From Absurd Big Clumsy Database ™ I can get various JSON files, but I can’t control their format.
Each is a flat (spreadsheet-structure) JSON file, but no field (no “key” in the JSON) is called title.
I’d like to convert these JSON files into batches of tiddlers, but of course tiddlywiki “out of the box” won’t import from a JSON lacking a title field.
I understand I could write custom deserializers (in theory, with a learning curve!), but there’s not a single field that appears consistently across all these files. And writing multiple ad-hoc deserializers seems like the wrong way to go. I could also pre-process each of files with a search-and-replace function. But this is potentially a routine workflow going forward, and I’d like to streamline it.
Could there be an on-the-fly solution?
I’m imagining a deserializer that allows the user to edit a field value (ultimately with a setting/CP interface) to specify, prior to dragging in an import, which incoming field (json key) should serve as the title field?
Then all I would have to do is peek into the next JSON on deck to see that … this one will have a suitable incoming “description” field that I can treat as tiddler title … and now this one will have a reliably unique “id” field that can serve as title… etc.
I would entirely ignore any field from the JSON. Just create a new unique title if non exists in the JSON to be imported.
IMO a custom importer and / or upgrader should be able to handle that. But I am not sure, since they also work with titles. So some experimentation would be needed.
I had imagined exactly this, as well as allowing control over mapping of other fields, when we last discussed JSON import in the context of moodle. This actually points out a need for refactoring the import mechanism.
For the time being a quick fix might be to toss your JSON to ChatGPT and ask it transform the JSON mapping a selected field to title.
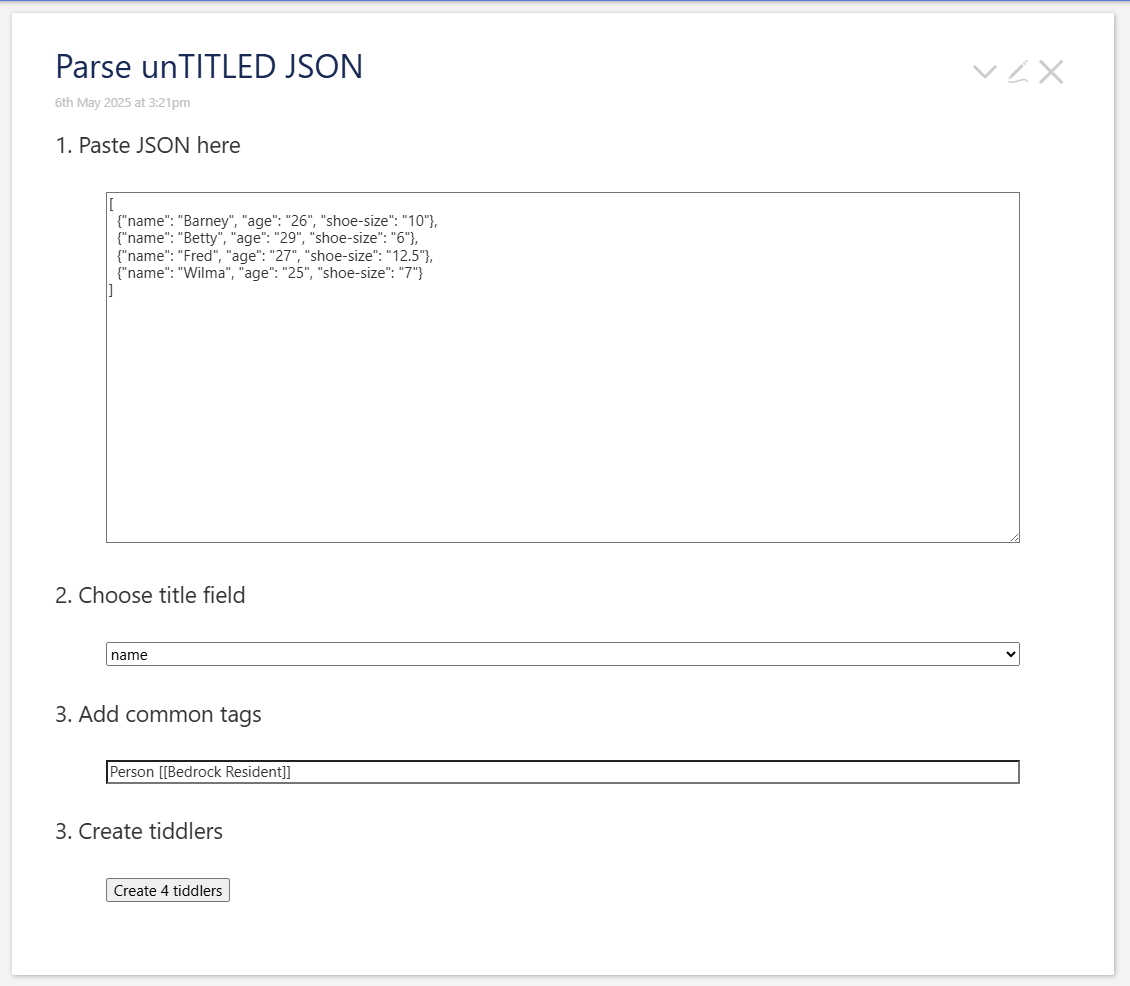
I have an alternative approach that I hope to have time to complete this evening, but can’t do so right now. The idea is that instead of trying to modify the import process, we have a text area to paste your JSON. The code finds the first record in the JSON and extracts the field names, offering you a choice of which one to use for your title, and putting the others into fields. Presumably you would also want to add specific tags, so there’s an entry for that. And then there’s a button to create the tiddlers. Here’s a screenshot of a naive version of that:
There would likely be additions to this idea. I can easily imagine allowing the user to enter a filter instead of a single field name ([[Person/] [<first-name>] [[ ]] [<last-name>] +[join[]], for instance, to give the tiddler a name like Person/Fred Flintstone) and perhaps offering a running sequence number, to create ones like Person/3. These ideas would be necessary if there is no single field that is unique across the whole JSON input; even if there is, the additional control over the title seems useful.
