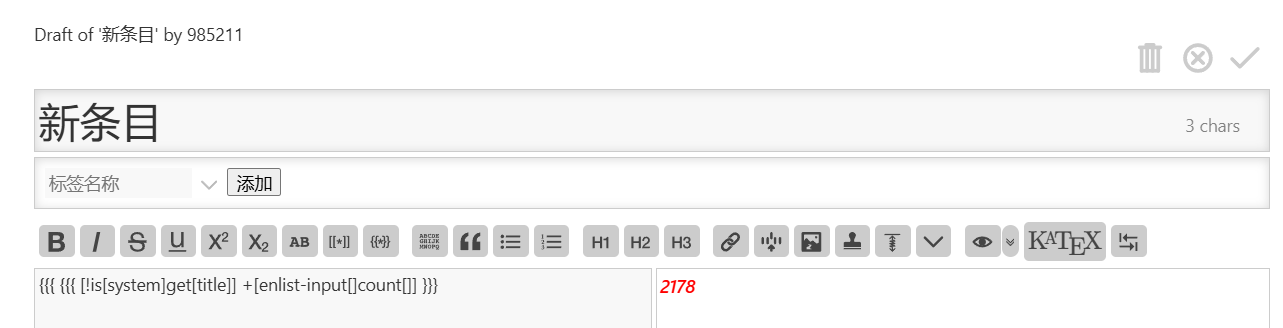
I’m afraid there may be some language barriers here.
When you say “notes”, do you mean “tiddlers”? Or is this some subset of the tiddlers, perhaps those tagged “Note”
When you say “headings” do you mean the “title” field? Or are you talking about the (possibly generated) H1, H2, … H7 tags, which might come from wikitext such as !! Heading Level Two, or !!!! Heading Level Four?
Finally, I know that breaking Chinese text into words is more complex than in English or other Latin alphabet languages. So I would expect that splitting on spaces is not enough, but it’s the only technique I know. So would this be acceptable?:
const text = "你说到这是一个测试"
text.split('')
//=> ["你", "说", "到", "这", "是", "一", "个", "测", "试"] // giving nine "words"
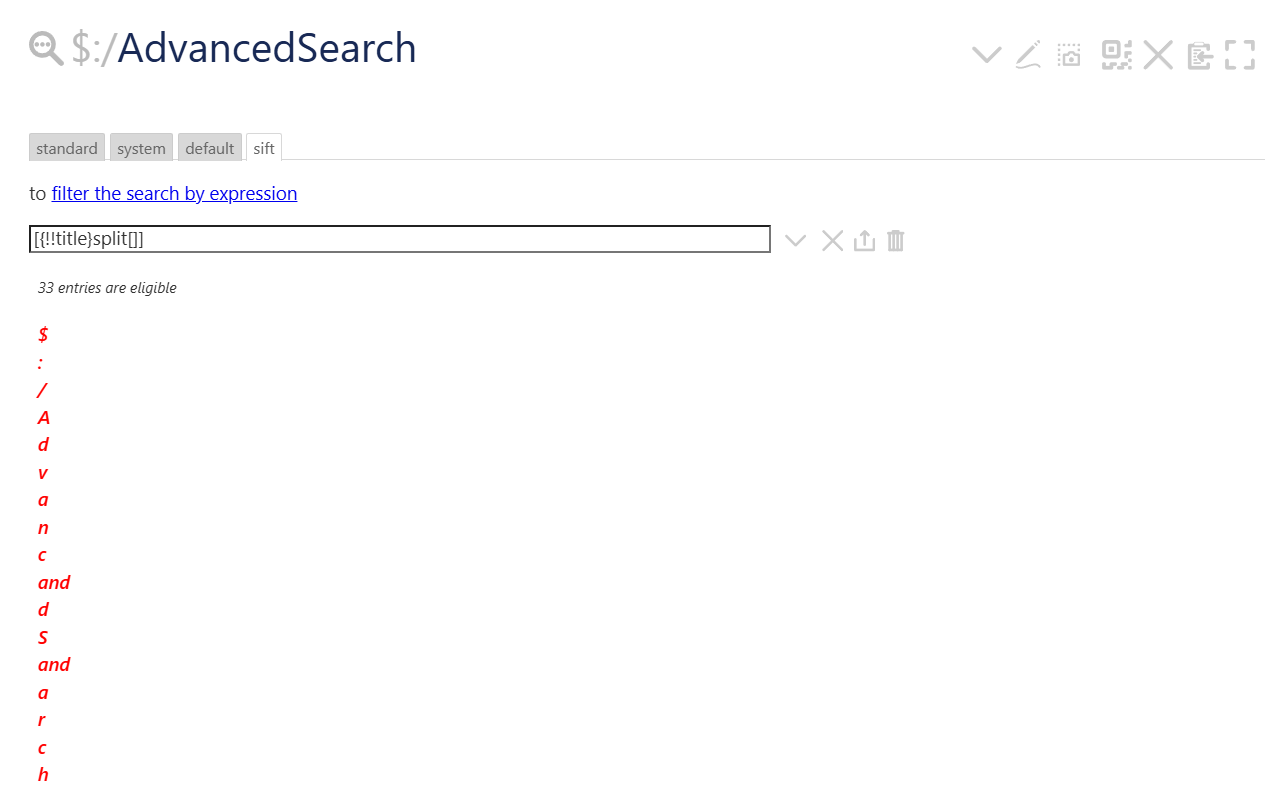
If so, that can be done with the split operator, using various kinds of input:
[{!!title}split[]]
// or
[<my-text>split[]]
// or
[[你说到这是一个测试]split[]]