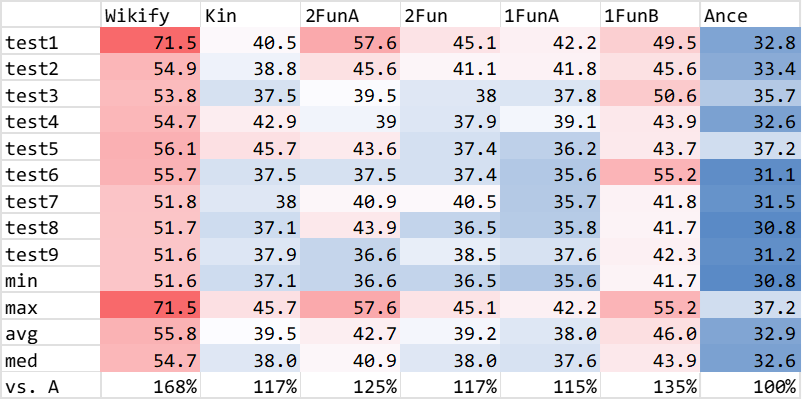
The design is in your hands @Yaisog. My outline previous is primarily for clarity and for future readers. Hopefully it provides clarity to you as well.
The depth feature would be great, for a range of applications, both for its efficiency and even it overall simplicity compared to @saqimtiaz brilliant use of two functions.
I support your approach to the parameters in the example you give, however I still see it it could be even more general. I am not necessarily saying you should change your approach, but I want it to be clear even if I overstate it.
As I understand in your current proposed filters they will receive a title and look for that title in the (list) field or tags named? It will do this recursively and depth first, by default all tiddlers in that “tree”.
- This is of great advantage to designers within TiddlyWiki script because it roles the recursion into a filter operator.
- We can see how given the parameters your operators are given they will produce the equivalent to a filter to walk the tree.
- This is most likely much more performant.
Questions
Effective field
There are cases where the related tiddlers (Children or Parents) can be found listed in the current tiddler, or cases where the current tiddler is listed in other tiddlers fields.
- Will your operators allow both these these cases?
Using any filter
If we write a procedure that calls a second “each item” procedure we can write a recursive procedure. In this case however we can give any filter that is used both for the root and walking the tree. This filter can be any valid filter, for example we may be able to iterate a tree based on backlinks for example. But we do need to add loop protection.
- Can you see us writing a similar operator to walk the tree based on an arbitrary filter as above?.
- This would allow a comprehensive and general solution.
When loops are found
When a loop is encountered clearly the process needs to stop iterating otherwise it gets into a loop. Perhaps there are two ways I can see to handle this;
- The operators could exclude the “offending title” altogether,
- or add it to the output, as a duplicate entry but not iterate it further.
There are pros and cons about both approaches, but the second may be the only way to find and identify such cases, and possibly handle them differently, what are your/anyones thoughts?