Hi, With this description and your wiki, I have no idea, what this SSSPC code should do. It would also be nice, to spell out SSSPC here in the post. to make things clearer.
The program has been advertised once before. At the time it looked like no one could understand it.
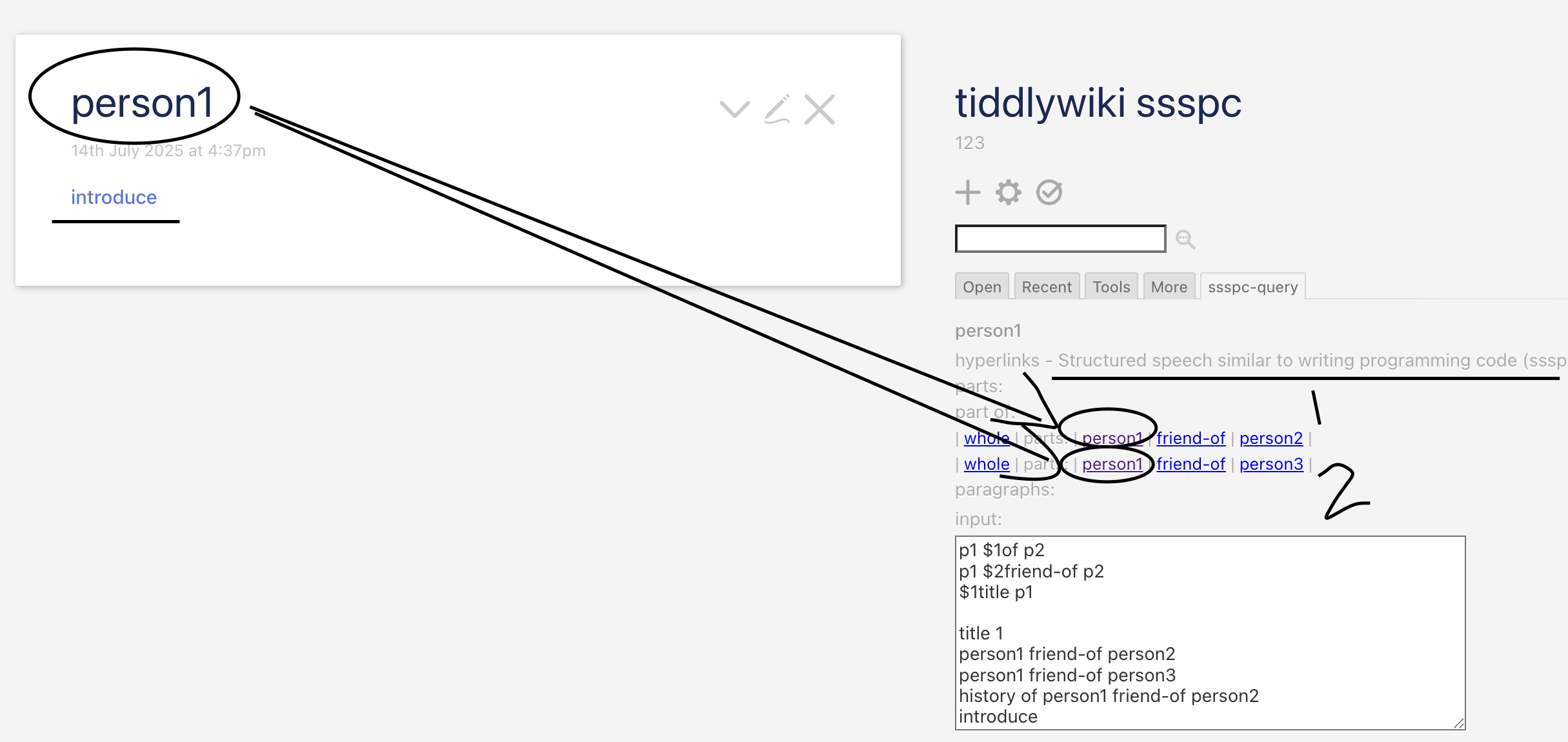
Look in the screenshot, the right side shows the relevant tiddlers for the open tiddlers, like 1 and 2.
See the underlined part for the meaning of the abbreviations
For more information see Introduce
I’ve made my tutorial documentation as simple and easy to understand as possible. I’ve redone it three times. If people can’t understand it, then they have to give up.
