That come out in the wrong order … I need the order of the DD …
Just an example
TT
With pleasure:
A checklist for grammer and spelling-mistakes to avoid them in future:
$ _data_Fehleranalyse.json (1.1 KB)
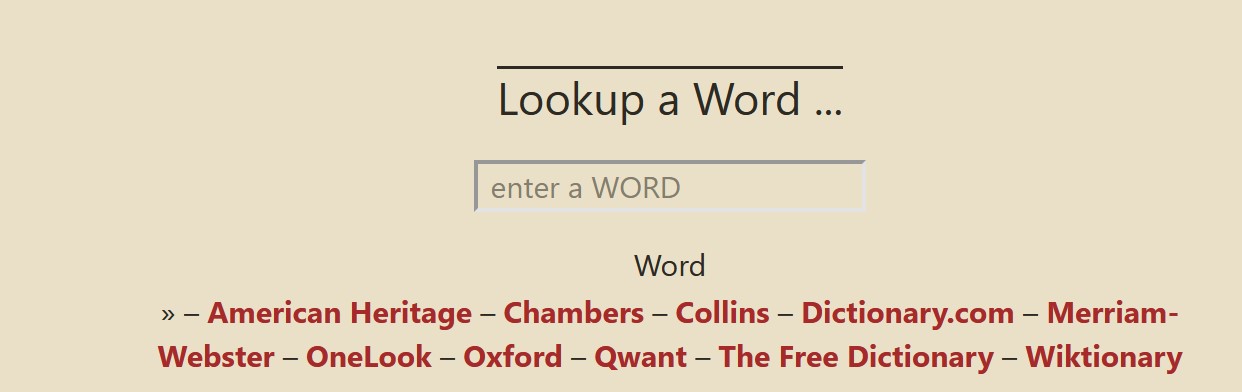
Must the non breaking spaces be there?
Perhaps they should be in the display process not the data key?
I assume you mean keys like "American Heritage"
That is no problem in data tiddlers.
I do it to prevent dictionary keys wrapping in render.
Nothing more.
TT
Which is more compact?
TT
This data only has the key but no values. Do you plan to use values? Otherwise this can just be treated as a list of titles.
A simple list output s the titles in natural order, so perhaps this is enough for you next coding step?
Here I simply extract the keys in order for your data set and @TiddlyTitch’s day, since it has values I am turning them into links
Fehleranalyse
<$list filter="[{$:/data/Fehleranalyse}splitregexp[\n]]" variable=each-line>
<$text text={{{ [<each-line>split[:]first[]] }}}/><br>
</$list>
Linkdata
<$list filter="[{Linkdata}splitregexp[\n]]" variable=each-line>
<$text text={{{ [<each-line>split[:]first[]] }}}/><br>
</$list>
<$list filter="[{Linkdata}splitregexp[\n]]" variable=each-line>
<$link to={{{ [<each-line>split[:]last[]] }}} >{{{ [<each-line>split[:]first[]] }}}</$link><br>
</$list>
.I am afraid I need to stop soon as I am tired at 9:30pm on a Sunday evening.
