I 100% agree. But others have raised it as a concern
However, the demo widget is inspiring. That sort of interactive documentation feels like it’s using the power of TW to tell about TW.

I 100% agree. But others have raised it as a concern
However, the demo widget is inspiring. That sort of interactive documentation feels like it’s using the power of TW to tell about TW.
I think this is excellent:
This and possibly some color or bold, to indicate there’s something special about it.
This would keep the immediately seen doc fully clear and readable - and the tooltips/popups allow the user to get more details on a need basis and without cluttering the immediate presentation.
How could the addition of such tooltips/popups be automated?
…and assuming it can be automated, then perhaps the full filter could even show instead of just the operand? I think beginners are often confused by how to apply things to get exactly the correct syntax, e.g
[range{!!minimum-age},{!!maximum-age}]
This is pretty much what @etardiff has accomplished in the proof-of-concept above.
I imagine it would be fairly straightforward to have a version that simply puts dummy placeholders into existing Examples (strings that don’t have an intuitive connection to the nature of the filter operator, but which show how the syntax works for the three main kinds of parameter).
Starting with a few key and vital operators, having semantically meaningful parameter names (like {!!minimum-age} and <selectedContact>) could be a follow-up step.
I think the Days of the Week tiddler is a great model. It’s a real tiddler (not just test-case) with fields that are useful for Example documentation.
I’d like to see a few more semantically intuitive tiddlers — maybe adding some non-sensitive biographical/trivia fields for JeremyRuston.  Or adding a caption field (“TiddlyWiki mascot”) and bunch of biographical details to a MotovunJack tiddler (not yet a tiddler name, despite the image and robot variants). What else? Eiffel Tower? Tardis? Esperanto? Or a tiddler for Elements and for a few sample elements… with the Elements main text field pointing people to the Periodic Table demo by @Scott_Sauyet?) I recall the demo for the Tour plugin had some tiddlers with Planets. They would also be great for having semantically meaningful fields.
Or adding a caption field (“TiddlyWiki mascot”) and bunch of biographical details to a MotovunJack tiddler (not yet a tiddler name, despite the image and robot variants). What else? Eiffel Tower? Tardis? Esperanto? Or a tiddler for Elements and for a few sample elements… with the Elements main text field pointing people to the Periodic Table demo by @Scott_Sauyet?) I recall the demo for the Tour plugin had some tiddlers with Planets. They would also be great for having semantically meaningful fields.
With an international world of learners out there, it’s hard to strike the balance of being culturally accessible with all examples, and tw-com shouldn’t be cluttered with too many extra tiddlers… But a few well-chosen ones would really allow for intuitive examples, I think!
I agree we should do our best on this, so one way of avoiding the complexities with cross cultural references is to resort to human/global and universal information. The reason I published the periodic table, Sometimes which are even common by reference to ancient languages eg Latin and Greek.
That is scientific bodies of knowledge including dinosaurs, geological epochs, mathematics, atoms/molecules, evolutionary. Although not perfect these are often where language differences are less because we all resort to a shared cannon of words.
