[This thread split off from Shiraz dynamic tables, use variable in table filter]
I’d be very interested in seeing that, if you’re willing/able to share!

[This thread split off from Shiraz dynamic tables, use variable in table filter]
I’d be very interested in seeing that, if you’re willing/able to share!
I expect that what I’ve done with hours of squinting barely holds up to what you would do with a half-hour of methodical coding. But here’s the current state of the custom functions.
Generally, the only time methodical coding is fast is when you already understand the rules and can easily describe them. The real work is in discovering and formalizing those rules.
This seems to me a difficult impossible problem to get entirely right. I’m on my phone now so won’t be readily able to look at the implementation, but I look forward to seeing what you’ve done.
The varieties you show for the relatively simply Martha C Nussbaum point to how many issues there might be for de la Cruz, or for Willard Van Orman Quine. Just that “Van” would be a headache, given the difference in meaning between Dick Van Dyke and Van Morrison. And if Martin Luther King, Senior also published…
I’ve thought about this problem several times in the past, and always gave it up as a thankless job. To make up for that, here’s my own thanks to you. I look forward to reading the implementation.
I did get a chance to look at these, finally. They look great. It seems that you already have the components for your latter two wish list items, and a good part of the way toward the first. The biggest open issue I see is last name particles — “de”, “la”, “de la”, “van”, “van de”, “von”, et al. But that is very much a non-trivial problem.
I don’t know if honorifics such as “Dr.” or “Lady” are used in academic citations, but they might also cause issues on the first-name side. Also interesting is solo names: Cher, Madonna, Prince. For classic names like Socrates, it seems straightforward to understand that as a last name, with no first. But for these singers, those solo names are in fact first names. Hmm.
I’m not sure whether you’re trying to normalize these on import. That is, would you want an authors field derived from bibtex-author, with an entry like [[Dewey, John]] [[Nussbaum, Martha C]] [[de la Cruz, Sor Juana Inés]]? Or would you want these displayed only on a render of the bibliographic entry that includes them? I see some real advantages in the former—if your workflow permits it—allowing you to do fuzzy matching and gathering together all the Nussbaum, Martha, Nussbaum Martha C., Martha C Nussbaum, etc. records into a single place. But that won’t work for large bulk imports.
Interesting stuff!
Here I split the difference with the “clean the data first” norm.
I’m not going to clean up all the “Lastname, Firstname M.” vs “First Middle Last” variations before using the data, and I’ll keep a short list of suffixes and prefixes that circulate commonly enough as red herrings for name recognition. (with et al being much easier to deal with in some ways, but more difficult in other ways!)
I want to reduce the need to “normalize on import” partly because I’m thinking of a community edition that might be taken up by folks whose needs and data-sources don’t match whatever my preferred standardization might be. (And in particular, I think the Lastname, Firstname M. pattern is more informative, but sometimes we simply do not know how to parse a complex conventional-order name into that structure, and my first mandate is “Do no harm” to the data.  So, the less invasive path is to try for fuzzy recognition that accommodates
So, the less invasive path is to try for fuzzy recognition that accommodates First Second Third (but where does surname start?) mysteries, and to aim for a friendly solution for folks who don’t want to commit to a big initial clean-up.)
But this 98%-good-enough approach means I’m committing to a hand-manipulation of a string like “Sor Juana Inés de la Cruz” — once I do understand which parts should count as the last name (replacing spaces within a last-name-string with non-breaking-space characters). This feels ok on case-by-case basis…
So far my only routine “clean up on import” is to look for multi-author / multi-editor fields that separate with commas between names (rather than semicolon or and), because getting a function to parse the three comma-separated names in Gavin Van Horn, Robin Wall Kimmerer, John Hausdoerffer (a real editor list as it appears on at least one of my books) — while also preserving the ability to recognize Lastname, Firstname strings! — is a nightmare I’d rather postpone indefinitely.)
I have not yet tackled the single-name Plato problem (beyond pasting in a zero-width first initial), and of course I should solve that next, given my field! I’m much less worried about merely honorific titles (Dr., Lady), since if they’re not part of the actual name, they can be deleted without harm to the bibliographic integrity of the record. Deleting the Dr. from Dr. Martin Luther King, Jr. (if I ever found an imported record that specifies the author that way) is arguably not dropping any part of the name, while dropping the Jr. would be doing damage to the integrity of the name data.
Another problem I haven’t begun to consider is how an author tiddler (a real tiddler, not just a virtual template!) could leverage an alias field (and then use template to draw seamlessly on associated data) so that someone who published under multiple names (especially multiple last names) could have all their work showing up at one node (or even better, all their work showing up at each of the two or more named nodes).