I attempted to turn @TiddlyTitch’s data into text (please give it in text form) it was fiddly with OCR
Linkdata.json (695 Bytes)
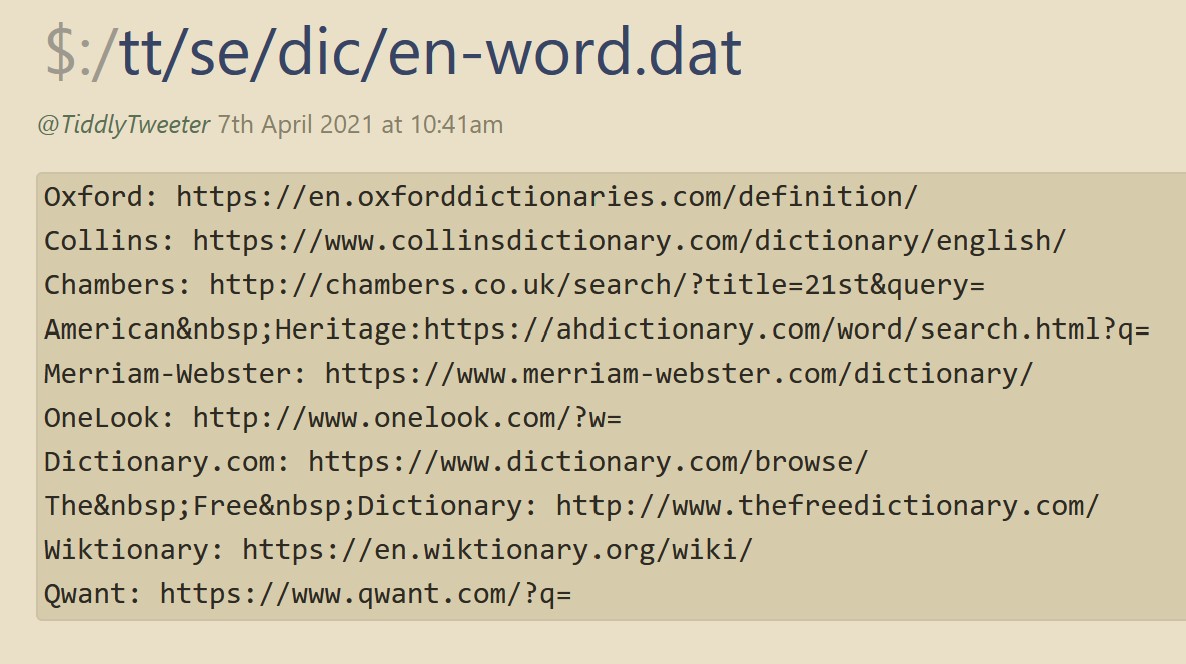
$ _tt_se_dic_en-word.dat.json (757 Bytes)
Okay. There it is.
Rename the input data from LinkData in my example.
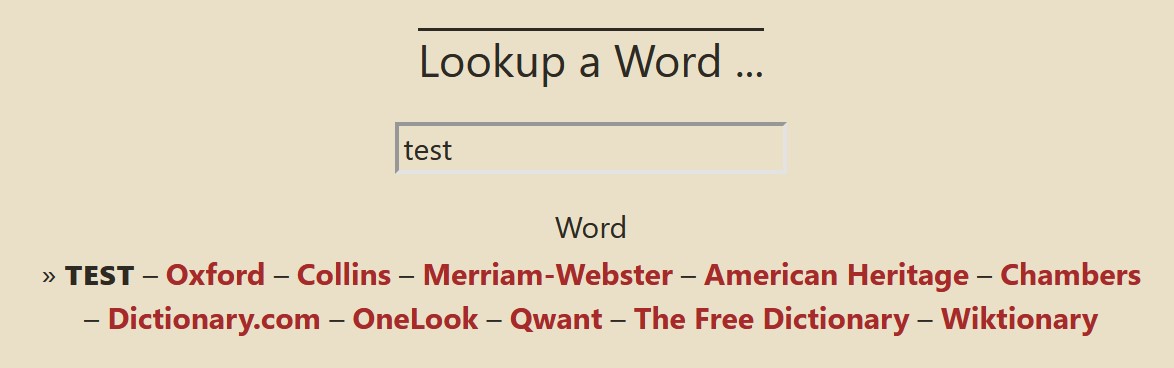
I did a proof of concept and tested with FF, Edge and windows 11 today. It looks good. That’s the easy part.
The rest of the work that has to be done is the problem.