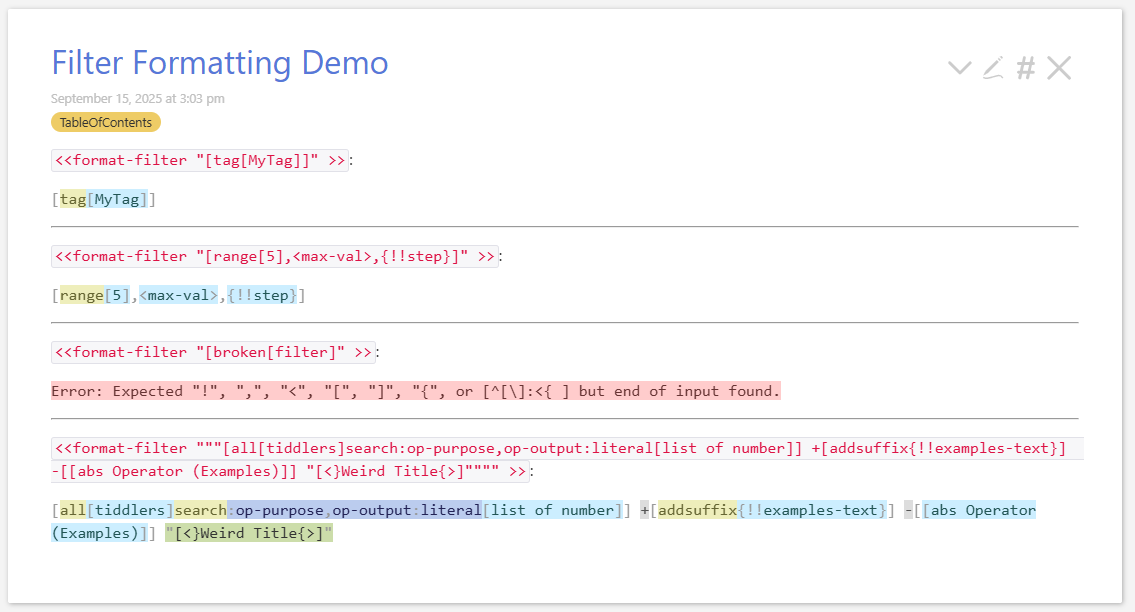
I’ve started playing around with a highlighter for filter syntax. It looks like this:
There are many different hover behaviors, which I won’t try to capture here. You can just take a look at it at http://scott.sauyet.com/Tiddlywiki/WIP/FilterFormatDemo.html. If you want to play with styles, the stylesheet can be found in the sidebar. So is the JS macro I used. You can try them in your own wiki using: FilterFormatDemo.json (50.8 KB)
This is all throw-away, proof-of-concept code. I wouldn’t expect to keep a line of it for a production implementation. I’ll discuss it more below, but the main question is, would something like this be useful for the docs site, to be used wherever we demonstrate filters?
I built this atop a Parser Expression Grammar (PEG) that I wrote custom for this, using the dingus from Peggy.js. This allows us to write declarative descriptions of expressions in our grammar alongside JS code to generate a result, in this case an Abstract Syntax Tree (AST). Tiddlywiki already has a function to do this, $tw.util.parseExpression, but the tree it generated seemed to me to lack details I wanted to have. I would definitely revisit this choice. But even better would be to incorporate the Highlight Plugin, and add a mode for our filters. I don’t know precisely how to do this, but if we go this route, that would seem most likely.
The PEG grammar I used looks like this:
Filter
= _ head:Run tail:(_ Run)* _
{return [head, ...tail.map(e => e[1])]}
Run
= PrefixRun
/ StaticRun
PrefixRun
= prefix:Prefix run:FilterRun
{return {prefix, run}}
/ run: FilterRun
{return {prefix: '', run}}
StaticRun
= "\"" chars: [^"]* "\""
{ return {prefix: '', run: {steps: [{text: chars.join('').trim(), quotes: '"'}]}}; }
/ "'" chars: [^']* "'"
{ return {prefix: '', run: {steps: [{text: chars.join('').trim(), quotes:"'"}]}}; }
/ chars: [^'"\[]+
{ return {prefix: '', run: {steps: [{text: chars.join('').trim(), quotes: ''}]}}; }
Prefix
= NamedPrefix
/ ShortcutPrefix
NamedPrefix
= ":all" / ":and" / ":cascade" / ":else" / ":except" / ":filter"
/ ":intersection" / ":map" / ":or" / ":reduce" / ":sort" / ":then"
ShortcutPrefix
= "+" / "-" / "~" / "="
FilterRun
= "[" steps:FilterSteps "]"
{return {steps}}
FilterSteps
= head:FilterStep tail:(_ FilterStep)*
{return [head, ...tail.map(e => e[1])]}
FilterStep
= negated: ("!")? op:Operator suffixes:Suffixes? params:Params?
