I have a Discourse forum allthebest.recipes that started as a TiddlyWiki, migrated through other wiki types, and now I’m deciding that running an entire Discourse forum for just me doesn’t make much sense, so I wanted to figure out (1) how to export all the content, and then (2) how to import into TiddlyWiki.
I got @joshuafontany’s JsonMangler working for CSV import after much trial and error, and uploaded the transformed tiddlers into my twgroceries#Data/ATBRecipes.
Various other tips from Joshua in an old thread (mail-archive.com) were helpful in getting started.
How to Export from Discourse
Discourse has a Data Explorer Plugin which lets you run SQL queries directly through the web interface. I think
The SQL I used, for 297 results, was this:
SELECT t.title, p.raw as text, p.created_at as dateposted
FROM posts p
LEFT JOIN topics t ON t.id = p.topic_id
WHERE t.archetype != 'private_message'
AND t.user_id = 2
AND p.user_id = 2
AND t.category_id IN (1,21,19,24,18,23)
AND t.deleted_at is null
This gets you the title, the “raw” text (so unrendered markdown), date it was created. I didn’t bother with tags or anything else. I called it dateposted to not collide with the default created field in TiddlyWiki. There’s probably a correct way to do this so you can actually preserve the created timestamp in TW directly. title and text are the correct field names in TW.
It then grabs all the comments (topics) as follow ups to the original post, and filters out private messages.
Then it matches only things that I posted, and filters by a handful of categories.
This can be exported as a CSV or a JSON file, and I chose the CSV version so I could more easily edit in bulk if needed.
How to Import into TiddlyWiki