That’s more likely a sign that the documentation you wrote is not appropriate for the audience than a sign that the audience is incapable of understanding. There are many smart people here.
I got as far last time and again this time as recognizing that you were creating a mechanism to associate arbitrary relationship predicates about certain subjects (Person 1 is a friend of Person 2, for instance.) I’ve done a little logic and relational programming, playing around with Prolog-like languages and miniKanrens. So I recognize that much of it. But you have not made it clear to me why I should care.
I see that your code can make it so that we use such relationships to add sidebar links to related subjects. That’s fine. We have many other techniques for this, though. Is the innovation here that we can do this without hard-coding the relationship info into our wiki structure?
You compare this to the tree macro, but I don’t really see the relationship. The tree macro represents a hierarchical data-set.. Yours represents a set of non-hierarchical relationships. There’s not much overlap. Or am I missing the point?
It feels more in keeping with the spirit of TW to develop a TW implementation of RDF, and to use simple queries to detail all relationships a tiddler has. Can you explain the advantage of your framework over that?
Similar to the definition of the four arithmetic operations.
the “$” in the sentence indicates that this is a define of operator .
$ means this is a operator name.
The number after $ is the priority.
So..
p1 $1of p2
p1 is set as of p2?
The operator is defined as of and has a priority of 1?
Is of just text or is it code, does of DO something?
p1 $2friend-of p2
p1 is defined as a friend of p2?
The operator is defined as friend-of with a priority of 2. This is a lower priority than 1 and will be executed second?
$1title p1
Creates operater title with priority 1?
Title is a reserved command which creates a tiddler.
title 1
Title operation called.
Tiddler with the title p1 created.
It is related to paragraphs and is the title of a paragraph.
Each line is an end.
You can probably figure out what’s going on by reading these two lines in terms of grammar. I also think these two sentences can make it clear. For more related grammar, please see below.
I’m not good at writing documents, so people can’t understand what I write.
SSSPC looks more like natural language.
SSSPC can express nested structures, and natural language does have nested structures.
You input a sentence, which can be parsed into several parts. Then you click on one of the parts, and it can find all the sentences related to that part.
Can I suggest that you create a miniature real-world wiki that uses your tool to describe certain relationships? That would show us how it works. I mean something like I created and described in a recent thread. Can you demonstrate how such relationship information would appear in the wiki? Would you extract it from the text field of a given tiddler? Is it in another field on such tiddlers? Is it in a single configuration tiddler? Something else?
Or, am I missing the point? Is this a tool that you’re working on, and only demonstrating, using TW as a documentation engine, but which is not itself meant to enhance TW?
I can see those. But I think I would need more comprehensive examples to see how this might affect me when developing a wiki design. Again, an extended example would be helpful.
Ok, I can certainly see that this is true syntactically. Could you suggest some real-world examples involving more than three components?
To start don’t assume any knowledge such as in your first post you seem to be saying we all know what SSSPC is, at least expand the acronyms. Do it in your post, not only out there in things you link to, no one (or few) will research the details if they dont know what you are talking about in the first place.
Similarly simplifying what you say using jargon or symbolic representation only makes it easy for people “just like you” to read, maybe only you, so you need to expand what you say to have its meaning self contained, not dependant on arbitary knowledge.
My reading habit is to skim or guess if I don’t understand. It doesn’t take into account that there are people who don’t skim any words.
Except for the acronym. Any other suggestions for this document? I’ve had two people test this document. The terminology has been removed. But at the moment the AI still can’t get the exercises exactly right.
This demo is already a real world example. And it’s also an example of your reply. I’ve read your REPLY and replied to that topic. SSSPC currently has no reasoning capabilities.The way SSSPC enters a line of text would be faster than adding a field, but is even less TiddlyWiki. SSSPC is only concerned with retrieving information, not typesetting the output, or the text field, it’s a single tiddler configuration file.
SSSPC uses TW as a document engine. Where it enhances TW’s capabilities is in the acquisition of “related reading” capabilities.
SSSPC is only for those who want the “related reading” feature, not for others.
nested structure: (history of (person1 friend-of person2))
My impression so far is that you’re not interested in the form of natural language, nested structures, more structures than triples, related reading, text input, retrieving document libraries from every word in the title, and these features. Maybe what I’m developing is supposed to be a niche software.