{return {negated: !!negated, op, suffixes: suffixes || [], params: params || []}}
/ negated: ("!")? params:Params
{return {negated: !!negated, op: '', params: params || []}}
Suffixes
= head:Suffix tail:(Suffix)*
{return [head, ...tail]}
Suffix
= ":" name:[^:\[\{\< ]+
{return {parts: name.join('').split(',')}}
/ ":"
{return {parts: [""]}}
Params
= head:Param tail:("," Param)*
{return [head, ...tail.map(e => e[1])]}
Param
= "[" hard:[^\]]+ "]"
{return {type: 'hard', text: hard.join('')}}
/ "{" textRef:[^!}]+ "}"
{return {type: 'textRef', tiddler: textRef.join('')}}
/ "{" textRef:[^!}]+ "!!" field:[^}]+ "}"
{return {type: 'textRef', tiddler: textRef.join(''), field: field.join('')}}
/ "{" "!!" field:[^}]+ "}"
{return {type: 'textRef', field: field.join('')}}
/ "<" varRef:[^<>]+ ">"
{return {type: 'varRef', text: varRef.join('')}}
Operator
= op: [^\[\]\:\<\{ ]+
{return op.join('')}
_ "whitespace"
= [ \t\n\r]*
This gets turned into JS parsing code, which is included in that macro.
For the filter [range[5],<max-val>,{!!step}] -[[20]] +[[9999]], this generates the tree:
[
{
prefix: '',
run: {
steps: [
{
negated: false,
op: 'range',
suffixes: [],
params: [
{
type: 'hard',
text: '5'
},
{
type: 'varRef',
text: 'max-val'
},
{
type: 'textRef',
field: 'step'
}
]
}
]
}
},
{
prefix: '-',
run: {
steps: [
{
negated: false,
op: '',
params: [
{
type: 'hard',
text: '20'
}
]
}
]
}
},
{
prefix: '+',
run: {
steps: [
{
negated: false,
op: '',
params: [
{
type: 'hard',
text: '9999'
}
]
}
]
}
}
]
That is then passed to some custom code, which converts that to the following HTML (without all the indentation and other white space):
<tt class="filter">
<span class="complex run">
<span class="punc sq-bracket">[</span>
<span class="step">
<span class="operator">range</span>
<span class="param">
<span class="punc sq-bracket">[</span>
5
<span class="punc sq-bracket">]</span>
</span>
<span class="punc comma">,</span>
<span class="param">
<span class="punc ang-bracket"><</span>
max-val
<span class="punc ang-bracket">></span>
</span>
<span class="punc comma">,</span>
<span class="param">
<span class="punc curly-bracket">{</span>
<span class="punc bangs">!!</span>
<span class="field">step</span>
<span class="punc curly-bracket">}</span>
</span>
</span>
<span class="punc sq-bracket">]</span>
</span>
<span class="prefix">-</span>
<span class="complex run">
<span class="punc sq-bracket">[</span>
<span class="step">
<span class="operator"></span>
<span class="param">
<span class="punc sq-bracket">[</span>
20
<span class="punc sq-bracket">]</span>
</span>
</span>
<span class="punc sq-bracket">]</span>
</span>
<span class="plain run"><span class="step">+</span>
</span>
<span class="complex run">
<span class="punc sq-bracket">[</span>
<span class="step">
<span class="operator"></span>
<span class="param">
<span class="punc sq-bracket">[</span>
9999
<span class="punc sq-bracket">]</span>
</span>
</span>
<span class="punc sq-bracket">]</span>
</span>
</tt>
Creating a module from this is just a matter of properly combining the parser generated by PEG alongside the AST->HTML code, and wrapping it in at HTML module,
Again, note that this is not production-ready, not even close. It’s a quickly hacked-together tool meant only to show the idea. But please play with it.
Interesting demo Scott
Your example could help the debugging process.
I wonder if it could ever be possible to parse a filter into a plain language representation ?
eg [tag[example]has:field[caption]]
list all tiddlers (without shadows) with the tag example and has the field caption (even if empty) dominatly appended.
[tag[example]] [has:field[caption]]
list all tiddlers (without shadows) with the tag example and also;
list all tiddlers (without shadows) that have the field caption (even if empty) and dominatly appended.