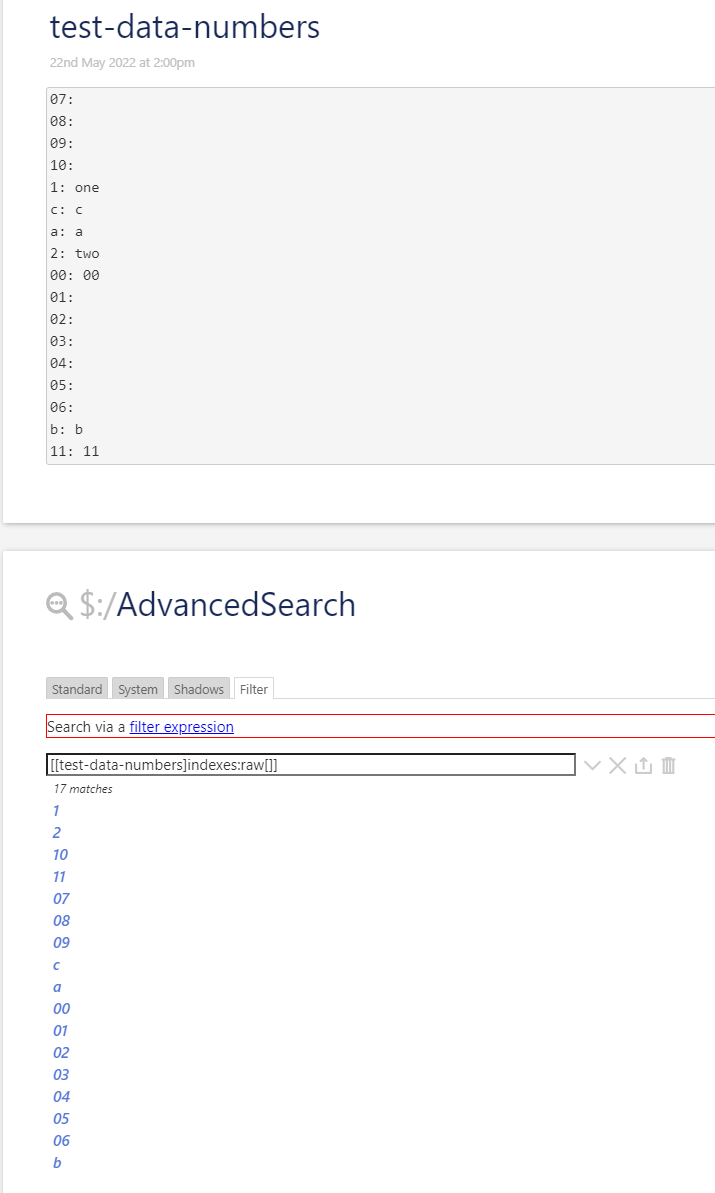
[[$:/data/Fehleranalyse]indexes:raw[]]
[tag[test]indexes:raw[]] where 2 tiddlers may be tagged “test”. The tagged tiddlers will be alphabetically sorted by default. BUT there is list-before and list-after and there is the tag list field. … Not sure how raw may or may not work as expected, if used that way.But I’m not sure if it is a waste of time because of the following behaviour. It seems to be consistent with major browsers. But ..
The “quirks” in the spec, produces “strange results”. See the screenshot. … So I’m not sure if we “should” implement it.
Do you think we can explain that behaviour, so users really understand it? … Be honest.
Initially I thought, the discussion would “dry out” after Jeremy’s comment.
But the brainstorming about a workaround did go on. … There have been some valid ideas and I think it can be solved with the wikitext functionality we have atm. … But the “work around” produces complex wikitext and filter code. .. I’m not sure.
The rules are like that:
This works fine!
The keys have no value yet because I did not have the solution you provided.
The aim is to build a table with checkboxes which set the values.
Although it’s true that modern JS engines do now have well defined behaviour around the ordering of object keys, that doesn’t extend to JSON. The JSON spec very clearly states that object keys are unordered. That matters to us because our tiddler dictionary format is just a shortcut syntax for creating a JSON object, and we’d want to have consistent behaviour for all types of data tiddlers.
In the above solution I gave which is the equivalent of raw order, parsing the data in the correct order is easy.