Are you doing this clean up before you import the record into TW or afterward?
Again, I don’t know your workflow, nor have I ever worked with bibtex, but if you’re usually importing at most a handful of entries, I can easily imagine (and no, I don’t know how to do it) an interception of the import process, that lets you correct the best automated guesses, perhaps something like this:
Of course, if you’re doing bulk imports, this is impractical.
Would you expect this to also handle the Martha C. Nussbaum / Nussbaum, Martha issues?
No! Resorting to adding an alias field to a tiddler for an author (where author-tiddlers are optional, given the informative virtual-tiddler template) would be needed only in the genuinely rare marginal cases where we learn that an author who published under multiple names (say, a writer changed her name mid-career), or the author also turns out to have had a pseudonym (Stephen King also published under pseudonym Richard Bachman).
I’m often importing more than a handful! And I can imagine all kinds of workflows and data structures… It’s true that any institutional biblio solution will prefer to clean and polish on the front end, and a “heavy” solution can afford to devote labor to the process of imposing its data-structure priorities.
But having separate first-middle-last-suffix fields (multiplied by indefinitely many N authors!) is anathema for working seamlessly with existing bibtex records. (And that standard bibtex array of fields is also the premise of the refnotes plugin by @mohammad, to which I want to offer added value without setting up conflicts.) Google scholar, for example, gives us
@book{van2021kinship,
title={Kinship: Belonging in a world of relations},
author={Van Horn, Gavin and Kimmerer, Robin Wall and Hausdoerffer, John},
year={2021},
publisher={Center for Humans and Nature}
}
I think an academic biblio database ought to have zero speedbump for batch-importing such records — individual attention should not be required (except of course to correct substantive errors noticed).
Consider also that best practices should preserve the ease of exporting into a zotero or endnote system via that same bibtex standard, with its single field for “author”, single field for “editor”.
For such reasons, I think it’s better to have smart parsing on the fly, within TiddlyWiki, as needed. The one standardization that I might nudge toward is Lastname, Firstname [other bits] name structure, since most bibtex records do fit this norm. But being able to parse Firstname M. Lastname, Jr. even before cleanup — if it’s possible — just feels like the elegant thing to do.
In sum, my project here to offer a responsive user-friendly community edition that “just works” for a decently wide range of name-order conventions a user might implement or inherit, but all within a bibtex eco-system where a single “author” field is the norm.
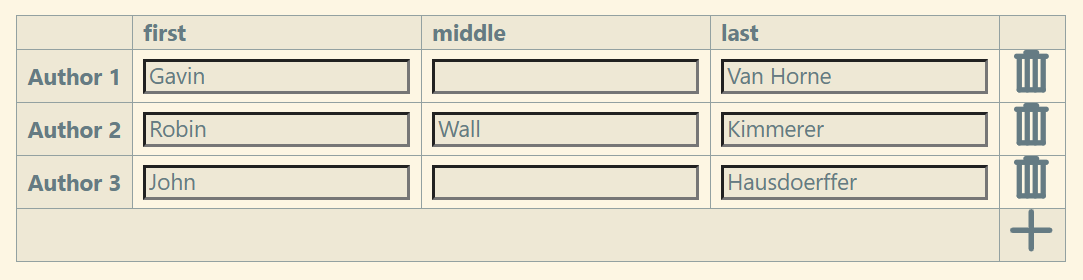
Ok, that make sense. I’m still not clear if your notion of clean-up would allow you to alter the bibtex-author field, though. Although I pictured it on bibtex load, the same thing could be offered on any visit to the citation tiddler, with the idea that, as best we can, we end up with
bibtex-author: Van Horn, Gavin; Kimmerer, Robin Wall; Hasudoerffer, John
so that you can then render (a more sophisticated version of) this:
<<list-links filter:"[{!!bibtex-author}split[; ]]" >>
to get something like this:
In other words, those intermediary fields in the mock-up would be used only to verify or correct the system-parsed breakdown of the name. In the end, they would remain in the bibtex style.
But I don’t know if that’s acceptable, or if the input must remain as presented and you just need to deal with the variations at citation render time.
Of course, yes, that’s what I mean by parsing “on the fly” rather than at import (except that it’s more complex than just semicolons, as you notice). Something like that is what I’ve steadily been building. Not altering the contents of the author field (except to swap hard non-breaking spaces into any “de la cruz” last names and such), but allowing it to link and display “intertwingularities” based on the more granular parsed content.