It might be possible to start building that out of the information that’s in the main site (op-purpose might help, for instance), but only for filters all of whose operators are built-in ones. Custom operators would need some convention we could use to document them.
It would take changes to the core, though, to incorporate any such information into regular wikis.
And worse, there would be substantial complications for suffixes and for operators that have very different behaviors depending upon the number of parameters they take, such as this thread’s pet operator, range.
Why do you think this? I am just thinking of an extension to the documentation, a plugin even. one has to intentionally give the filter to it like your syntax.
Perhaps an LLM could help but I still believe in systematic analysis.
perhaps we start with a collection of working found and submitted filters, with a community effort to provide one or more translations. it could be a kind of game.
You’re right. This could be a plug-in. But it would need to capture the information about each operator as stored now in the main site.
Could one use an LLM for this? Yes, although finding/creating enough training data would be difficult. Could you trust the results? No, not at all. The amount of confident bullshit that these tools generate is overwhelming.
While I’d love to be proven wrong, I also am sceptical about your crowd-sourced suggestion. I don’t think coming up with suggested filter explanations is the hard part. I think the hard part is choosing between competing texts and synthesizing the results.
As I understand it the confident bullshit comes from crawling the whole internet, along with the way it is “digested” and trust me there is a lot of bullshit. I am talking about training an LLM on 100% verified content. I understand this is being done, such as for dedicated code LLM’s and others.
This would be a helpful intermediate result and bring to the for the way people conceptualise filters, which is something we dont have much insight to. It would in effect be;
[tags[]!is[system]has[title]has[caption]] "List all non-system tags, the tag has a tiddler and that tag tiddler contains a non-blank caption[tags[]!is[system]has[caption]] as it cant have a caption unless it has a tiddler anywayOnly if one had a large set of submissions could it then be used to train an LLM.
I absolutely agree on this. But I would expect to use hand-crafted descriptions.
I am a programmer who very much likes working on big ideas. But the best syntax explainers I’ve seen don’t ever get close to the level of your examples.
As an alternative, I wonder if we might be able to programmatically create useful diagrams of filters, which simply link to the operators’ tiddlers on the main site. Think of diagramming sentences in school. That could be automated in a straightforward manner.
I’m reconsidering my stance on this.
I realize that this is possible. It’s still a lot of work. But the way I would see it working is with templates of some sort for each operator, as well as for the different kinds of parameter and the different run prefixes. I don’t see this being based on a great number of examples, LLM approach, but instead, based on parsed output and templates, the way my recent example parsed to an AST and then used templates to format it as HTML.
It sounds interesting, but not interesting enough that I’m likely to work on it soon.
I do apologize that my first response was so dismissive. It took a while for the possibilities to sink in.
Very interesting – is it all in wikitext?
