Hi!
Here is some code based on functions which should do the job, even though it’s certainly not very robust to malformed wikitext tables…
I was heavily inspired by previous solutions in this thread, thank you all! 
My main disappointment is I couldn’t use fancy unicode chars, because the solution relies on strings length and the result is wrong when the input contains unicode, be it with length[] or with split[]count[] filters.
<!-- Replace every cell value except ">" or "<" by "1" -->
\function fn.value-to-1()
[all[]]
:map[<currentTiddler>!regexp[>|<]then[1]else<currentTiddler>]
+[join[ ]]
\end
<!-- Counts the occurrences of "c" in string "s" -->
\function fn.nb(c,s)
[<s>split<c>count[]subtract[1]]
\end
<!-- Replaces sequences of "from" characters by "to" characters -->
\function fn.expand.cell(from,to)
[fn.nb<from>,<cell>!match[0]]
:map:flat[range<currentTiddler>]
:map[<to>]
+[join[]]
\end
<!-- Returns <<cell>> length -->
\function fn.cell.ln() [<cell>split[]count[]]
<!-- Computes current <<cell>> weight -->
\function fn.compute.cell(cell)
=[fn.expand.cell[>],[0|]]
=[fn.cell.ln[]]
=[fn.expand.cell[<],[|0]]
+[join[]]
\end
<!-- Computes current <<row>> weights -->
\function fn.compute.row(row)
=[<row>split[|]]
:map:flat[fn.compute.cell<currentTiddler>]
+[join[|]split[|]join[ ]]
\end
<!-- Sanitizes input (not perfect, but you get the idea... -->
\function fn.sanitize()
[all[]]
:map[<currentTiddler>search-replace:g[||],[|x|]]
\end
<!-- Replaces actual cell values by "1"s -->
\function fn.get.ones()
[all[]]
:map[<currentTiddler>split[|]butfirst[]butlast[]trim[]fn.value-to-1[]enlist-input:raw[]join[|]]
\end
<!-- Collapse cells (">|1" becomes ">1" -->
\function fn.collapse()
[all[]]
:map[<currentTiddler>search-replace:g[>|],[>]search-replace:g[|<],[<]]
\end
<!-- Maps a table to its colspans -->
\function row.map(table)
[<table>splitregexp[\n]]
:map[<currentTiddler>fn.sanitize[]]
:map[<currentTiddler>fn.get.ones[]]
:map[<currentTiddler>fn.collapse[]]
:map[fn.compute.row<currentTiddler>]
\end
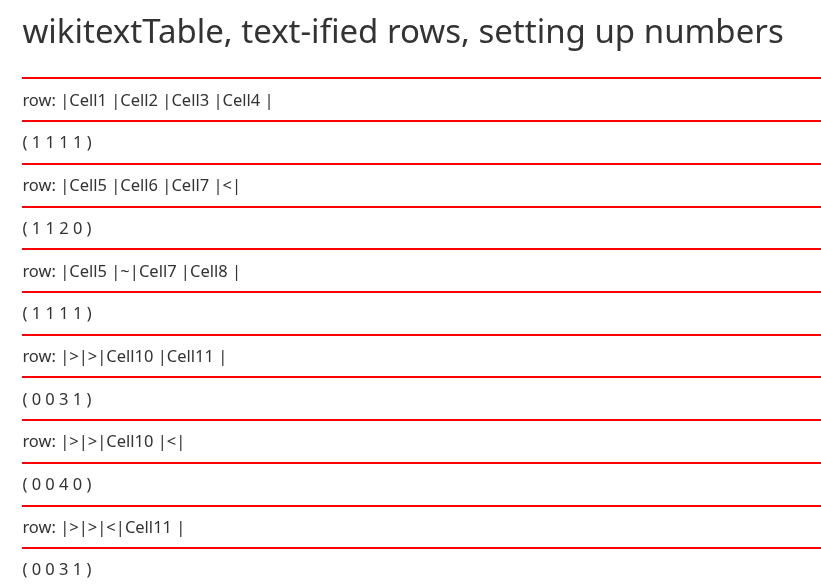
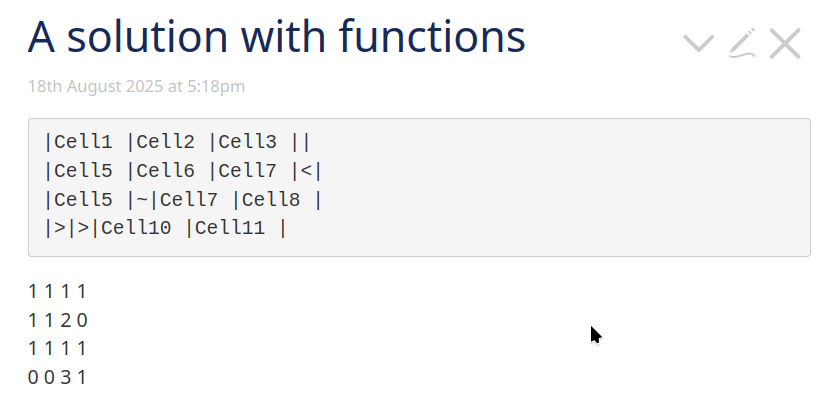
And here’s an example:
<$let table="""|Cell1 |Cell2 |Cell3 ||
|Cell5 |Cell6 |Cell7 |<|
|Cell5 |~|Cell7 |Cell8 |
|>|>|Cell10 |Cell11 |"""
>
<$list filter="[row.map<table>]">
<$text text=<<currentTiddler>>/><br>
</$list>
</$let>
A solution with functions.json (2.1 KB)
I tried to add some comments, but can explain more if asked 
Fred