It’s also quite possible that there are other fields you would like these tiddlers to have in common, so there might be a way to specify common field name/value pairs.
All of these can be added fairly easily I believe.
We also might want a test-run capability that generates a compound tiddler you can verify before actually adding them to the wiki. Or we might want to offer a mapping of selected field names ("type" could be a common problem) and an simple way to exclude certain fields. But all of that would be for later, only if this idea in the end makes sense.
What works in here is the parsing of the JSON to offer a choice of field names for the title, the entry of common tags, and the creation of tiddlers with the proper title and tags. But it’s not yet properly adding the other fields. If someone can tell me what’s wrong with this, perhaps we can fix it quickly:
I think there is something wrong with the extraction of $fields and $values in the inner action. I’m thinking it’s likely mainly a syntax error, but it could be a more fundamental misunderstanding; these JSON operators still do not feel at all natural to me.
Wow, this looks fantastic, Scott! I’m looking forward to testing it out!
Since you anticipated the potential need to use a filter expression to compose the tiddler title, I’ll just enlist your sympathetic exasperation with the fact that I’m also stuck doing the inverse of that in this workflow:
The ABCD (to which I alluded above ~cough~moodle~cough~ ) insists on spitting out a JSON log which concatenates various fields’ worth of info into a text field called description which looks like this:
The user with id ‘94135’ has viewed the discussion with id ‘834301’ in the forum with course module id ‘6422219’.
And no, it does not offer any option to retrieve those key-value pairs directly.
Alas, I can’t submit anything related to educational records (the ABCD above is indeed moodle) via ChatGPT or other online services (unless there is a decently secure guarantee that the data is not being fed to the corporate borgs).
I can of course do SnR on each file via BBEdit and such, but again I’m considering how to make a sane workflow from moodle output to tiddlers (which continues to work great for the special case that you already solved — and it makes a great difference to my routine workflow!)
I’m afraid that I didn’t get any time to work on it last night. Local politics can be all-consuming.
I don’t have further thoughts on the place I got stuck, so if nothing comes to me this morning, I may raise that in its own topic.
As a programmer, I do that sort of data extraction all the time. If the records are consistently of that format, with only the IDs changing, then it’s easy enough to do. But in these sorts of things, complexities always pile up. Many of my wikis are data-heavy, with some external source that requires substantial massaging before I import it into a wiki.
What I’m proposing above would allow us to do the simplest versions of this sort of massaging in-wiki.