I used the JsonMangler demo site directly for the following steps.
Import your CSV data
Create a new empty tiddler
Set the type to application/csv
Open the CSV file on your computer in a plain text program like TextEdit on Mac or Notepad on Windows and copy the entire contents.
Paste into the empty tiddler, give it a name related to your data, in my case atbrecipes.
Hit the checkmark to save the tiddler, and it should be transformed into rows like this:
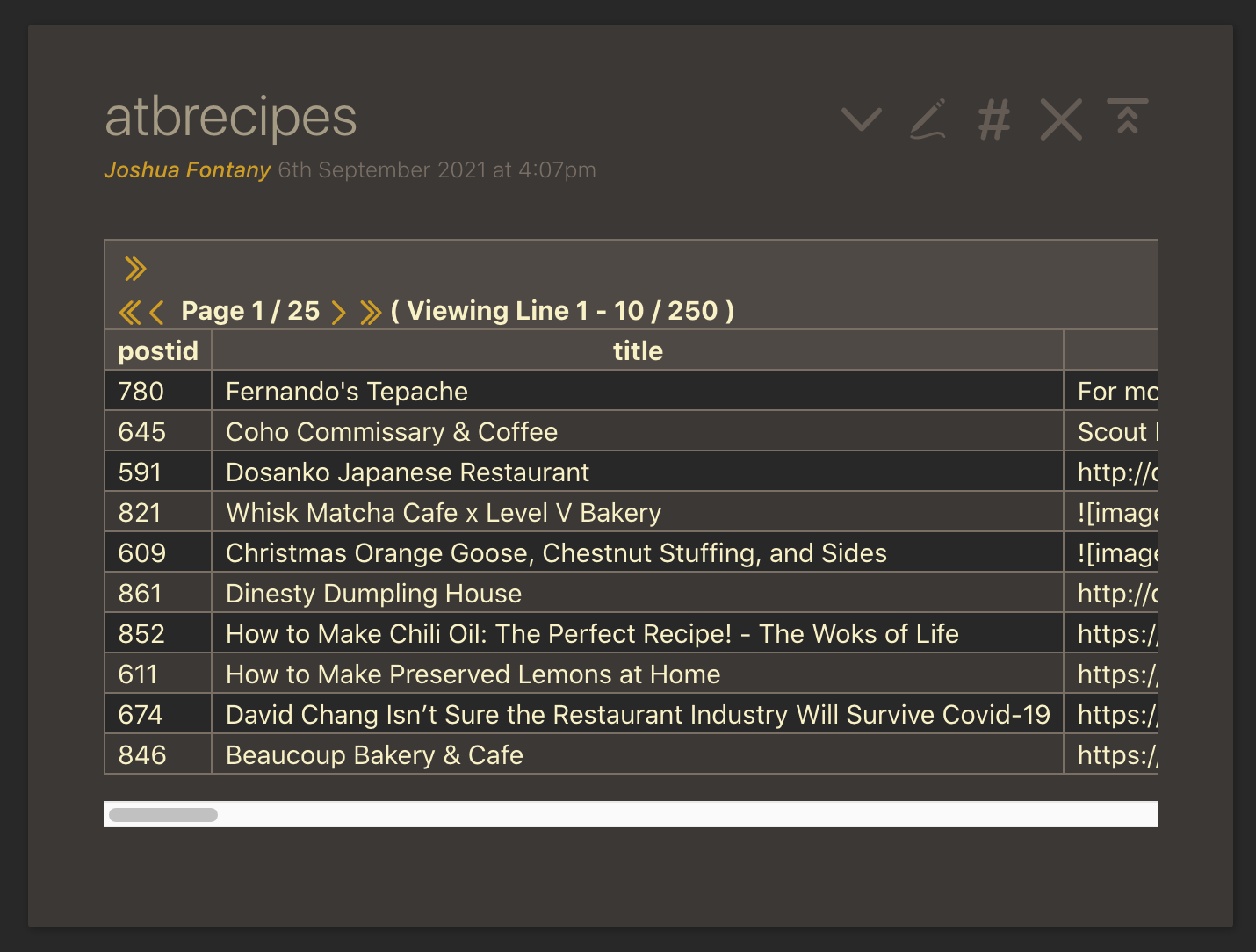
Transform into Tiddlers
The disclosure triangle at the top of the CSV tiddler can be opened to reveal a bunch of options.
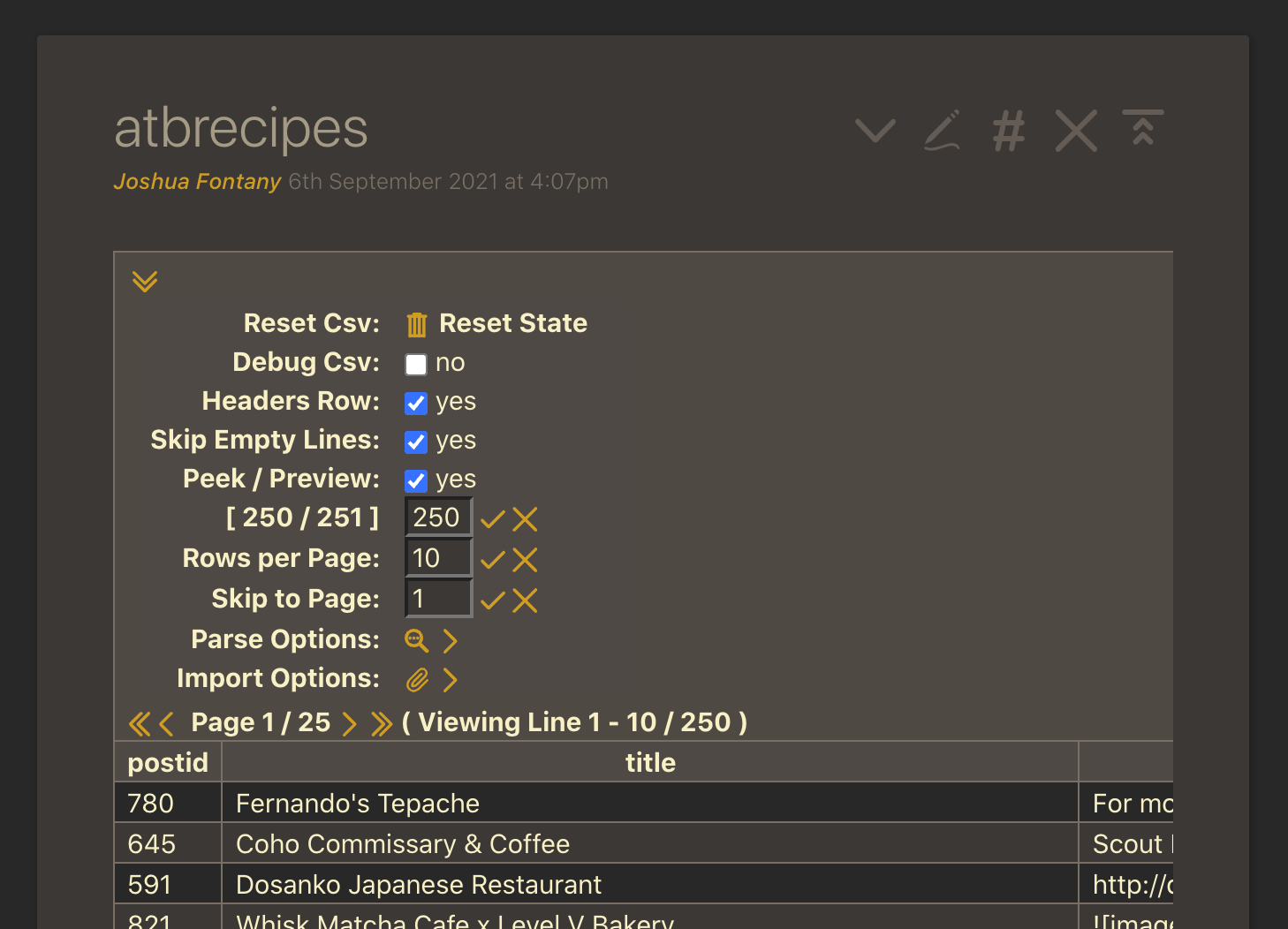
And inside that, the Parse Options and Import Options have sub settings as well:
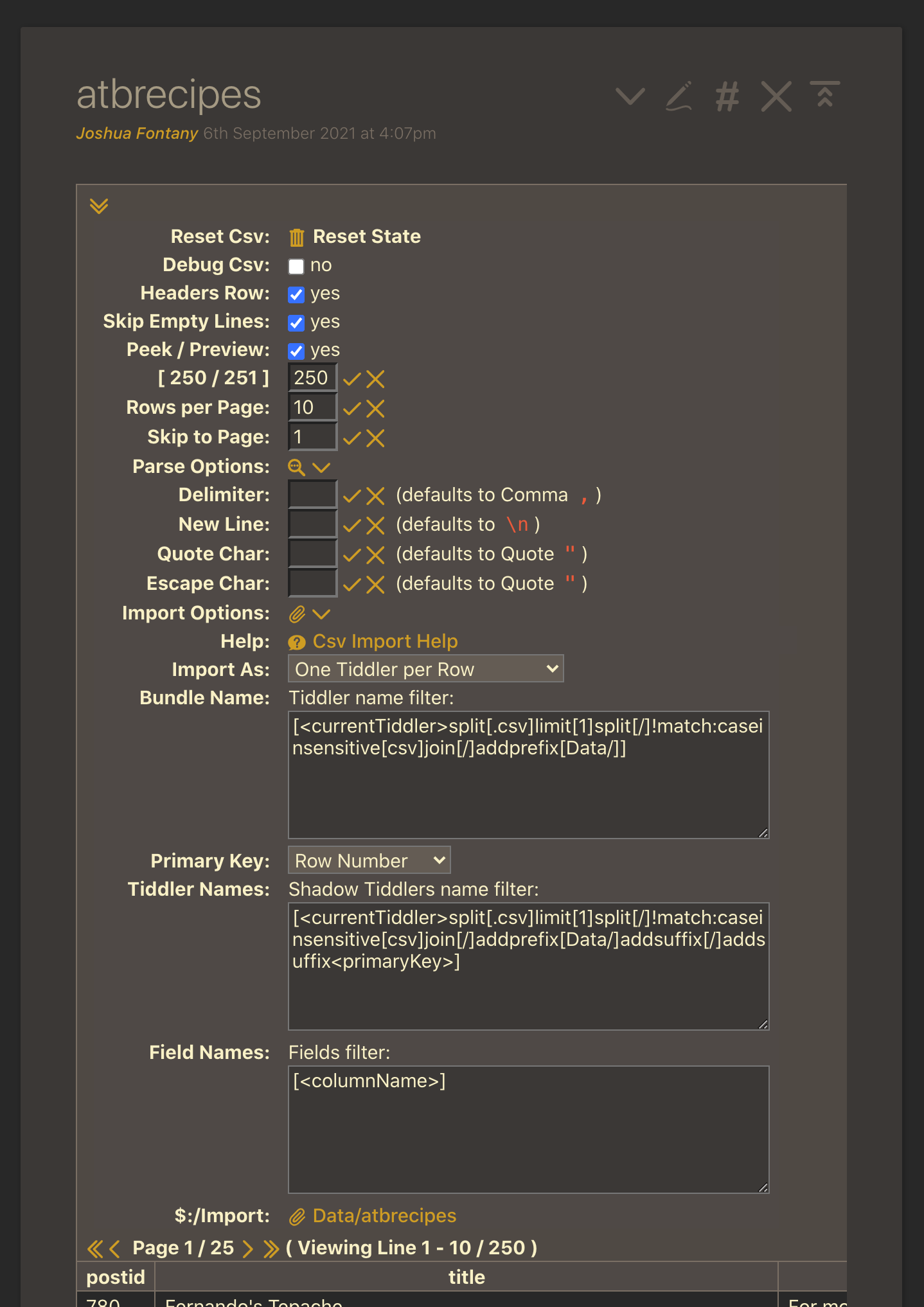
For Bundle name, the import line at the bottom will live update with what the name is. The default is fine.
For the Primary Key drop down, your columns will be listed, starting with Column 0. In our example, Column 0 is the unique postid of the Discourse forum id – which applies to both “first posts” and replies. Column 1 is the title of the post, and we’d like to have that be the name of the tiddler.
For Tiddler Names, the Shadow Tiddlers name filter I edit to be:
[<primaryKey>]
Because I’ve selected Column 1, which is the title field, the tiddlers will be named as the post titles in Discourse. Note: comments will overwrite first posts on import – need a solution here to append postid or row number to the title from Column `
Click on the name of the file at the very bottom next to Import (Data/atbrecipes in the screenshot) and this will pull up the standard import dialog. Go ahead and run the import and click on the imported tiddler.
