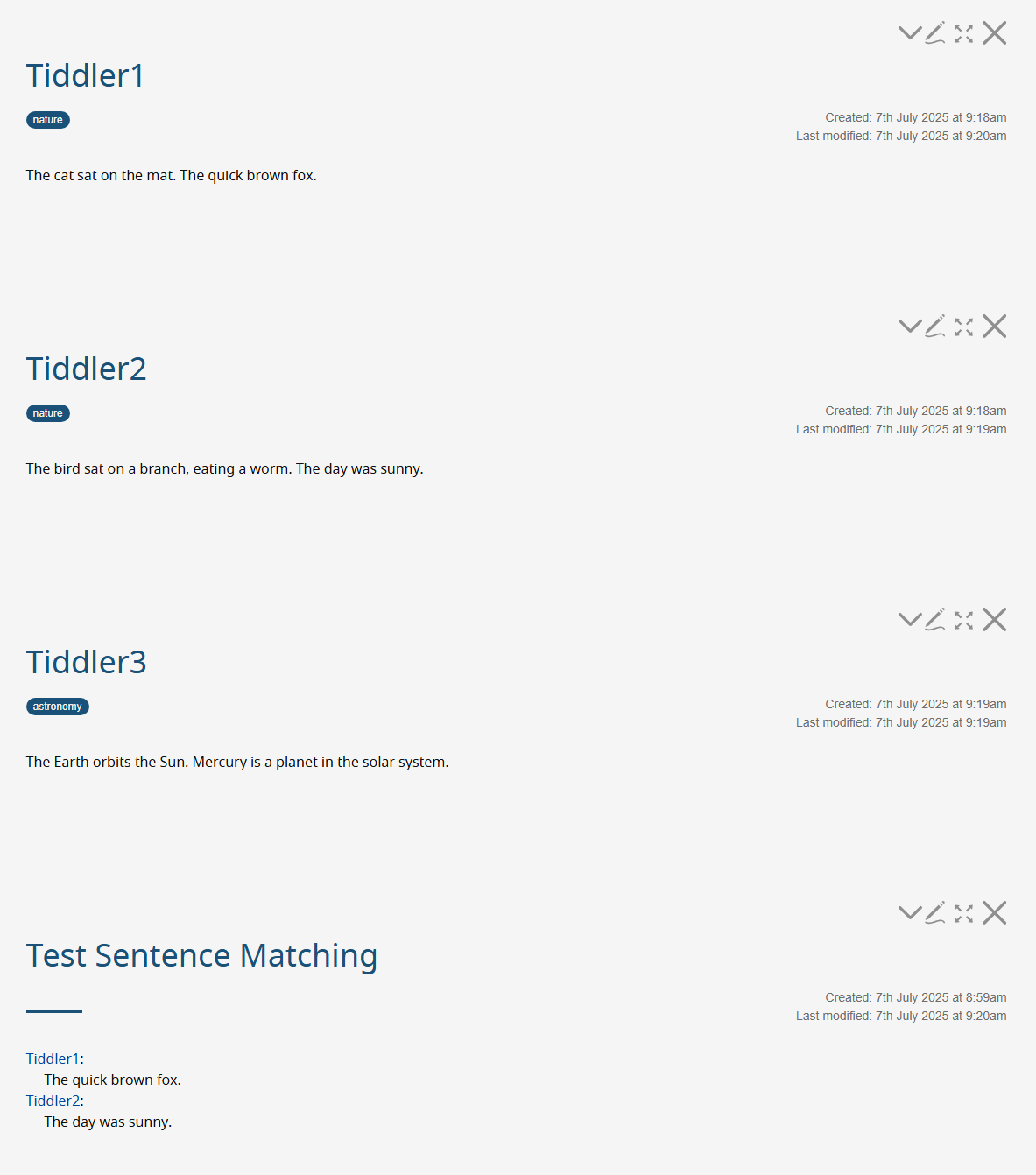
As @twMat states, you need to define what constitutes a sentence. In TW we have too many structures to content with… HTML, WikiText, bullet points, periods in the middle of sentences (such as ‘The quick brown fox startled Mrs. Emily Green.’). There is the issue of compound words or words with words… ‘holiday’ when you search for ‘day’.
In any event, I asked CoPilot for a JavaScript solution. It elected to extract HTML from the text and end a sentence with a period or a new line. It also addressed the embedded word issue. Otherwise, the other issues remain. I wrapped the method in a filter operator (called ‘sentences’). You will likely need to tweak it to your needs.
You need to write a procedure, but take care… for example, the following does not work well because of the embedded word issue. The first filter uses out-of-box TW filter operators and attempts to find the tiddlers while the second list filter finds the sentences (new operator to return sentences). This first example will find holiday to match with day when finding the tiddler, but then fail to find the sentence because holiday does not match.
<$list filter="[tag[nature]search:text:some[quick Mercury day]]"><$link $to={{!!title}}>{{!!title}}</$link>:<br/>
<$list filter="[is[current]sentences[quick Mercury day]]"> {{!!title}}</$list></$list>
So, instead, I added another filter operator, ‘tiddlersentence’ to find tiddlers: this needs a better name.
<$list filter="[tag[nature]tiddlersentences[quick Mercury day]]"><$link $to={{!!title}}>{{!!title}}</$link>:<br/>
<$list filter="[is[current]sentences[quick Mercury day]]"> {{!!title}}<br/></$list></$list>
Warning… I did very little testing…
$__plugins_cls_mk_filters_matchsentences.js.json (2.8 KB)
Import the json file, save and reload… and test.