All other details about the table, I’d keep in the text field for the “table”.
As JSON data (I.e. maintained with edit field using “index” instead of field.
So definition details about the table and the columns, the columns being the fields.
The values in those fields being default values.
Then the “table” tiddler would be the template for new “rows”. Whatever applies to the tiddler and not the rows, I’d alter accordingly for the new row.
I have a new release out, 0.2.1. It has two main changes:
With help from @saqimtiaz and @springer, I was able to add virtual tiddlers for countries. Now various other tiddlers link to missing tiddlers, which are handled by a simple template, and list the suppliers and customers addressed in the country.
Based on a discussion with @Charlie_Veniot and @etardiff, I have come to a better handling of column names, using the Tag Tiddler to store some minor metadata.
<!-- List all company name from Supplier records -->
<$list filter="[tag[Supplier]]" variable="company-name">
<!-- Get supplier company id from current company name -->
<$let company-id={{{ [<company-name>get[id]] }}} >
<!-- Get all product name having a supplier id matching current company id -->
<$list filter="[tag[Product]] :filter[get[supplier-id]match<company-id>]" variable="product-name" />
</$let>
</$list>
I was looking at the very same example for the same reason, and definitely want to improve it, but have been vacillating on using the SQL names or their aliases (S and P). I will definitely fix this in some manner!
All these examples will eventually have significant explanatory text. I’m pretty sure I would rather that such explanations end up there than in comments, but I’ll see once I start writing that content.
Thank you very much for your contributions!
That is the main goal. A secondary goal is to help me organize my own thinking and my own practices for a certain kind of wiki. And I suppose a tertiary goal is as always to learn more TW techniques.
Beyond SQL, TiddlyWiki can also be converted into a graph database(That is, a triplet.). Strings are replaced with identifiers, and relationships between these identifiers are generated. This allows tiddler data to be added outside of tiddlers, and enables the programmatic generation of virtual fields.
A tiddler would be the subject eg; Alice
A field would be the predicate eg; Married
A field value/title would be the object eg; Bob
We could permit multiple values
Bob may or may not yet exist.
In this case when referring back to SQL the Married field would be a column containing one or more foreign keys.
Bob can find who his wife is by finding his name (title) named in the married field of Alice.
Then if we wanted to record additional information for the Alice/married/Bob relationship we can create a title (even if a missing title) in the married tiddler [[Alice/married/Bob]] or [[Alice/married/start/end/Bob]]
All relationships can be found searching for example titles with the [prefix[Alice/]] AND/OR [[suffix[/Alice]]
I Call this out as an SQL that can handle this form of relationship would be great.
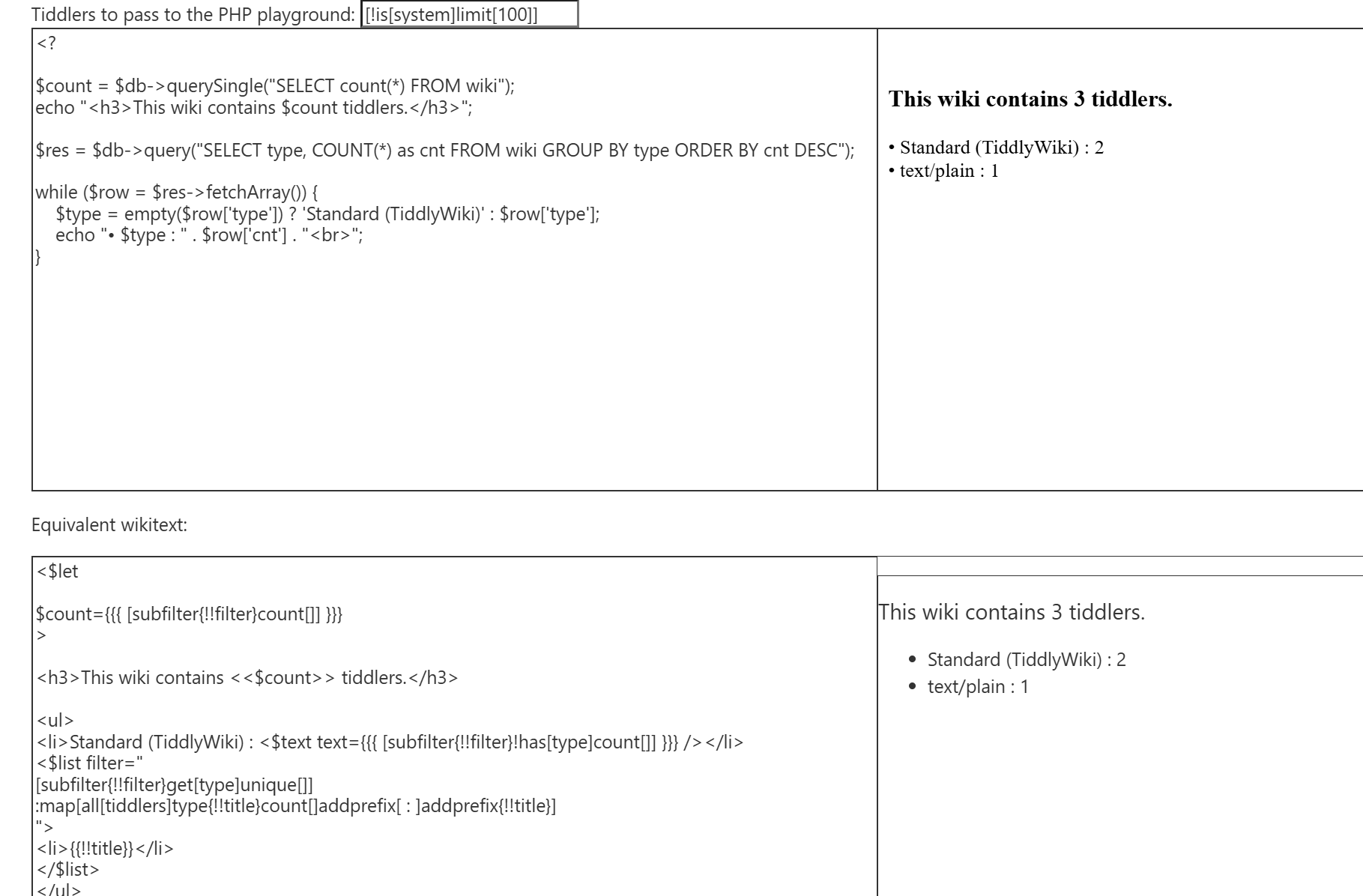
That’s a great ressource! FYI, if you want to do the reverse (use SQL to get tiddlers instead of using wikitext filters), you can use php-wasm. That way, the examples would work both ways
This is absolutely fascinating. My PHP days are long ago, but I guess it’s still clear enough what’s going on. And clearly if we wanted to, we could do something similar to your list of inserts of all non-system tiddlers with some dynamic lists of fields from our data tiddlers. I don’t know how practical this all is, but it’s incredibly impressive!
I moved a number of posts from here to the new topic Approaches to SQL. If you’ve been following the slightly contentious debate between @TW_Tones and me, you can find follow-ups there.
FYI: The New CodeMirror 6 TiddlyWiki5 plugin includes new tiddler types application/x-sql and text/x-sql and syntax checking that could help with SQL in TiddlyWiki