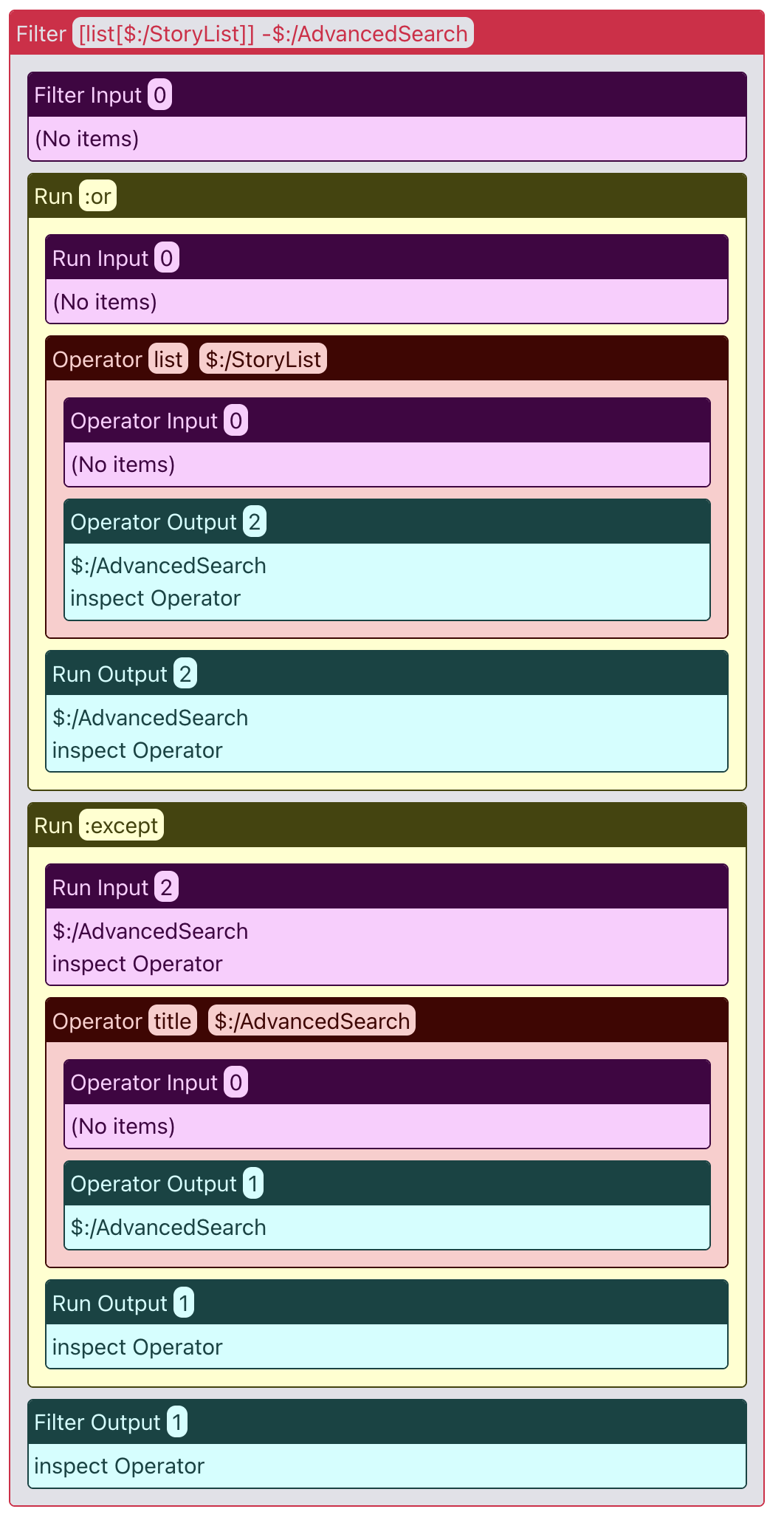
A few months ago I started experimenting with a filter visualiser. As well as showing the filter steps it also shows the intermediate results:
There is a preview build here:
It’s not a priority for me to work on this at the moment, but there are some low level operators there that might be useful for other kinds of visualisation.
No, not at all. I wouldn’t know how to begin parsing a filter expression with wikitext. In fact, the output from $tw.utils.parseFilter did not have enough detail for me, so I wrote my own using a PEG parser. But that’s meant to be discarded eventually.
I just created a GH issue to see if the core team is interested in this idea.
Elsewhere in this thread @TW_Tones and I were discussing this idea. And your screenshots look very much like I was thinking. I had thought only of static analysis and not live demonstration of filter step results. That moves the tool beyond my documentation focus into much more general usefulness. Netlify is blocked at GigantiCorp1, so I can’t look at it now, and this evening is probably overbooked, but I look forward to trying it soon!
1 I wonder if we could set things up so that https://deploy-preview-9003--tiddlywiki-previews.netlify.app/ is served also as https://demos.tiddlywiki.com/deploy-preview-9003 or evem https://deply-preview-9003--demos.tiddlywiki.com?
It looks as though this is possible, although the URL would probably have to look like https://deply-preview-9003.demos.tiddlywiki.com, with netlify managing the subdomain demos. And I have no idea if the GH action makes it easy to change the default name.