With respect @minjaep I think you are yet to fully understand the implications of using tiddlywiki’s markdown or wikitext standard.
As you said yourself;
It would help if first we return to seeing if we can show you how to get what you want from Wikitext, before looking for more hacky solutions. See the internals plugin below.
Well, first it is already very smart interpreting wikitext based on a long history of needs. In fact when making lists HTML demands we wrap a number of line items <li>an item in the list</li> inside a <ol><ol> or <ul></ul> the wikitext parser is doing all this work for us.
So rather than answer a question you ask I would like to share two methods that show you perhaps it is not as complex as you think.
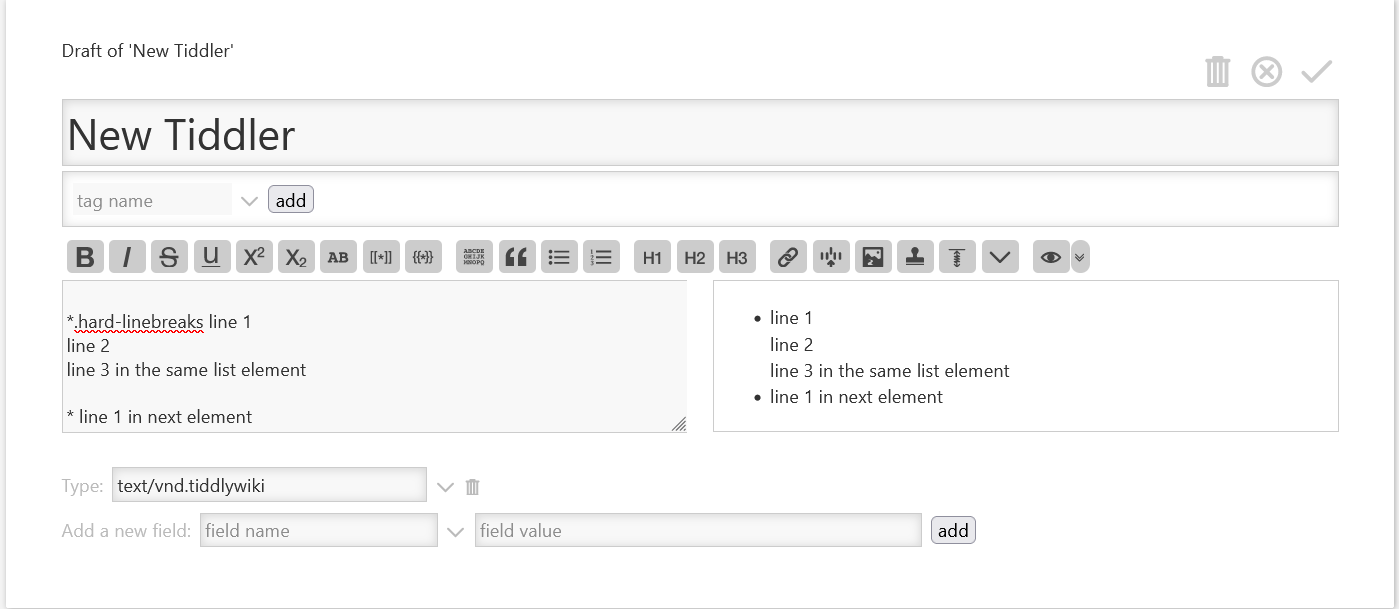
One. Most wikitext symbols like # ! * etc.. can be followed by .classname. so in a stylesheet define classname
.classname {
various css and styles
}
So you can do this
* one
*.classname two
* three
Two. Now consider the # rather than the * because we may want the numbers to continue. This illustrates how in a list we need continuity, note clear when we use <ul>.
# one<br>Second line
# two<div> Div within `<li>` </div>
# three<p>A whole paragraph</p>
# Last item after a paragraph within the last item
This is in fact demanded by logic. If you want something to be nested within something you need to somehow nest it, be it a div or otherwise, or as in my example a <br>. For something to be within a list item it must be within the tags <li>here</li>
Now all this comes about because wiki text is converted to HTML to display in the browser.
If you understand wikitext and a little of HTML , both to assist learning and deal with more complex cases I suggest installing the Internals Tool already installed on TiddlyWiki.com (or just use it there) then select the preview Raw HTML to see what is occuring. This gives you insight into what the wikitext parser does and how to get it to accommodate other html.
Side note;
I have long struggled to get the core developers to recognise we need a wikitext character to indicate a sentence, or div ie it is incorrect to use the wikitext “;” to do this and it gets bolded and a blank line follows it anyway. There should be a way to indicate an otherwise single line is a sentence (and the subsequent lines (\n) will not be wrapped up (in a paragraph) and which which we can add the .classname.
Much of this is addressed with the Custom Markup plugin, however this an not the solution here.