You now have a plugin filled with Shadow Tiddlers, timestamped with the time of your import, which looks something like this:
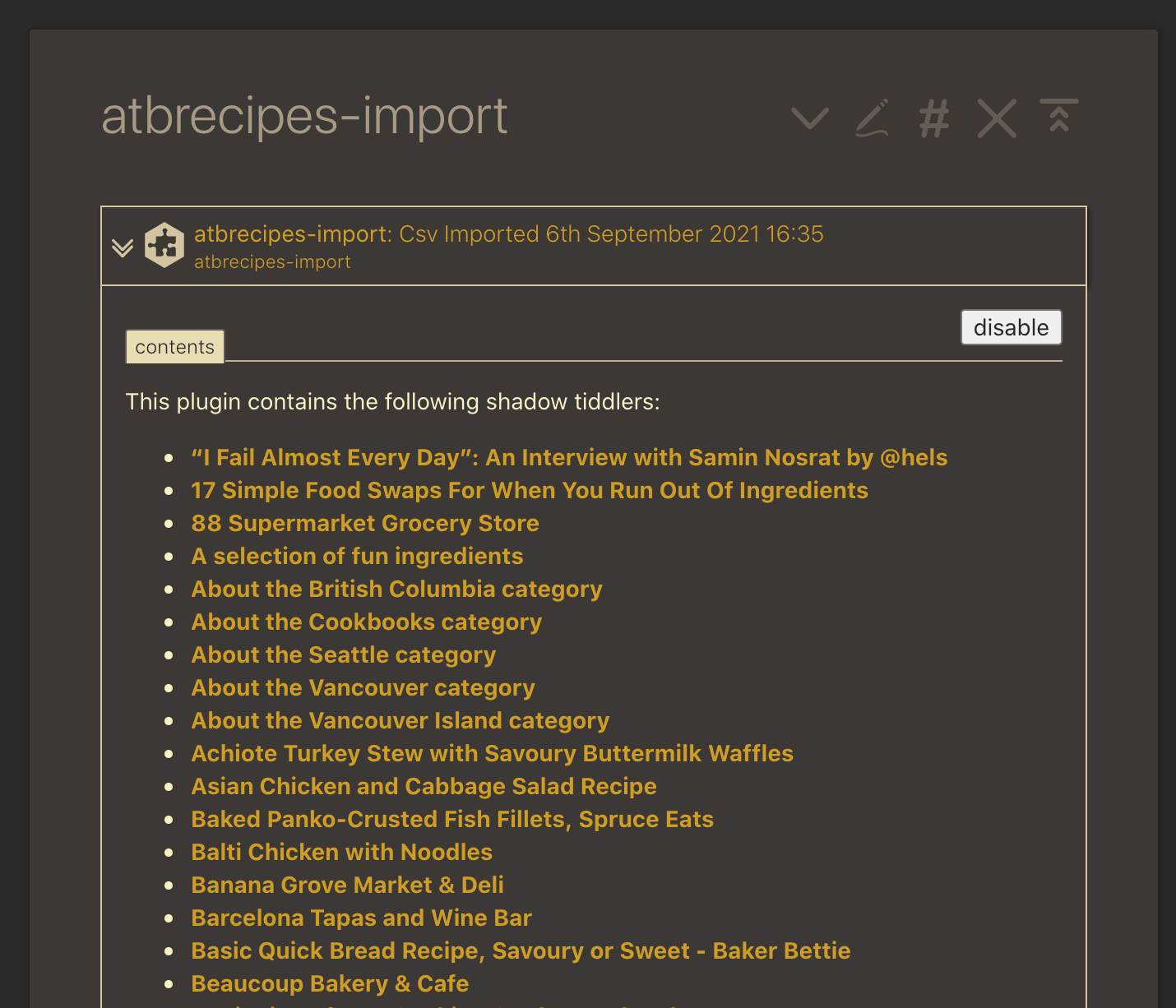
Now you can drag and drop this plugin tiddler into a wiki of your choice, and it will import all these tiddlers as Shadow Tiddlers. From the csvImport help file:
In these modes each individual row is rendered to a tiddler, then these tiddlers are packaged as shadow-tiddlers into a plugin. This takes advantage of the shadow-tiddler features such as replaceing an import all-at-once, comparing multiple snapshots, overwriting and restoring shadow tiddlers, etc.