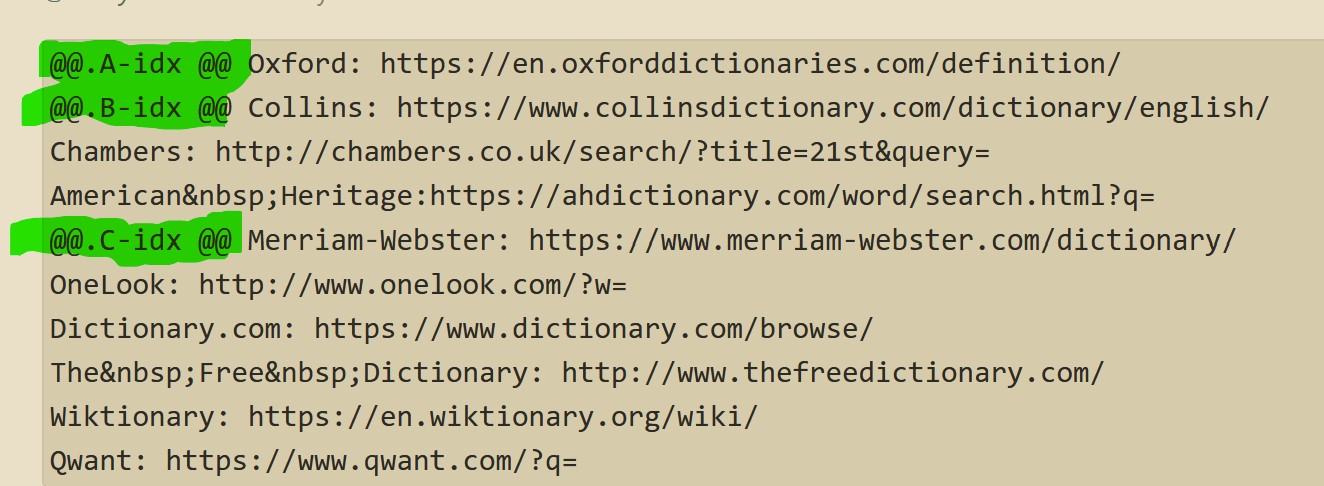
Side note: Both data samples include non alphanumeric values in the keys relating to presentation. These should be removed and handled in the presentation of the final result.
However they next step I would have taken last night had I not being so tired would be to turn the resulting “key list” into a variable (containing a list) so it can be used in other operations. This may be my own weaknesses but I think it exposes fragility in tiddlywiki features because a little gymnastics needs to be done, possibly including wikification before one can get the result into a usable form.
Perhaps a more strategic solution would be to tackle the above issue and solve other issues at the same time, leaving this “unusual” raw order as an exception with a work around to make “key lists”.
I will have a look today at using one of the filter run prefixes such as MAP and the format title list to see if a better answer is already available.
Small footnote on forcing a wanted output order from DD entries.
(This is probably a horrible kludge but worked for my minimal use case)
@@.style @@ for DD items you need exactly ordered …Test DD …
Results in what I want …
TT
@TiddlyTitch this earlier solution worked on your data as well.
Here is an example against your data, which contains the “:” delimiter in the values so needed a modified approach. Without editing the keys as you did.
<$list filter="[{$:/tt/se/dic/en-word.dat}splitregexp[\n]]" variable=each-line>
<$set name=key filter="[<each-line>split[:]first[]]">
<$set name=href value={{{ [<each-line>removeprefix<key>removeprefix[:]] }}}>
<a href=<<href>> target="_blank" ><$text text=<<key>>/> </a><br>
</$set></$set>
</$list>
Thanks! I will try it!
My issue is integrating the macro that produces the listing (stolen already ![]() ) with your solution.
) with your solution.
I just lack the competence to integrate your solution with it.
I will look at it though.
Grazie, TT
@TiddlyTitch I will also look at the display with non breaking spaces (not in the data) to fix that as well.