I think we have very different ideas, then, about real-world demos. When I look at your example, I don’t know what the wiki is built for. The example I linked to above is a wiki showing a partial genealogy of a famous American family. It directly encodes only the Parent/Child relationship, but derives others like Sibling, and implicitly (and only for its time Marriage) relationships. The idea was to demonstrate that I don’t have to have children, parents, or similar fields in my main tiddlers, but can use external relationship ones.
Perhaps I simply don’t have the imagination necessary, but I haven’t found an example of where I would want to use your (very interesting!) tool. I was hoping you could supply such motivation. Feel free to adapt my wiki to your techniques. Perhaps it would involve such predicates as “John Quincy Adams served as U.S. President from 1825 to 1829”?
I created a plugin for a list of neighboring tiddlers. It’s still in an alpha stage, and I don’t know that I will ever get back to it. But it’s almost the polar opposite of your approach; the goal was to entirely derive the idea of nearness from the wiki structure (links, tags, fields, transclusions, etc.) Yours seems to be to explicitly declare the relationships – with an interesting natural language-like mechanism.
If I want that, I would probably want it in the footer of a tiddler, not in the sidebar. Will the mechanism allow me to do that?
I’m not sure. I’m fascinated by the concept, but don’t really understand well enough to know if it’s something I would want. That’s why I’m trying to tease things out here. Perhaps it is something I would love to have. Perhaps not. I just can’t tell yet.
Your example is an example of nesting. Using ssspc you can answer who are the presidents of the United States.
An example of superiority over RDF. “Tom’s sister is Jerry’s sister’s teacher”.RDF can only express teacher relationships. And ssspc can also answer the question of who’s sister is involved inside the document library. Just click instead of re-searching.
The ssspc just discovers information from the title.
It doesn’t just declare relationships. Rather, it breaks down each word of the title with a nested structure.
You can. I added this section to the website.
You can say what part you’re interested in, then name your specific example, and then I’ll say how ssspc works.
The character relationship example, I think that’s what I demonstrated in my demo. As I also said, ssspc has no reasoning function, only the simple ability to retrieve interrelationships. I don’t have a genealogy requirement, so I don’t have relevant more examples here.
The table part of the previous reply is an example of what I use on a daily basis.
If you use ssspc to parse the title, there will be some limitations on the title, can not realize all natural language, but a subset of natural language. Just like tree macro, it doesn’t look like pure natural language. But it will be more natural than tree macro, for example, tree macro is like this a/b, ssspc is like this b of a.
Actually ssspc is very simple. @Ste_W understand the principle from a few instructions. The explanation part of the tutorial, including examples, is only a few dozen lines of text. Understand the principle, naturally know what effect ssspc has.
Or you can open the URL below and observe the results on the right. Then click on each link in PARTS and observe the results. You’ll see what sspc can do.
There is a concept here called full parsing. A mix of documentation and wiki links is called fragment parsing in the documentation.
The ssspc can be used in place of tags and backtags because it allows for link jumping.
ssspc can replace fields because it has RDF functionality. And the value of a field is a link, so that it has knowledge graph functionality.
ssspc can replace search. Provided the title is fully parsed. The advantage of this kind of search is that the search results don’t become unreadable because there are too many of them. Because it searches for fragments, not whole sentences.
