My plan is following:
I want to create a tiddlywiki for my wardrobe aims. I want to create an Tiddler with a picture of an outfit I like. After that I want to add tags to this tiddler to classify the different outfit parts.
The tags which are used to classify should have a tags in following format:
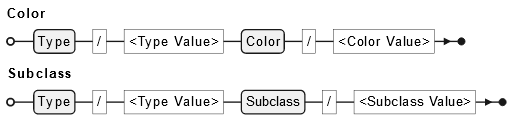
A simplified example of the tiddlers could be:
Outfit A
tags:
Type/Trousers/Color/Blue
Type/Trousers/Subclass/Jeans
Type/TShirt/Color/White
Type/TShirt/Subclass/Polo
Type/Belt/Color/Brown
Type/Belt/Subclass/Woven
Outfit B
tags:
Type/Trousers/Color/Grey
Type/Trousers/Subclass/Chino
Type/Shirt/Color/Brown
Type/Shirt/Subclass/Business
Type/Belt/Color/Brown
Type/Belt/Subclass/Plain
Now I want to create a tiddler with a buying list which is sorted by the descripted combination count (in this example “Type/Belt/Color/Brown” has the most combinations). By this list I know which part I should buy next to complete my desire wardrobe.
Another example for a useful tiddler would be one which shows the color which should be combined with another to get the desired wardrobe style.
To list the tiddlers uses Regexes like this:
^Type\/(.*)\/Color\/(.*)$
^Type\/(.*)\/Subclass\/(.*)$
So I don’t want to list all combinations but only the ones that match with a certain regex. This might put the performance concerns into perspective a bit.
@Springer
Your “busy tag-intersections” is already very close to the solution of my problem. But if there is any possibility to list the combinations sorted by the count, I would prefer this solution. I think if the list will get long the sorted count solution has advantages.
The “Combined Tag Filter” is very cool and I think i will use a modified version of it in my wiki because with this I have the possibility to create outfit quickly. The only thing i would add is again a count after each unselected tag which shows how many outfits are possible with the already selected tags (but that’s another task  )
)
@TW_Tones
- Have a look at the various Tag Cloud Solutions
→ which do you mean exactly
- I Imagine you want non system tags only
→ I want to filter with the regex formulas
- Think about your data, the current tags and ask yourself what is the best way to get an overview and why?
- Sometimes we make these things then don’t use them.
→ For the buying list
- There was a tool called x link that helped review tag combinations but you must select which ones are involved.
→ I will have a look, but for my buying list there I do not want to select the tags
For the problem I currently have only the following impractical solution:
- Use another list around the existing list which are used to iterate a variable backwards from for example 1000 to 1 and use this variable to show the output if the variable matches the count. But that would mean that the existing code would be run 1000 times. This would be a performance explosion!

 Perhaps you don’t really mean “chronologically” (since I’m not sure how a pair of tags would have a time assigned to it, as a pair), but just “sorted according to their combination count”?
Perhaps you don’t really mean “chronologically” (since I’m not sure how a pair of tags would have a time assigned to it, as a pair), but just “sorted according to their combination count”?

 Unfortunately, I am very busy at the moment. I will try to answer you today or tomorrow with a detail description.
Unfortunately, I am very busy at the moment. I will try to answer you today or tomorrow with a detail description.