There is a way of thinking. You can first merge the json file into a large json file, then convert it to csv using an online tool or python, and edit the csv file with excel (check the csv field values exported by standard tiddlers), such as using ctrl+D to fill. Set the default title field as uname in cell a1 and automatically fill it with (uname1, uname2, uname3,…) Or (uname, uname, uname,…) Save the csv file, and then use an online tool or programming language to convert the csv edited in excel into a json file supported by tiddlywiki
I created a version that fixes the issue discussed above. (There were several problems, but I think the one that consistently caused issue over my many attempts was in using {{{ - }}} in a place I needed to be using " - ".) Thanks to @saqimtiaz, whose earlier post in another topic demonstrated a similar process and straightened me out.
It does not attempt any of the extensions discussed such as using a filter instead of field for title, offering a sequence number, adding common custom fields beyond tags, or filtering/renaming the included fields. I think all of those would be straightforward to add. It certainly doesn’t try my idea of creating a compound tiddler as a dry run of the conversion before you modify the current wiki. I think that would be useful, but it sounds like much more work.
I don’t know if I’ll pursue this further. My personal workflow, of writing JavaScript conversion code to create tiddlers that I can simply import has been working for me for many projects. But I can see the benefit of this for myself in the simple cases and for non-programmers for many cases.
If you’re looking for any of those extensions I (recklessly) called simple; let me know, and I’ll see what I can do.
Thanks for thinking of another possible workaround…
I’m actually not lacking in ways to pre-process the JSON with search-and-replace tools (I can do that with BBEdit without going through CSV-conversion step). It’s just that I’m looking forward to having a way for this routine task to be as easy as drag-and-drop (or cut and paste).
I confess I didn’t understand your suggestion at first (and worried that you hadn’t understood my task, though I also knew that was not likely!). Coming back around to this thread, I think I do understand!
The importer could easily be configured to look for a title key and use if it exists, AND in the event that a JSON record lacks a title key (or maybe only if the whole batch lacks a title key), assign an arbitrary unique identifying string to each record — maybe a super-granular timestamp? — and map all of the existing key-value pairs just as they are into fields.
This would indeed be the least fiddly solution!
It also has the advantage of never bypassing the field name assigned by my ABCD source (though I might have to scan to make sure “type” never shows up to cause trouble). Also, the *&!@^%# database actually exports some JSONS that lack a reliable unique identifier field. And your idea would allow me to import those without worrying that I might accidentally lose a record by mapping lastname onto title (for an array whose records correspond to students), or something like that.
Once the JSON is imported, I can batch-process as needed, with a tool such as Commander or something more nuanced (to construct compound tiddler titles, etc.).
And in many cases, I might not even bother to rename these. As with a tool like streams (which I don’t use, but I’ve vaguely followed), I could interact with these tiddlers by working with the various fields that are of direct interest…
Here’s a two-record identifier-scrambled snippet of one such JSON, though there are many different export arrays (All JSONS from this source do start and end with those double-brackets, which I’m used to modifying prior to import, though having tiddlywiki handle that would be great too!):
[[{
"time": "05\/5\/25, 20:52:01",
"userfullname": "Amelia Zamilia",
"affecteduser": "-",
"eventcontext": "Forum: Reading responses for final unit",
"component": "Forum",
"eventname": "Discussion created",
"description": "The user with id '99985' viewed the 'forum' activity with course module id '9999029'.",
"origin": "web",
"ipaddress": "172.xx.xxx.xxx"
},{
"time": "05\/3\/25, 17:31:59",
"userfullname": "Howie Hope",
"affecteduser": "-",
"eventcontext": "Course: MYCOURSE-Sp2025 - Course Title",
"component": "System",
"eventname": "Course viewed",
"description": "The user with id '99589' viewed the section number '2' of the course with id '99049'.",
"origin": "ws",
"ipaddress": "172.xx.xxx.xx"
}]]
Editing to add: some of the files do use numeric values (not always quoted text-string values, as in the snippet above). So, here’s how a different example looks (again — if it matters — this comes from a JSON with many records, but each repeats this same structure):
gives you the freedom to tweak all sorts of things using TW wikitext
As I saw the data structure I thought about ChatGPT to create a small cli app for me. For JSON conversions like this one an LLM is quite capable to create small, understandable and working JS code.