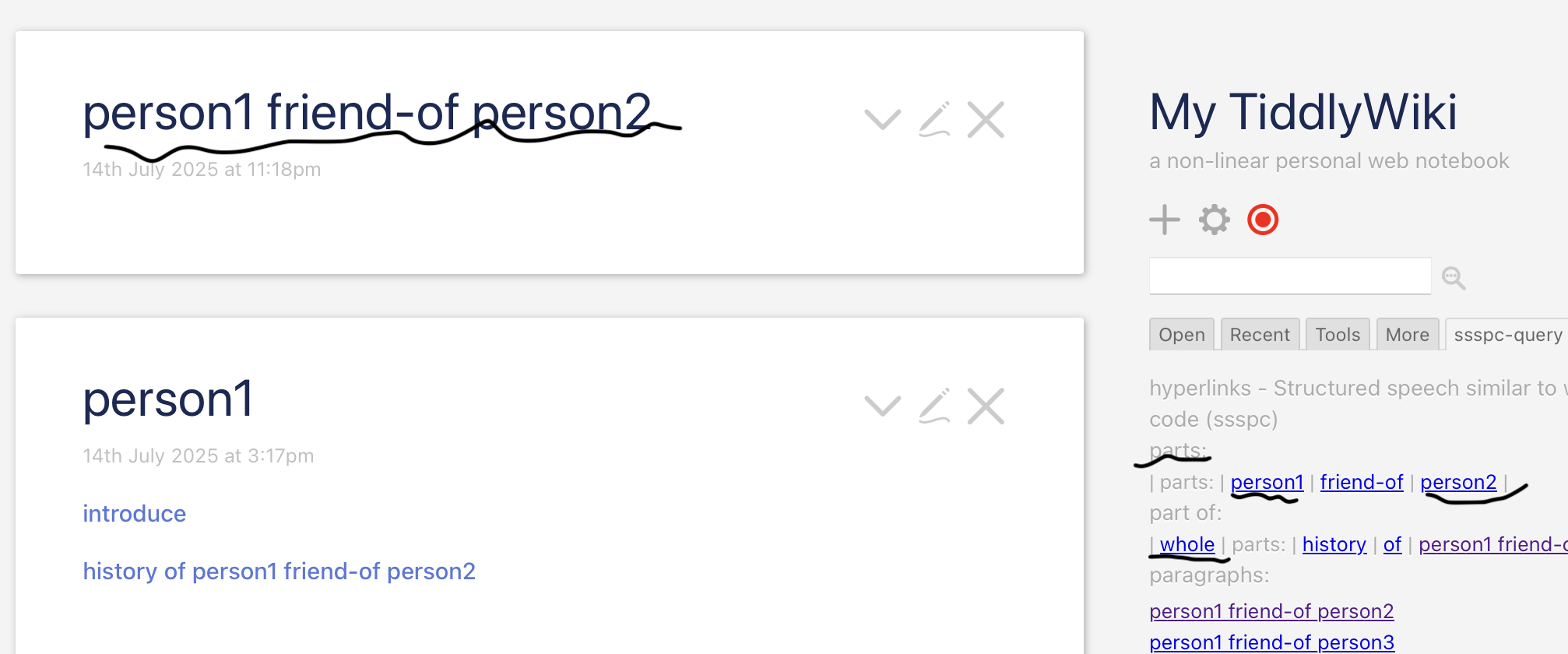
For example, a search for person1
will give you person1 friend-of-person2,
not history of person1 friend-of-person2.
When you click whole
to switch to person1 friend-of-person2 ,
you get history of person1 friend-of-person2.
ssspc can be used instead of tree macro. you can browse to the higher level of directory or the lower level of directory. both tree macro and ssspc are composite IDs. composite ID means several IDs are combined to make a new ID.
I’m curious as to how you would structure declarations for this, and how rigid they would be. For instance, in natural language, we might also write “George Washington was President between 1789 and 1797”. Or “Grover Cleveland was President from 1885 to 1889 and again from 1893 to 1897.” I wouldn’t be surprised if we needed to convert the latter to two separate facts; that just makes sense. But would we also need to settle on one of “served as U.S. President” and “was President”, and to settle on one of “from year1 to year2” and “between year1 and year2”, or are there mechanisms for such aliases?
In RDF that would be captured by a few separate facts, perhaps
But, certainly, it’s not expressible in any reasonable way in just one triple.
I think this is a good part of what I was missing. I thought you were declaring these facts more explicitly (in that sidebar box, perhaps?) So a fact is a tiddler title? Interesting.
I didn’t either in the thread where I used it. I just created a very small wiki from an area that I thought would be widely understood (and which I wrongly thought was related to the OP’s goals) and used it to demonstrate a technique. To me that’s an important part of demonstrating ideas: show them in as realistic a a context as I can. I find that helps demonstrate their usefulness and their limitations.
In any case, this is very interesting to look at. I will try to dig into the implementation this weekend. I’m a sucker for a good parser!
John-Quincy-Adams served-as U.S.-President from 1825 to 1829 One meaning is limited to one way of expression. Try not to have more than one way of expressing it.
What if you don’t know the name of Tom’s sister as well as Jerry’s sister? Nested structures can also be called anonymous records. Nested structures or called anonymous records save a lot of de-naming.
The person1 friend-of-person2
in (history of (person1 friend-of-person2)) is not only a relationship but also a title, and is also part of a title.
Of course, some relationships are not titles. It’s just recorded inside a tiddler.
That helps a little with the how. It would definitely have sped up my learning.