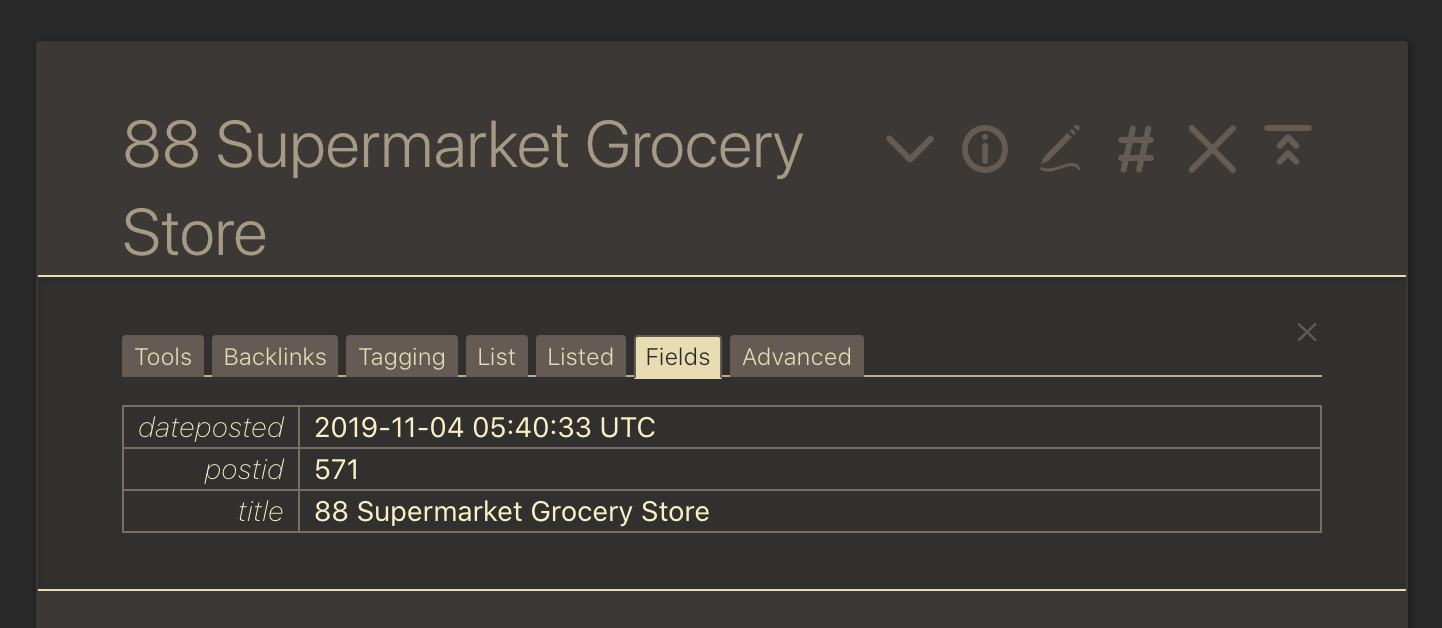
Here is an example imported tiddler, showing the fields that were imported:
Remaining Issues / Improvements
Below are some issues and improvements that could be made, either on the TW side or in constructing the SQL query to get the right output.
Uploads in Discourse in the raw mode look like upload://cfANkmI0Du5wBvkR6WhzruGeY3R.png. This needs to get turned into image paths like https://talk.tiddlywiki.org/uploads/default/original/1X/55dd56118b52a85be63871975eda26087ae1d88f.png. But that will of course not work offline and will point to the “live” server, which is not ideal. The Discourse backups function includes an export of all uploaded files that could be extracted.
(TW) Use the Markdown plugin and properly label as Markdown tiddlers
(SQL) For multi-user Discourse forums, include the username as a column named “creator” to automatically go in the right field for TW.
(SQL + TW) Include a field or tag or something so that replies are applied. I guess the core Comment plugin might be used too?
(SQL) Have sample SQL so just “first posts” are included.
(SQL) Include tags and categories, turn them both into TW tags.
(TW) Description of converting Shadow Tiddlers to real tiddlers
(SQL + TW) The dateposted is a string right now. Could have it be the created core field, just need to transform that string into one that works with TW
