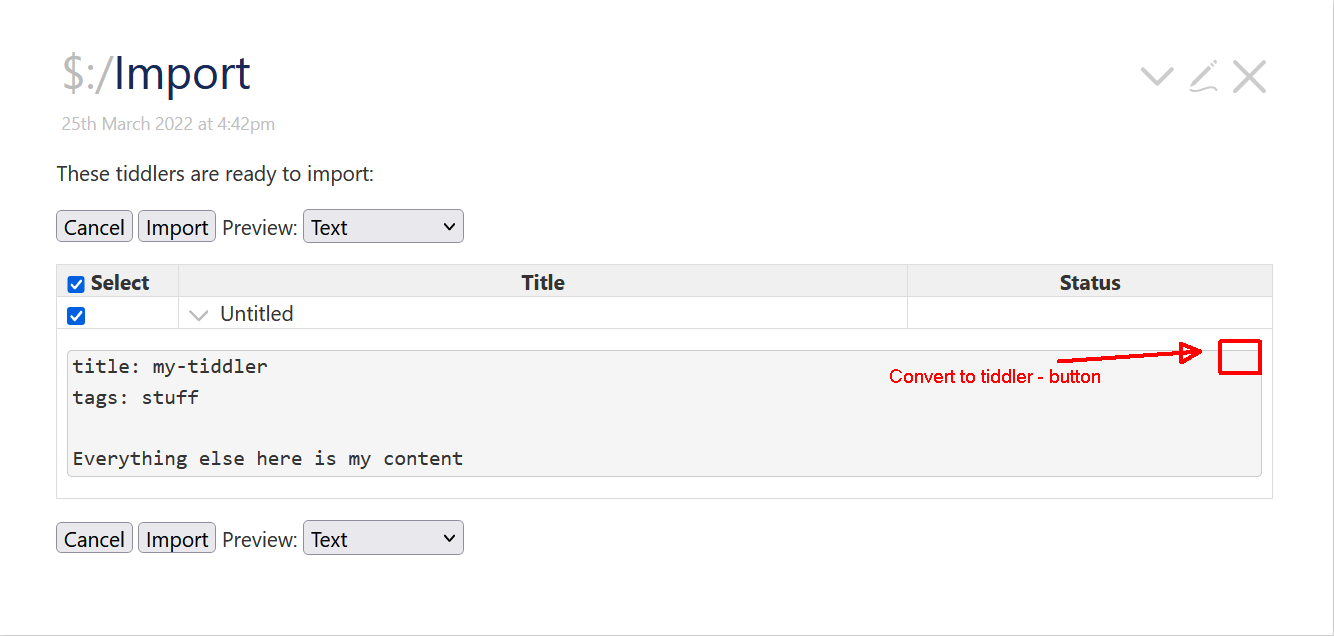
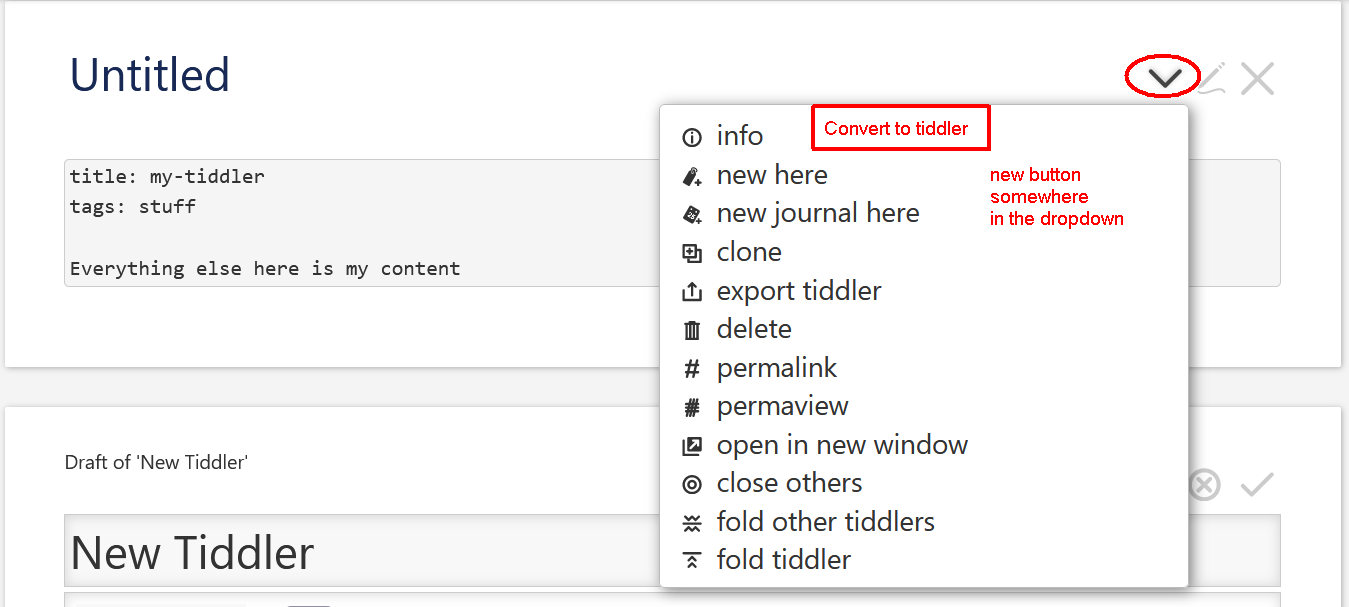
It would be neat if “pseudo tiddlers”, as often expressed in forum discussions, could directly be converted into real tiddlers. I.e if this text:
title: Foo
tags: $:/mytag
text:
howdy dowdy
…could be selected and dragged into a wiki - and it directly becomes a tiddler (as if a JSON tiddler)!
Do consider that this “pseudo tiddler format” is very common and that the context is typically one where one does intend for it to be converted into a real tiddler.
Is it at all possible to create some “interpreter/converter” that is flexible enough to allow such a loose format?
EDIT: I note Discourse features a “copy text” button when hovering the code. So, instead of drag’n dropping onto ones TW it could be to paste it which is even better than drag’n drop. If at all possible.