The important thing here is the input-prompt given to the LLM using the free version of Edge Copilot. It has to be relatively detailed. But the code it gave me worked right from the start.
The disadvantage here are:
It needs Node.js and a code editor like VSCode for debugging if needed
It would be for programmers only
The advantages are:
ChatGPT free version can easily extend the functionality if needed. eg:
Timestamp conversion
Creating a more detailed unique title using existing fields or what every you can imagine.
Edge Copilot Input Prompt
- You are a JavaScript expert.
- We use js modules with no external libraries.
- We need a node.js based CLI that gets 2 parameters.
- The first parameter is the name of an input JSON file.
- The second parameter is the name of an output file.
- The parameters allow us to use paths.
- the cli should work with windows and unix OSes.
- the input format looks like this:
```
[[{
"time": "05\/5\/25, 20:52:01",
"userfullname": "Amelia Zamilia",
"affecteduser": "-",
"eventcontext": "Forum: Reading responses for final unit",
"component": "Forum",
"eventname": "Discussion created",
"description": "The user with id '99985' viewed the 'forum' activity with course module id '9999029'.",
"origin": "web",
"ipaddress": "172.xx.xxx.xxx"
},{
"time": "05\/3\/25, 17:31:59",
"userfullname": "Howie Hope",
"affecteduser": "-",
"eventcontext": "Course: MYCOURSE-Sp2025 - Course Title",
"component": "System",
"eventname": "Course viewed",
"description": "The user with id '99589' viewed the section number '2' of the course with id '99049'.",
"origin": "ws",
"ipaddress": "172.xx.xxx.xx"
}]]
```
There are several objects in a nested array.
The output format should look like this:
```
[
{
"created": "20230123143521569",
"text": "some text in new tiddler",
"tags": "",
"title": "New Tiddler",
"modified": "20230123143530358"
},
{
"created": "20230123143053957",
"text": "Some text in the Hello World tiddler. \n\nhello-field: {{!!hello-field}}",
"tags": "",
"title": "Hello World",
"modified": "20230123143519470",
"hello-field": "some text in hello-field"
}
]
```
For the output format it is essential that there is a `title` field in the object.
If no title is available in the input, we create a numbered title with an increasing number. eg: NeedsTitle 001, NeedsTitle 002 and so on.
All the input fields need to be preserved in the output file
The Code it Returned
Got it! Here’s your Node.js CLI script that meets all your requirements:
Implementation
javascript
#!/usr/bin/env node
import fs from 'fs';
import path from 'path';
function readJSON(filePath) {
try {
const rawData = fs.readFileSync(path.resolve(filePath), 'utf-8');
return JSON.parse(rawData);
} catch (error) {
console.error(`Error reading or parsing JSON file: ${error.message}`);
process.exit(1);
}
}
function generateTimestamp() {
return new Date().toISOString().replace(/\D/g, '').slice(0, 17);
}
function generateTitle(index) {
return `NeedsTitle ${String(index).padStart(3, '0')}`;
}
function processData(data) {
let titleCounter = 1;
return data.flat().map((item) => ({
...item, // Preserve all input fields
title: item.title || generateTitle(titleCounter++), // Ensure title exists
created: generateTimestamp(),
modified: generateTimestamp(),
text: item.description || '',
tags: ''
}));
}
function writeJSON(outputPath, data) {
try {
fs.writeFileSync(path.resolve(outputPath), JSON.stringify(data, null, 2));
console.log(`Output written to ${outputPath}`);
} catch (error) {
console.error(`Error writing JSON file: ${error.message}`);
process.exit(1);
}
}
function main() {
const args = process.argv.slice(2);
if (args.length !== 2) {
console.error('Usage: node convert.js <input.json> <output.json>');
process.exit(1);
}
const [inputFile, outputFile] = args;
const rawData = readJSON(inputFile);
const processedData = processData(rawData);
writeJSON(outputFile, processedData);
}
main();
How to Use
Save this script as convert.js Run it from the command line:
The same code also worked for the second example JSON you posted.
Important:
If you use existing fields to create a new name you would need 2 different converter js-files.
To make it proper Node project a bit more boilerplate files and directory structure would be needed.
The input prompt would be: how should the directory structure and the boilerplate files for a node.js project look like. We want to use semantic versioning, starting with 0.0.1