But I for one would love to see more of the why. Do you see this as a way to enhance certain data-heavy wikis? If so, what sorts, and how would you do do? Or do you see this as a way to use Tiddlywiki to display the results of your logic language? Are you using SSSPC as an extension to improve TW, or the reverse? Or something else entirely?
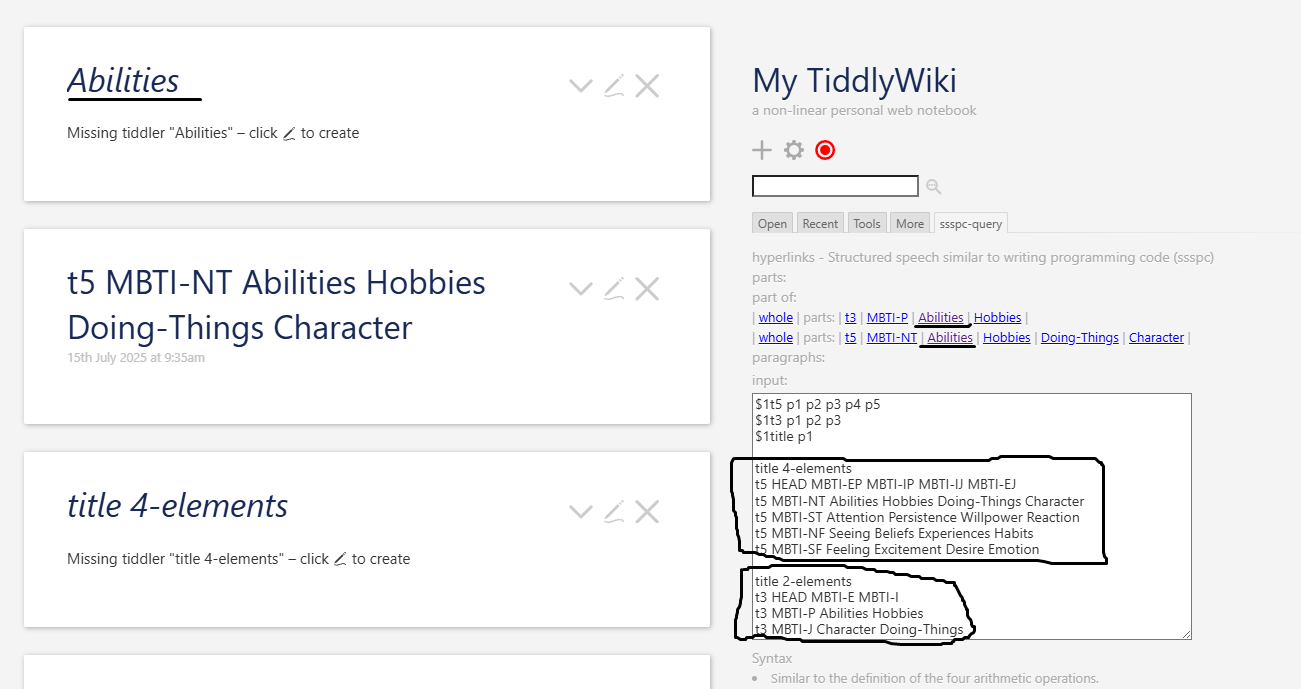
Take a look at this topic. Using this method, any structured title can be parsed.
Like journals and trees, information resides within the title. Some clients also prefer placing details such as people, places, and times within the title. These are structured titles. If such structured titles can be separated by spaces, they can be linked together using sspc.
I do understand that. And I saw that article as well.
But we seem to be talking past one another here. You were involved in another thread where someone asked how to keep changes in sync. I responded with an example of the sort of design I was promoting. But I could just as easily have given a description of it. In fact, I did give a reasonably thorough description as well as a link to a small running sample.
I wish you would do the same for SSSPC. That it can parse log files is… fine. Are you suggesting that a good usage of SSPC is as a log-file viewer? Because I would be surprised if TiddlyWiki would scale to handle the sorts of log files I tend to deal with in my day job, where hundreds of thousands, million, or tens of millions of records are common, not to mention the conversion efforts required from a plain text log file to a wiki.
So my standing question is still, what would you use this for? Is there a good example of a wiki one might want to create that would be best designed if we incorporated SSSPC? Or is this not the goal at all, and do you want to use this tool chiefly to display the sorts of logical statements that might be supplied to Prolog or a miniKanren? Or is there some other use that I simply haven’t considered?